 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Generalization on Heterogeneous Tabular Data via Meta-Representation
Paper and Code
Oct 31, 2023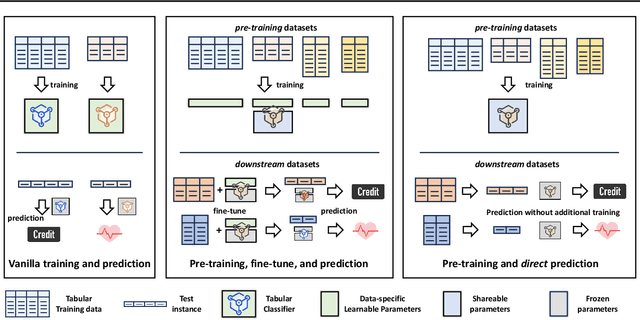
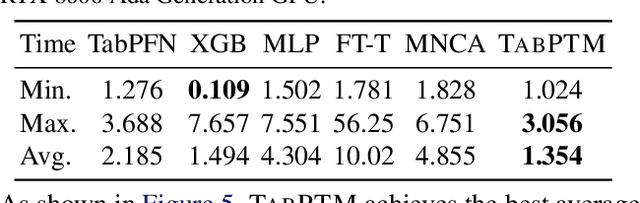
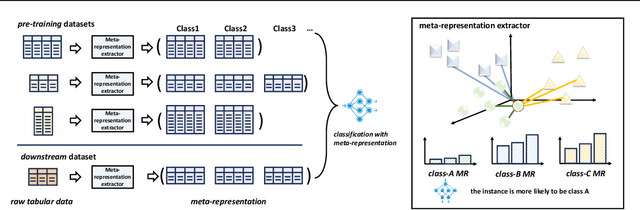
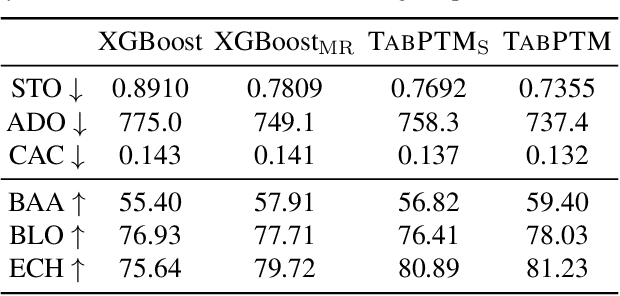
Tabular data is prevalent across various machine learning domains. Yet, the inherent heterogeneities in attribute and class spaces across different tabular datasets hinder the effective sharing of knowledge, limiting a tabular model to benefit from other datasets. In this paper, we propose Tabular data Pre-Training via Meta-representation (TabPTM), which allows one tabular model pre-training on a set of heterogeneous datasets. Then, this pre-trained model can be directly applied to unseen datasets that have diverse attributes and classes without additional training. Specifically, TabPTM represents an instance through its distance to a fixed number of prototypes, thereby standardizing heterogeneous tabular datasets. A deep neural network is then trained to associate these meta-representations with dataset-specific classification confidences, endowing TabPTM with the ability of training-free generalization. Experiments validate that TabPTM achieves promising performance in new datasets, even under few-shot scenarios.