 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPF-Net: Physical Imaging Model Embedded Data-Driven Underwater Image Enhancement
Mar 16, 2025Due to the complex interplay of light absorption and scattering in the underwater environment, underwater images experience significant degradation. This research presents a two-stage underwater image enhancement network called the Data-Driven and Physical Parameters Fusion Network (DPF-Net), which harnesses the robustness of physical imaging models alongside the generality and efficiency of data-driven methods. We first train a physical parameter estimate module using synthetic datasets to guarantee the trustworthiness of the physical parameters, rather than solely learning the fitting relationship between raw and reference images by the application of the imaging equation, as is common in prior studies. This module is subsequently trained in conjunction with an enhancement network, where the estimated physical parameters are integrated into a data-driven model within the embedding space. To maintain the uniformity of the restoration process amid underwater imaging degradation, we propose a physics-based degradation consistency loss. Additionally, we suggest an innovative weak reference loss term utilizing the entire dataset, which alleviates our model's reliance on the quality of individual reference images. Our proposed DPF-Net demonstrates superior performance compared to other benchmark methods across multiple test sets, achieving state-of-the-art results. The source code and pre-trained models are available on the project home page: https://github.com/OUCVisionGroup/DPF-Net.
Depth-Assisted Network for Indiscernible Marine Object Counting with Adaptive Motion-Differentiated Feature Encoding
Mar 11, 2025
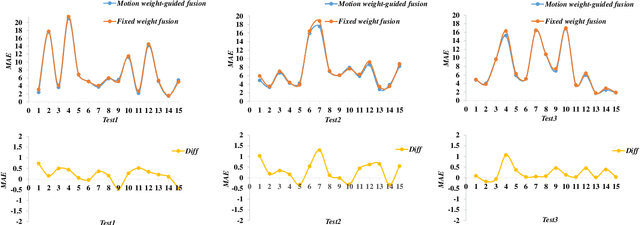
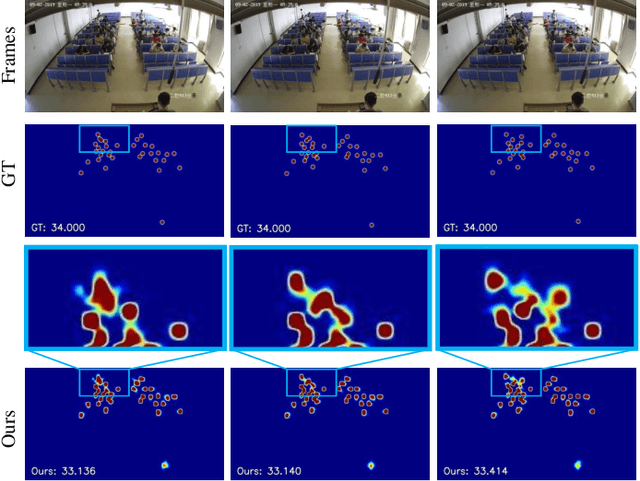
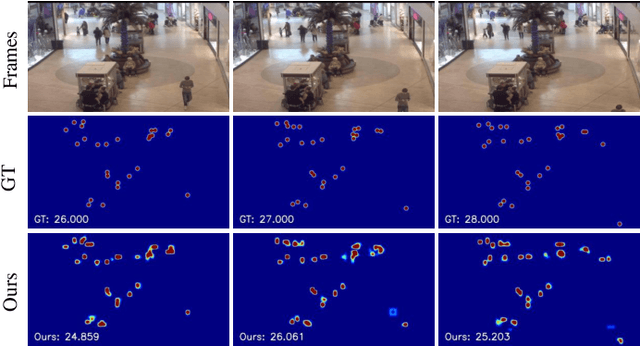
Indiscernible marine object counting encounters numerous challenges, including limited visibility in underwater scenes, mutual occlusion and overlap among objects, and the dynamic similarity in appearance, color, and texture between the background and foreground. These factors significantly complicate the counting process. To address the scarcity of video-based indiscernible object counting datasets, we have developed a novel dataset comprising 50 videos, from which approximately 800 frames have been extracted and annotated with around 40,800 point-wise object labels. This dataset accurately represents real underwater environments where indiscernible marine objects are intricately integrated with their surroundings, thereby comprehensively illustrating the aforementioned challenges in object counting. To address these challenges, we propose a depth-assisted network with adaptive motion-differentiated feature encoding. The network consists of a backbone encoding module and three branches: a depth-assisting branch, a density estimation branch, and a motion weight generation branch. Depth-aware features extracted by the depth-assisting branch are enhanced via a depth-enhanced encoder to improve object representation. Meanwhile, weights from the motion weight generation branch refine multi-scale perception features in the adaptive flow estimation module. Experimental results demonstrate that our method not only achieves state-of-the-art performance on the proposed dataset but also yields competitive results on three additional video-based crowd counting datasets. The pre-trained model, code, and dataset are publicly available at https://github.com/OUCVisionGroup/VIMOC-Net.
Towards the in-situ Trunk Identification and Length Measurement of Sea Cucumbers via Bézier Curve Modelling
Jun 20, 2024



We introduce a novel vision-based framework for in-situ trunk identification and length measurement of sea cucumbers, which plays a crucial role in the monitoring of marine ranching resources and mechanized harvesting. To model sea cucumber trunk curves with varying degrees of bending, we utilize the parametric B\'{e}zier curve due to its computational simplicity, stability, and extensive range of transformation possibilities. Then, we propose an end-to-end unified framework that combines parametric B\'{e}zier curve modeling with the widely used You-Only-Look-Once (YOLO) pipeline, abbreviated as TISC-Net, and incorporates effective funnel activation and efficient multi-scale attention modules to enhance curve feature perception and learning. Furthermore, we propose incorporating trunk endpoint loss as an additional constraint to effectively mitigate the impact of endpoint deviations on the overall curve. Finally, by utilizing the depth information of pixels located along the trunk curve captured by a binocular camera, we propose accurately estimating the in-situ length of sea cucumbers through space curve integration. We established two challenging benchmark datasets for curve-based in-situ sea cucumber trunk identification. These datasets consist of over 1,000 real-world marine environment images of sea cucumbers, accompanied by B\'{e}zier format annotations. We conduct evaluation on SC-ISTI, for which our method achieves mAP50 above 0.9 on both object detection and trunk identification tasks. Extensive length measurement experiments demonstrate that the average absolute relative error is around 0.15.
WaterMono: Teacher-Guided Anomaly Masking and Enhancement Boosting for Robust Underwater Self-Supervised Monocular Depth Estimation
Jun 19, 2024



Depth information serves as a crucial prerequisite for various visual tasks, whether on land or underwater. Recently, self-supervised methods have achieved remarkable performance on several terrestrial benchmarks despite the absence of depth annotations. However, in more challenging underwater scenarios, they encounter numerous brand-new obstacles such as the influence of marine life and degradation of underwater images, which break the assumption of a static scene and bring low-quality images, respectively. Besides, the camera angles of underwater images are more diverse. Fortunately, we have discovered that knowledge distillation presents a promising approach for tackling these challenges. In this paper, we propose WaterMono, a novel framework for depth estimation coupled with image enhancement. It incorporates the following key measures: (1) We present a Teacher-Guided Anomaly Mask to identify dynamic regions within the images; (2) We employ depth information combined with the Underwater Image Formation Model to generate enhanced images, which in turn contribute to the depth estimation task; and (3) We utilize a rotated distillation strategy to enhance the model's rotational robustness. Comprehensive experiments demonstrate the effectiveness of our proposed method for both depth estimation and image enhancement. The source code and pre-trained models are available on the project home page: https://github.com/OUCVisionGroup/WaterMono.
Underwater Image Enhancement by Diffusion Model with Customized CLIP-Classifier
May 25, 2024



In this paper, we propose a novel underwater image enhancement method, by utilizing the multi-guided diffusion model for iterative enhancement. Unlike other image enhancement tasks, underwater images suffer from the unavailability of real reference images. Although existing works exploit synthetic images, manually selected well-enhanced images as reference images, to train enhancement networks, their enhancement performance always comes with subjective preferences that are inherited from the manual selection. To address this issue, we also use the image synthesis strategy, but the synthetic images derive from in-air natural images degraded into corresponding underwater images, guided by the underwater domain. Based on this strategy, the diffusion model can learn the prior knowledge of image enhancement from the underwater degradation domain to the real in-air natural domain. However, it is inevitable to fine-tune the model to suit downstream tasks, and this may erase the prior knowledge. To mitigate this, we combine the prior knowledge from the in-air natural domain with Contrastive Language-Image Pretraining (CLIP) to train a classifier for controlling the diffusion model generation process. Moreover, for image enhancement tasks, we find that the image-to-image diffusion model and the CLIP-Classifier mainly act in the high-frequency region during the fine-tuning process. Therefore, we propose a fast fine-tuning strategy focusing on the high-frequency region, which can be up to 10 times faster than the traditional strategy. Extensive experiments demonstrate that our method, abbreviated as CLIP-UIE, exhibit a more natural appearance.