 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Programming based Approximation to Individually Fair k-Clustering with Outliers
Paper and Code
Dec 14, 2024
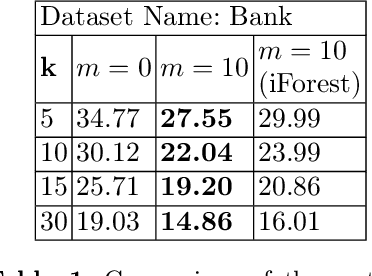
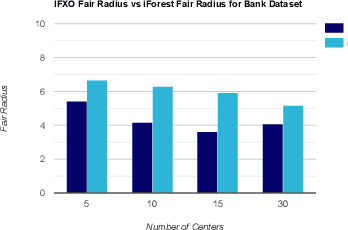
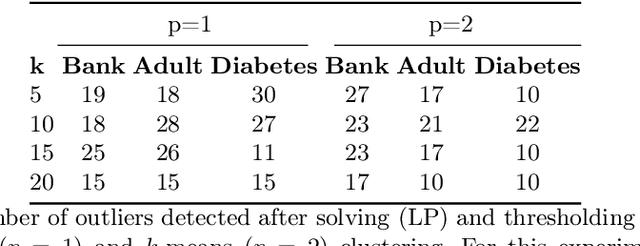
Individual fairness guarantees are often desirable properties to have, but they become hard to formalize when the dataset contains outliers. Here, we investigate the problem of developing an individually fair $k$-means clustering algorithm for datasets that contain outliers. That is, given $n$ points and $k$ centers, we want that for each point which is not an outlier, there must be a center within the $\frac{n}{k}$ nearest neighbours of the given point. While a few of the recent works have looked into individually fair clustering, this is the first work that explores this problem in the presence of outliers for $k$-means clustering. For this purpose, we define and solve a linear program (LP) that helps us identify the outliers. We exclude these outliers from the dataset and apply a rounding algorithm that computes the $k$ centers, such that the fairness constraint of the remaining points is satisfied. We also provide theoretical guarantees that our method leads to a guaranteed approximation of the fair radius as well as the clustering cost. We also demonstrate our techniques empirically on real-world datasets.