 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Assisted Network for Indiscernible Marine Object Counting with Adaptive Motion-Differentiated Feature Encoding
Paper and Code

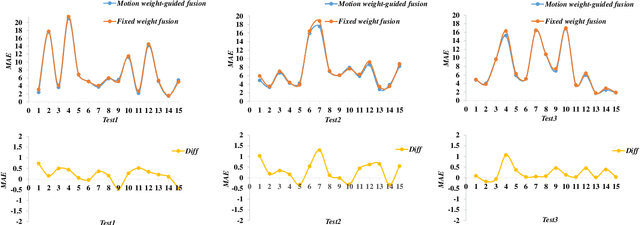
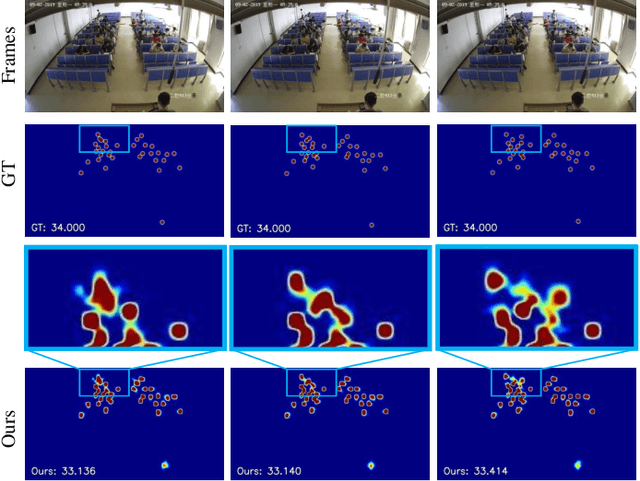
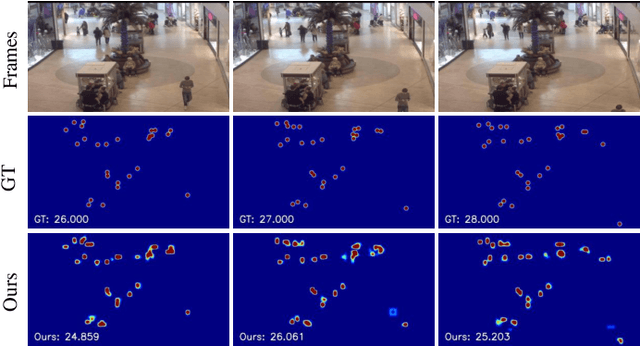
Indiscernible marine object counting encounters numerous challenges, including limited visibility in underwater scenes, mutual occlusion and overlap among objects, and the dynamic similarity in appearance, color, and texture between the background and foreground. These factors significantly complicate the counting process. To address the scarcity of video-based indiscernible object counting datasets, we have developed a novel dataset comprising 50 videos, from which approximately 800 frames have been extracted and annotated with around 40,800 point-wise object labels. This dataset accurately represents real underwater environments where indiscernible marine objects are intricately integrated with their surroundings, thereby comprehensively illustrating the aforementioned challenges in object counting. To address these challenges, we propose a depth-assisted network with adaptive motion-differentiated feature encoding. The network consists of a backbone encoding module and three branches: a depth-assisting branch, a density estimation branch, and a motion weight generation branch. Depth-aware features extracted by the depth-assisting branch are enhanced via a depth-enhanced encoder to improve object representation. Meanwhile, weights from the motion weight generation branch refine multi-scale perception features in the adaptive flow estimation module. Experimental results demonstrate that our method not only achieves state-of-the-art performance on the proposed dataset but also yields competitive results on three additional video-based crowd counting datasets. The pre-trained model, code, and dataset are publicly available at https://github.com/OUCVisionGroup/VIMOC-Net.