 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTALENT: A Tabular Analytics and Learning Toolbox
Jul 04, 2024
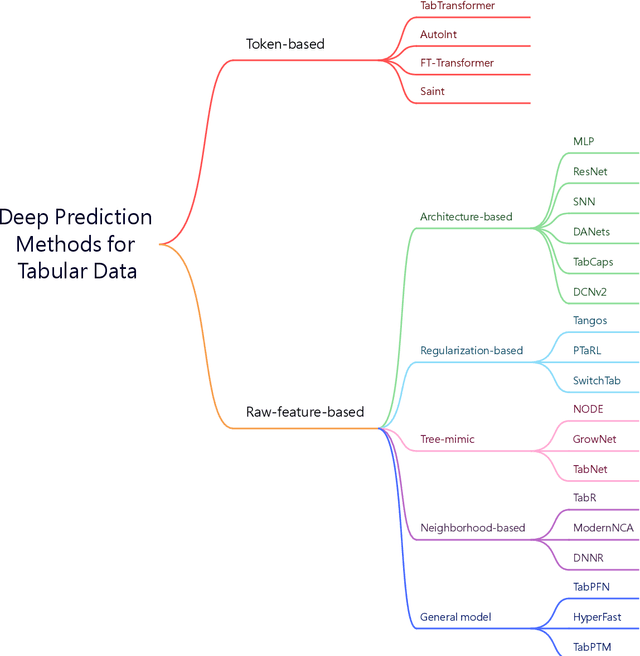
Tabular data is one of the most common data sources in machine learning. Although a wide range of classical methods demonstrate practical utilities in this field, deep learning methods on tabular data are becoming promising alternatives due to their flexibility and ability to capture complex interactions within the data. Considering that deep tabular methods have diverse design philosophies, including the ways they handle features, design learning objectives, and construct model architectures, we introduce a versatile deep-learning toolbox called TALENT (Tabular Analytics and LEarNing Toolbox) to utilize, analyze, and compare tabular methods. TALENT encompasses an extensive collection of more than 20 deep tabular prediction methods, associated with various encoding and normalization modules, and provides a unified interface that is easily integrable with new methods as they emerge. In this paper, we present the design and functionality of the toolbox, illustrate its practical application through several case studies, and investigate the performance of various methods fairly based on our toolbox. Code is available at https://github.com/qile2000/LAMDA-TALENT.
A Closer Look at Deep Learning on Tabular Data
Jul 01, 2024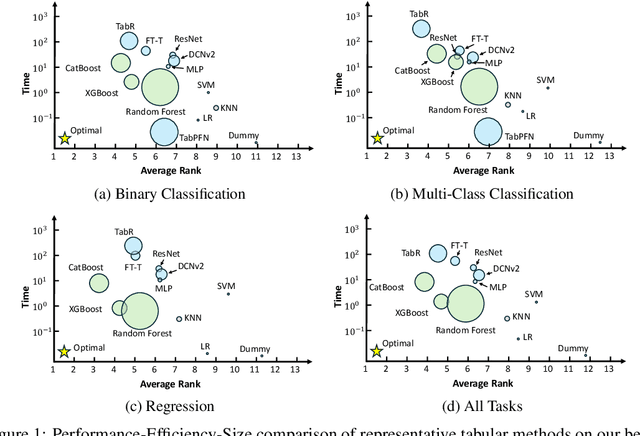
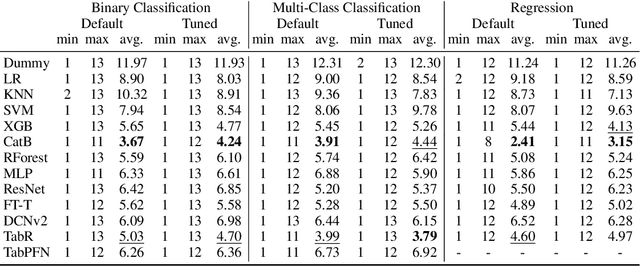
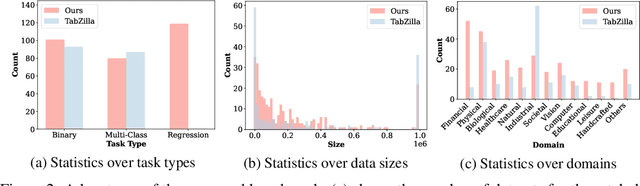
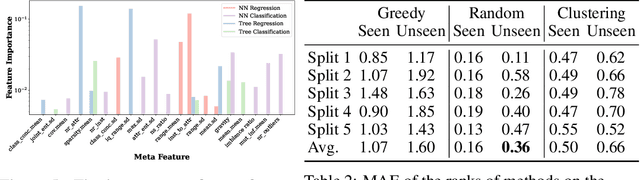
Tabular data is prevalent across various domains in machine learning. Although Deep Neural Network (DNN)-based methods have shown promising performance comparable to tree-based ones, in-depth evaluation of these methods is challenging due to varying performance ranks across diverse datasets. In this paper, we propose a comprehensive benchmark comprising 300 tabular datasets, covering a wide range of task types, size distributions, and domains. We perform an extensive comparison between state-of-the-art deep tabular methods and tree-based methods, revealing the average rank of all methods and highlighting the key factors that influence the success of deep tabular methods. Next, we analyze deep tabular methods based on their training dynamics, including changes in validation metrics and other statistics. For each dataset-method pair, we learn a mapping from both the meta-features of datasets and the first part of the validation curve to the final validation set performance and even the evolution of validation curves. This mapping extracts essential meta-features that influence prediction accuracy, helping the analysis of tabular methods from novel aspects. Based on the performance of all methods on this large benchmark, we identify two subsets of 45 datasets each. The first subset contains datasets that favor either tree-based methods or DNN-based methods, serving as effective analysis tools to evaluate strategies (e.g., attribute encoding strategies) for improving deep tabular models. The second subset contains datasets where the ranks of methods are consistent with the overall benchmark, acting as a probe for tabular analysis. These ``tiny tabular benchmarks'' will facilitate further studies on tabular data.
Training-Free Generalization on Heterogeneous Tabular Data via Meta-Representation
Oct 31, 2023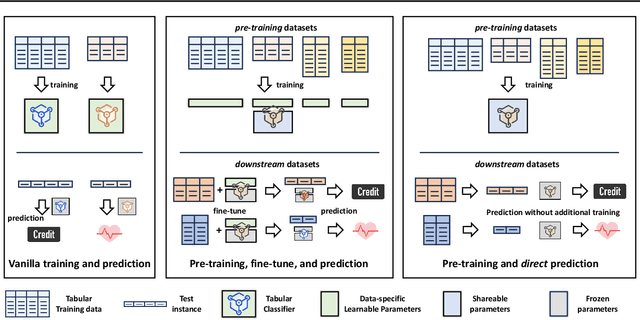
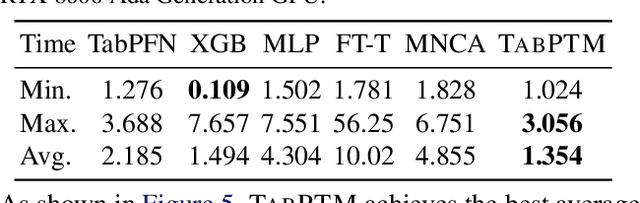
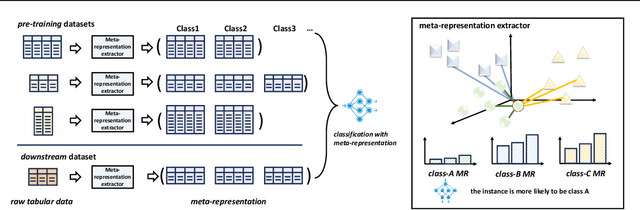
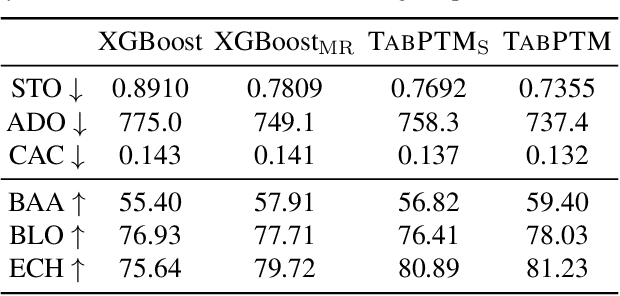
Tabular data is prevalent across various machine learning domains. Yet, the inherent heterogeneities in attribute and class spaces across different tabular datasets hinder the effective sharing of knowledge, limiting a tabular model to benefit from other datasets. In this paper, we propose Tabular data Pre-Training via Meta-representation (TabPTM), which allows one tabular model pre-training on a set of heterogeneous datasets. Then, this pre-trained model can be directly applied to unseen datasets that have diverse attributes and classes without additional training. Specifically, TabPTM represents an instance through its distance to a fixed number of prototypes, thereby standardizing heterogeneous tabular datasets. A deep neural network is then trained to associate these meta-representations with dataset-specific classification confidences, endowing TabPTM with the ability of training-free generalization. Experiments validate that TabPTM achieves promising performance in new datasets, even under few-shot scenarios.
Unlocking the Transferability of Tokens in Deep Models for Tabular Data
Oct 23, 2023



Fine-tuning a pre-trained deep neural network has become a successful paradigm in various machine learning tasks. However, such a paradigm becomes particularly challenging with tabular data when there are discrepancies between the feature sets of pre-trained models and the target tasks. In this paper, we propose TabToken, a method aims at enhancing the quality of feature tokens (i.e., embeddings of tabular features). TabToken allows for the utilization of pre-trained models when the upstream and downstream tasks share overlapping features, facilitating model fine-tuning even with limited training examples. Specifically, we introduce a contrastive objective that regularizes the tokens, capturing the semantics within and across features. During the pre-training stage, the tokens are learned jointly with top-layer deep models such as transformer. In the downstream task, tokens of the shared features are kept fixed while TabToken efficiently fine-tunes the remaining parts of the model. TabToken not only enables knowledge transfer from a pre-trained model to tasks with heterogeneous features, but also enhances the discriminative ability of deep tabular models in standard classification and regression tasks.