 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Sketches for Linear Regression
Nov 10, 2025Linear regression is frequently applied in a variety of domains. In order to improve the efficiency of these methods, various methods have been developed that compute summaries or \emph{sketches} of the datasets. Certain domains, however, contain sensitive data which necessitates that the application of these statistical methods does not reveal private information. Differentially private (DP) linear regression methods have been developed for mitigating this problem. These techniques typically involve estimating a noisy version of the parameter vector. Instead, we propose releasing private sketches of the datasets. We present differentially private sketches for the problems of least squares regression, as well as least absolute deviations regression. The availability of these private sketches facilitates the application of commonly available solvers for regression, without the risk of privacy leakage.
Linear Programming based Approximation to Individually Fair k-Clustering with Outliers
Dec 14, 2024
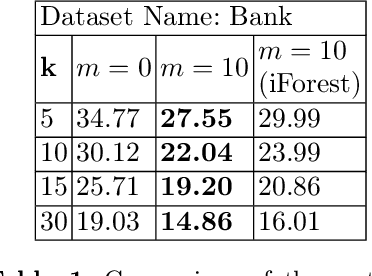
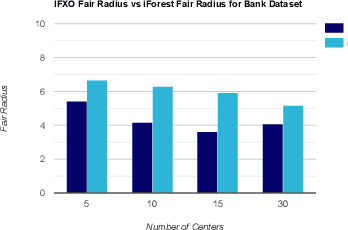
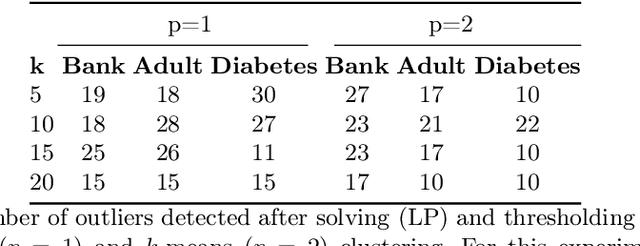
Individual fairness guarantees are often desirable properties to have, but they become hard to formalize when the dataset contains outliers. Here, we investigate the problem of developing an individually fair $k$-means clustering algorithm for datasets that contain outliers. That is, given $n$ points and $k$ centers, we want that for each point which is not an outlier, there must be a center within the $\frac{n}{k}$ nearest neighbours of the given point. While a few of the recent works have looked into individually fair clustering, this is the first work that explores this problem in the presence of outliers for $k$-means clustering. For this purpose, we define and solve a linear program (LP) that helps us identify the outliers. We exclude these outliers from the dataset and apply a rounding algorithm that computes the $k$ centers, such that the fairness constraint of the remaining points is satisfied. We also provide theoretical guarantees that our method leads to a guaranteed approximation of the fair radius as well as the clustering cost. We also demonstrate our techniques empirically on real-world datasets.
Improving Expressivity of Graph Neural Networks using Localization
May 31, 2023



In this paper, we propose localized versions of Weisfeiler-Leman (WL) algorithms in an effort to both increase the expressivity, as well as decrease the computational overhead. We focus on the specific problem of subgraph counting and give localized versions of $k-$WL for any $k$. We analyze the power of Local $k-$WL and prove that it is more expressive than $k-$WL and at most as expressive as $(k+1)-$WL. We give a characterization of patterns whose count as a subgraph and induced subgraph are invariant if two graphs are Local $k-$WL equivalent. We also introduce two variants of $k-$WL: Layer $k-$WL and recursive $k-$WL. These methods are more time and space efficient than applying $k-$WL on the whole graph. We also propose a fragmentation technique that guarantees the exact count of all induced subgraphs of size at most 4 using just $1-$WL. The same idea can be extended further for larger patterns using $k>1$. We also compare the expressive power of Local $k-$WL with other GNN hierarchies and show that given a bound on the time-complexity, our methods are more expressive than the ones mentioned in Papp and Wattenhofer[2022a].
Review of Extreme Multilabel Classification
Feb 12, 2023



Extreme multilabel classification or XML, in short, has emerged as a new subtopic of interest in machine learning. Compared to traditional multilabel classification, here the number of labels is extremely large, hence the name extreme multilabel classification. Using classical one versus all classification wont scale in this case due to large number of labels, same is true for any other classifiers. Embedding of labels as well as features into smaller label space is an essential first step. Moreover, other issues include existance of head and tail labels, where tail labels are labels which exist in relatively smaller number of given samples. The existence of tail labels creates issues during embedding. This area has invited application of wide range of approaches ranging from bit compression motivated from compressed sensing, tree based embeddings, deep learning based latent space embedding including using attention weights, linear algebra based embeddings such as SVD, clustering, hashing, to name a few. The community has come up with a useful set of metrics to identify the correctly the prediction for head or tail labels.