 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Deep Learning on Tabular Data
Paper and Code
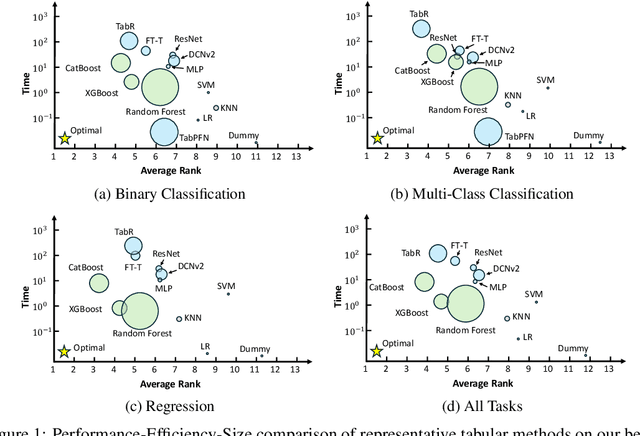
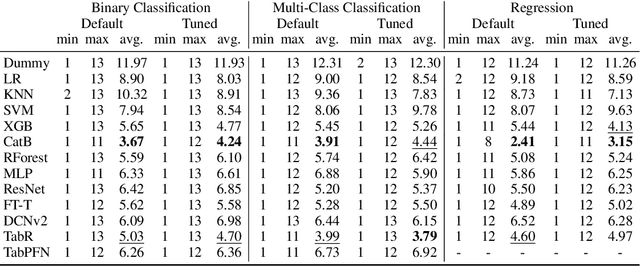
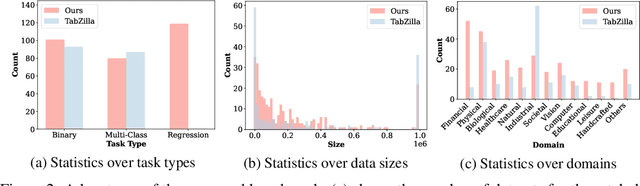
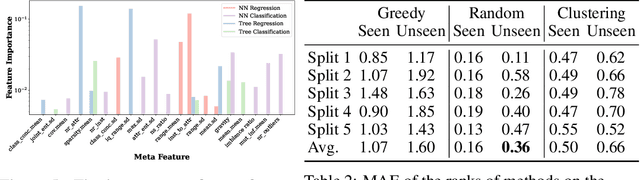
Tabular data is prevalent across various domains in machine learning. Although Deep Neural Network (DNN)-based methods have shown promising performance comparable to tree-based ones, in-depth evaluation of these methods is challenging due to varying performance ranks across diverse datasets. In this paper, we propose a comprehensive benchmark comprising 300 tabular datasets, covering a wide range of task types, size distributions, and domains. We perform an extensive comparison between state-of-the-art deep tabular methods and tree-based methods, revealing the average rank of all methods and highlighting the key factors that influence the success of deep tabular methods. Next, we analyze deep tabular methods based on their training dynamics, including changes in validation metrics and other statistics. For each dataset-method pair, we learn a mapping from both the meta-features of datasets and the first part of the validation curve to the final validation set performance and even the evolution of validation curves. This mapping extracts essential meta-features that influence prediction accuracy, helping the analysis of tabular methods from novel aspects. Based on the performance of all methods on this large benchmark, we identify two subsets of 45 datasets each. The first subset contains datasets that favor either tree-based methods or DNN-based methods, serving as effective analysis tools to evaluate strategies (e.g., attribute encoding strategies) for improving deep tabular models. The second subset contains datasets where the ranks of methods are consistent with the overall benchmark, acting as a probe for tabular analysis. These ``tiny tabular benchmarks'' will facilitate further studies on tabular data.