 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics and semantic informed multi-sensor calibration via optimization theory and self-supervised learning
Jun 06, 2022
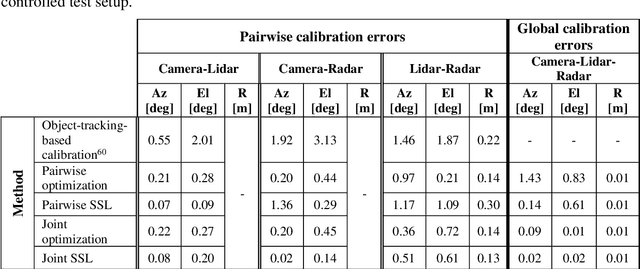


Achieving safe and reliable autonomous driving relies greatly on the ability to achieve an accurate and robust perception system; however, this cannot be fully realized without precisely calibrated sensors. Environmental and operational conditions as well as improper maintenance can produce calibration errors inhibiting sensor fusion and, consequently, degrading the perception performance. Traditionally, sensor calibration is performed in a controlled environment with one or more known targets. Such a procedure can only be carried out in between drives and requires manual operation; a tedious task if needed to be conducted on a regular basis. This sparked a recent interest in online targetless methods, capable of yielding a set of geometric transformations based on perceived environmental features, however, the required redundancy in sensing modalities makes this task even more challenging, as the features captured by each modality and their distinctiveness may vary. We present a holistic approach to performing joint calibration of a camera-lidar-radar trio. Leveraging prior knowledge and physical properties of these sensing modalities together with semantic information, we propose two targetless calibration methods within a cost minimization framework once via direct online optimization, and second via self-supervised learning (SSL).
Integrating Deep Reinforcement and Supervised Learning to Expedite Indoor Mapping
Sep 17, 2021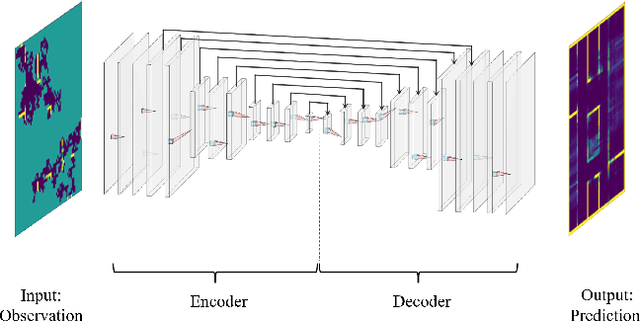
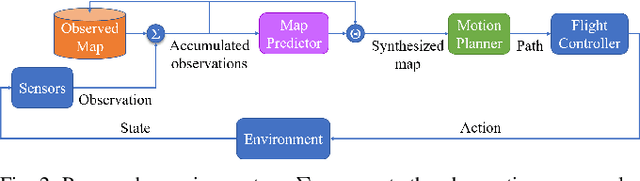
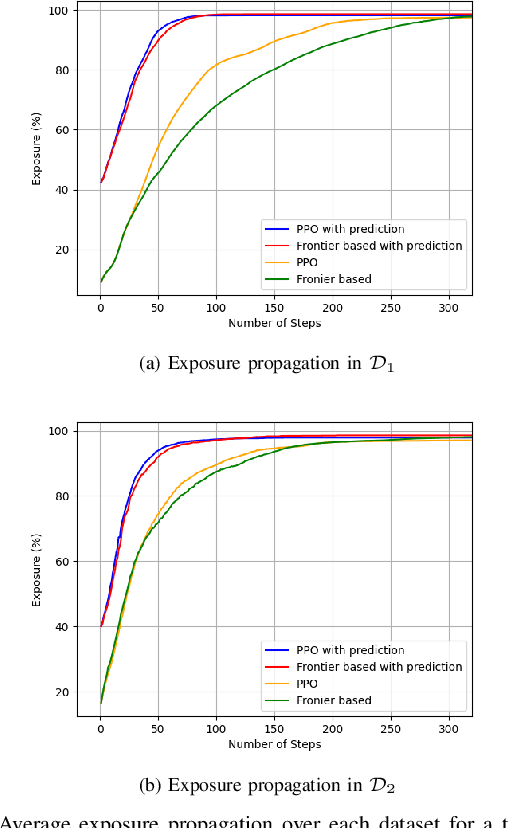
The challenge of mapping indoor environments is addressed. Typical heuristic algorithms for solving the motion planning problem are frontier-based methods, that are especially effective when the environment is completely unknown. However, in cases where prior statistical data on the environment's architectonic features is available, such algorithms can be far from optimal. Furthermore, their calculation time may increase substantially as more areas are exposed. In this paper we propose two means by which to overcome these shortcomings. One is the use of deep reinforcement learning to train the motion planner. The second is the inclusion of a pre-trained generative deep neural network, acting as a map predictor. Each one helps to improve the decision making through use of the learned structural statistics of the environment, and both, being realized as neural networks, ensure a constant calculation time. We show that combining the two methods can shorten the mapping time, compared to frontier-based motion planning, by up to 75%.
Integrating Deep-Learning-Based Image Completion and Motion Planning to Expedite Indoor Mapping
Nov 03, 2020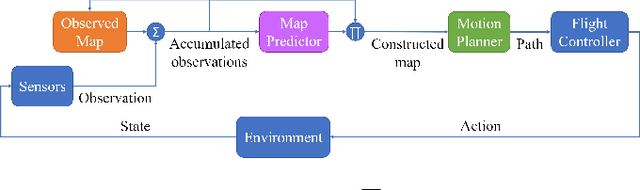
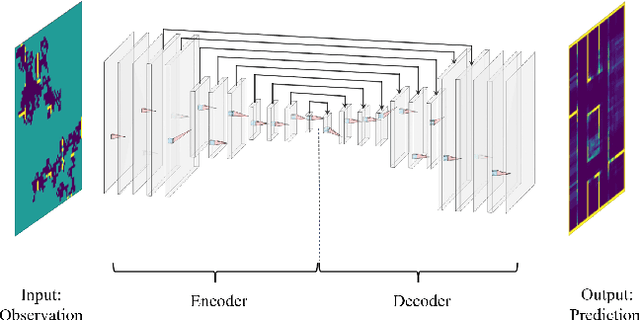
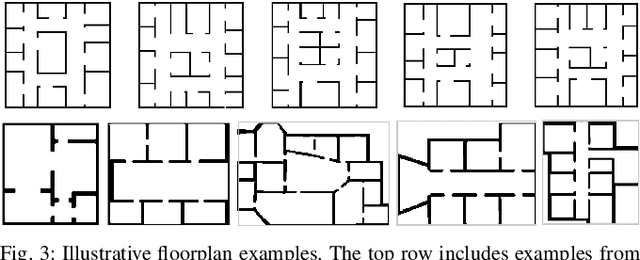
The challenge of autonomous indoor mapping is addressed. The goal is to minimize the time required to achieve a predefined percentage of coverage with some desired level of certainty. The use of a pre-trained generative deep neural network, acting as a map predictor, in both the motion planning and the map construction is proposed in order to expedite the mapping process. The issue of planning under partial observability is tackled by maintaining a belief map of the floorplan, generated by a deep neural network. This allows the agent to shorten the mapping duration, as well as enabling it to make better-informed decisions. This method is examined in combination with several motion planners for two distinct floorplan datasets. Simulations are run for several configurations of the integrated map predictor, the results of which reveal that by utilizing the prediction a significant reduction in mapping time is possible. When the prediction is integrated in both motion planning and map construction processes it is shown that the mapping time may in some cases be cut by over 50%.