 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSTCS: Dual-Student Teacher Framework with Segment Anything Model for Semi-Supervised Pubic Symphysis Fetal Head Segmentation
Jan 27, 2026Segmentation of the pubic symphysis and fetal head (PSFH) is a critical procedure in intrapartum monitoring and is essential for evaluating labor progression and identifying potential delivery complications. However, achieving accurate segmentation remains a significant challenge due to class imbalance, ambiguous boundaries, and noise interference in ultrasound images, compounded by the scarcity of high-quality annotated data. Current research on PSFH segmentation predominantly relies on CNN and Transformer architectures, leaving the potential of more powerful models underexplored. In this work, we propose a Dual-Student and Teacher framework combining CNN and SAM (DSTCS), which integrates the Segment Anything Model (SAM) into a dual student-teacher architecture. A cooperative learning mechanism between the CNN and SAM branches significantly improves segmentation accuracy. The proposed scheme also incorporates a specialized data augmentation strategy optimized for boundary processing and a novel loss function. Extensive experiments on the MICCAI 2023 and 2024 PSFH segmentation benchmarks demonstrate that our method exhibits superior robustness and significantly outperforms existing techniques, providing a reliable segmentation tool for clinical practice.
Intrapartum Ultrasound Image Segmentation of Pubic Symphysis and Fetal Head Using Dual Student-Teacher Framework with CNN-ViT Collaborative Learning
Sep 11, 2024The segmentation of the pubic symphysis and fetal head (PSFH) constitutes a pivotal step in monitoring labor progression and identifying potential delivery complications. Despite the advances in deep learning, the lack of annotated medical images hinders the training of segmentation. Traditional semi-supervised learning approaches primarily utilize a unified network model based on Convolutional Neural Networks (CNNs) and apply consistency regularization to mitigate the reliance on extensive annotated data. However, these methods often fall short in capturing the discriminative features of unlabeled data and in delineating the long-range dependencies inherent in the ambiguous boundaries of PSFH within ultrasound images. To address these limitations, we introduce a novel framework, the Dual-Student and Teacher Combining CNN and Transformer (DSTCT), which synergistically integrates the capabilities of CNNs and Transformers. Our framework comprises a Vision Transformer (ViT) as the teacher and two student mod ls one ViT and one CNN. This dual-student setup enables mutual supervision through the generation of both hard and soft pseudo-labels, with the consistency in their predictions being refined by minimizing the classifier determinacy discrepancy. The teacher model further reinforces learning within this architecture through the imposition of consistency regularization constraints. To augment the generalization abilities of our approach, we employ a blend of data and model perturbation techniques. Comprehensive evaluations on the benchmark dataset of the PSFH Segmentation Grand Challenge at MICCAI 2023 demonstrate our DSTCT framework outperformed ten contemporary semi-supervised segmentation methods. Code available at https://github.com/jjm1589/DSTCT.
Finding representative sets of optimizations for adaptive multiversioning applications
Jul 14, 2014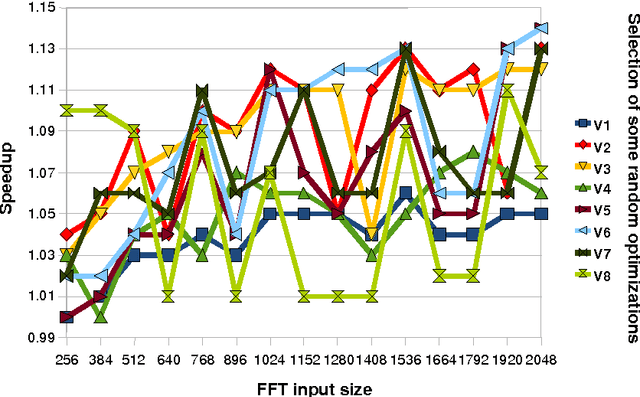

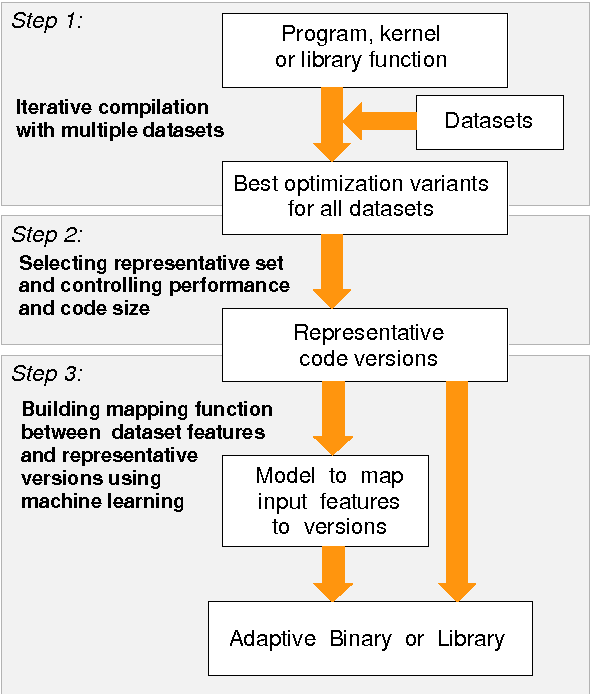
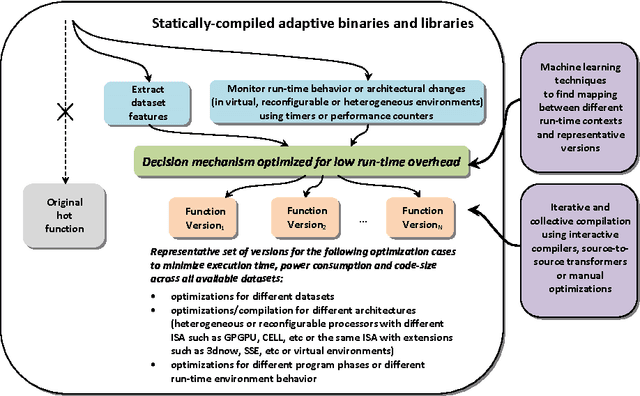
Iterative compilation is a widely adopted technique to optimize programs for different constraints such as performance, code size and power consumption in rapidly evolving hardware and software environments. However, in case of statically compiled programs, it is often restricted to optimizations for a specific dataset and may not be applicable to applications that exhibit different run-time behavior across program phases, multiple datasets or when executed in heterogeneous, reconfigurable and virtual environments. Several frameworks have been recently introduced to tackle these problems and enable run-time optimization and adaptation for statically compiled programs based on static function multiversioning and monitoring of online program behavior. In this article, we present a novel technique to select a minimal set of representative optimization variants (function versions) for such frameworks while avoiding performance loss across available datasets and code-size explosion. We developed a novel mapping mechanism using popular decision tree or rule induction based machine learning techniques to rapidly select best code versions at run-time based on dataset features and minimize selection overhead. These techniques enable creation of self-tuning static binaries or libraries adaptable to changing behavior and environments at run-time using staged compilation that do not require complex recompilation frameworks while effectively outperforming traditional single-version non-adaptable code.