 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCPA: Long-term Person Re-Identification via Contrastive Clothing and Pose Augmentation
Feb 22, 2024Long-term Person Re-Identification (LRe-ID) aims at matching an individual across cameras after a long period of time, presenting variations in clothing, pose, and viewpoint. In this work, we propose CCPA: Contrastive Clothing and Pose Augmentation framework for LRe-ID. Beyond appearance, CCPA captures body shape information which is cloth-invariant using a Relation Graph Attention Network. Training a robust LRe-ID model requires a wide range of clothing variations and expensive cloth labeling, which is lacked in current LRe-ID datasets. To address this, we perform clothing and pose transfer across identities to generate images of more clothing variations and of different persons wearing similar clothing. The augmented batch of images serve as inputs to our proposed Fine-grained Contrastive Losses, which not only supervise the Re-ID model to learn discriminative person embeddings under long-term scenarios but also ensure in-distribution data generation. Results on LRe-ID datasets demonstrate the effectiveness of our CCPA framework.
Data Quality Aware Approaches for Addressing Model Drift of Semantic Segmentation Models
Feb 11, 2024In the midst of the rapid integration of artificial intelligence (AI) into real world applications, one pressing challenge we confront is the phenomenon of model drift, wherein the performance of AI models gradually degrades over time, compromising their effectiveness in real-world, dynamic environments. Once identified, we need techniques for handling this drift to preserve the model performance and prevent further degradation. This study investigates two prominent quality aware strategies to combat model drift: data quality assessment and data conditioning based on prior model knowledge. The former leverages image quality assessment metrics to meticulously select high-quality training data, improving the model robustness, while the latter makes use of learned feature vectors from existing models to guide the selection of future data, aligning it with the model's prior knowledge. Through comprehensive experimentation, this research aims to shed light on the efficacy of these approaches in enhancing the performance and reliability of semantic segmentation models, thereby contributing to the advancement of computer vision capabilities in real-world scenarios.
Attention-based Shape and Gait Representations Learning for Video-based Cloth-Changing Person Re-Identification
Feb 06, 2024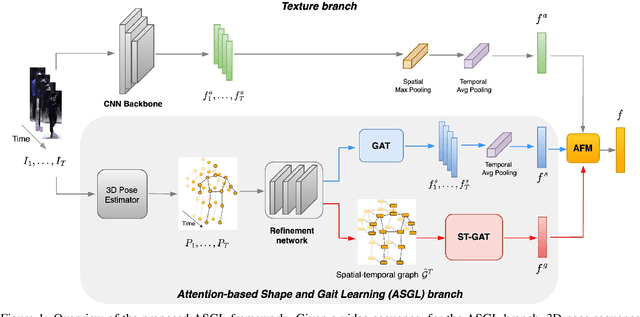
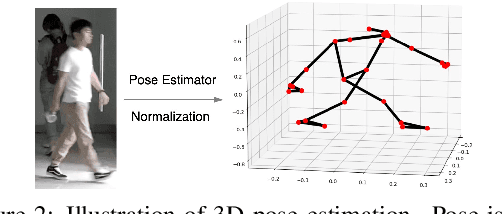
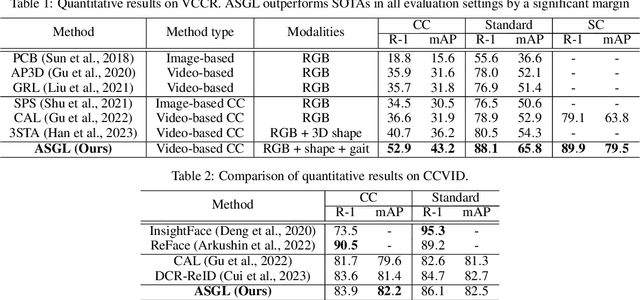
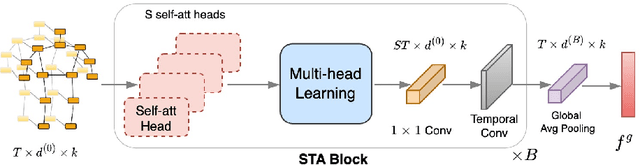
Current state-of-the-art Video-based Person Re-Identification (Re-ID) primarily relies on appearance features extracted by deep learning models. These methods are not applicable for long-term analysis in real-world scenarios where persons have changed clothes, making appearance information unreliable. In this work, we deal with the practical problem of Video-based Cloth-Changing Person Re-ID (VCCRe-ID) by proposing "Attention-based Shape and Gait Representations Learning" (ASGL) for VCCRe-ID. Our ASGL framework improves Re-ID performance under clothing variations by learning clothing-invariant gait cues using a Spatial-Temporal Graph Attention Network (ST-GAT). Given the 3D-skeleton-based spatial-temporal graph, our proposed ST-GAT comprises multi-head attention modules, which are able to enhance the robustness of gait embeddings under viewpoint changes and occlusions. The ST-GAT amplifies the important motion ranges and reduces the influence of noisy poses. Then, the multi-head learning module effectively reserves beneficial local temporal dynamics of movement. We also boost discriminative power of person representations by learning body shape cues using a GAT. Experiments on two large-scale VCCRe-ID datasets demonstrate that our proposed framework outperforms state-of-the-art methods by 12.2% in rank-1 accuracy and 7.0% in mAP.
A Survey of Feature Types and Their Contributions for Camera Tampering Detection
Oct 11, 2023



Camera tamper detection is the ability to detect unauthorized and unintentional alterations in surveillance cameras by analyzing the video. Camera tampering can occur due to natural events or it can be caused intentionally to disrupt surveillance. We cast tampering detection as a change detection problem, and perform a review of the existing literature with emphasis on feature types. We formulate tampering detection as a time series analysis problem, and design experiments to study the robustness and capability of various feature types. We compute ten features on real-world surveillance video and apply time series analysis to ascertain their predictability, and their capability to detect tampering. Finally, we quantify the performance of various time series models using each feature type to detect tampering.
GoDP: Globally optimized dual pathway system for facial landmark localization in-the-wild
Dec 19, 2017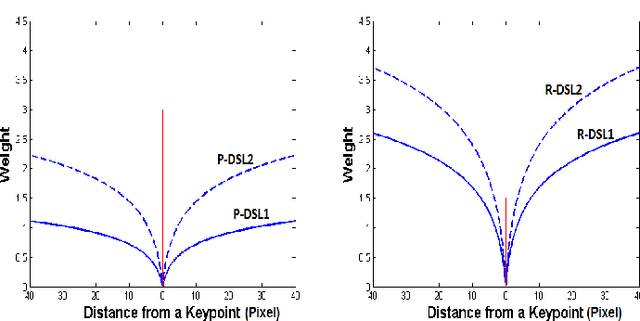

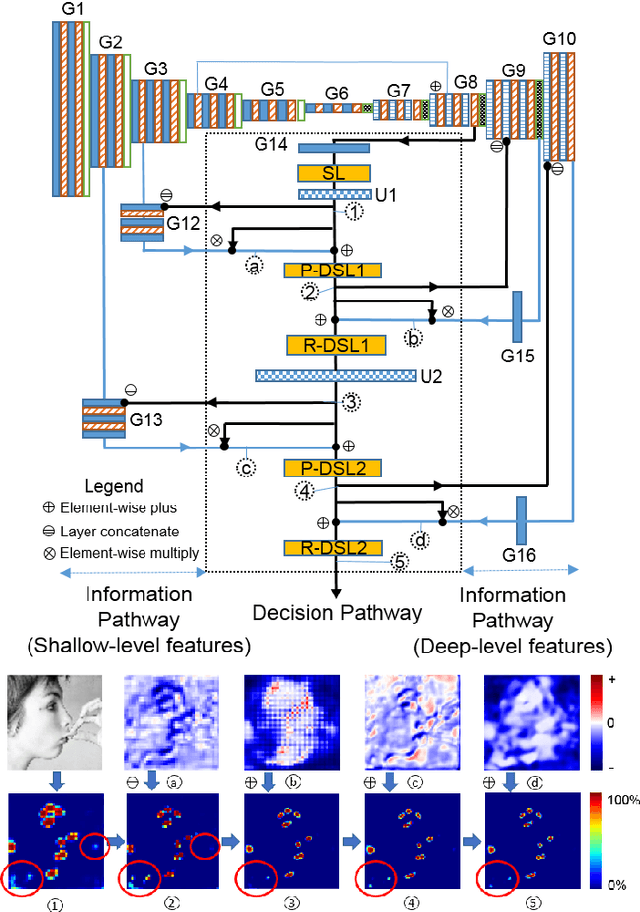
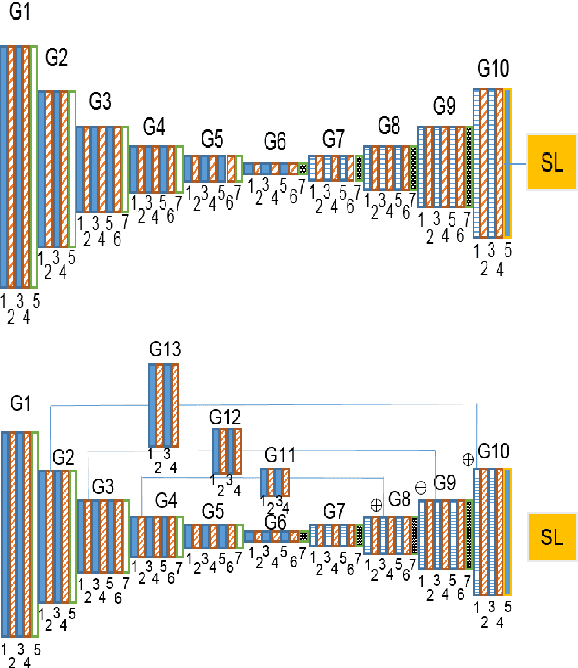
Facial landmark localization is a fundamental module for pose-invariant face recognition. The most common approach for facial landmark detection is cascaded regression, which is composed of two steps: feature extraction and facial shape regression. Recent methods employ deep convolutional networks to extract robust features for each step, while the whole system could be regarded as a deep cascaded regression architecture. In this work, instead of employing a deep regression network, a Globally Optimized Dual-Pathway (GoDP) deep architecture is proposed to identify the target pixels through solving a cascaded pixel labeling problem without resorting to high-level inference models or complex stacked architecture. The proposed end-to-end system relies on distance-aware softmax functions and dual-pathway proposal-refinement architecture. Results show that it outperforms the state-of-the-art cascaded regression-based methods on multiple in-the-wild face alignment databases. The model achieves 1.84 normalized mean error (NME) on the AFLW database, which outperforms 3DDFA by 61.8%. Experiments on face identification demonstrate that GoDP, coupled with DPM-headhunter, is able to improve rank-1 identification rate by 44.2% compared to Dlib toolbox on a challenging database.
* Accepted by Image and Vision Computing in December, 2017
End-to-end 3D face reconstruction with deep neural networks
Apr 17, 2017

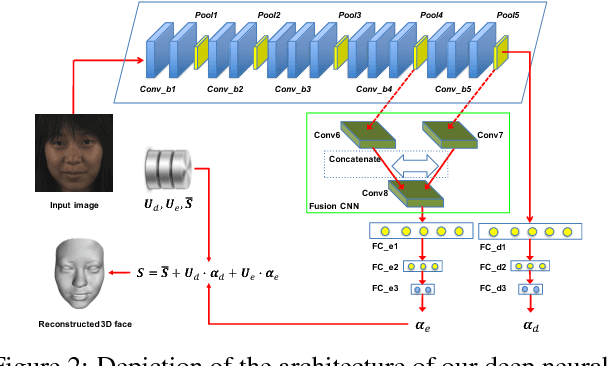

Monocular 3D facial shape reconstruction from a single 2D facial image has been an active research area due to its wide applications. Inspired by the success of deep neural networks (DNN), we propose a DNN-based approach for End-to-End 3D FAce Reconstruction (UH-E2FAR) from a single 2D image. Different from recent works that reconstruct and refine the 3D face in an iterative manner using both an RGB image and an initial 3D facial shape rendering, our DNN model is end-to-end, and thus the complicated 3D rendering process can be avoided. Moreover, we integrate in the DNN architecture two components, namely a multi-task loss function and a fusion convolutional neural network (CNN) to improve facial expression reconstruction. With the multi-task loss function, 3D face reconstruction is divided into neutral 3D facial shape reconstruction and expressive 3D facial shape reconstruction. The neutral 3D facial shape is class-specific. Therefore, higher layer features are useful. In comparison, the expressive 3D facial shape favors lower or intermediate layer features. With the fusion-CNN, features from different intermediate layers are fused and transformed for predicting the 3D expressive facial shape. Through extensive experiments, we demonstrate the superiority of our end-to-end framework in improving the accuracy of 3D face reconstruction.