 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-based Face Recognition using a Hierarchical Multi-label Matcher
Apr 03, 2018


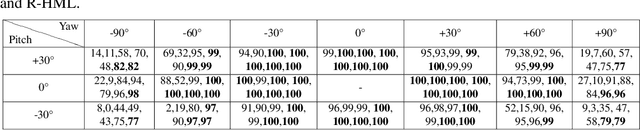
This paper proposes a hierarchical multi-label matcher for patch-based face recognition. In signature generation, a face image is iteratively divided into multi-level patches. Two different types of patch divisions and signatures are introduced for 2D facial image and texture-lifted image, respectively. The matcher training consists of three steps. First, local classifiers are built to learn the local matching of each patch. Second, the hierarchical relationships defined between local patches are used to learn the global matching of each patch. Three ways are introduced to learn the global matching: majority voting, l1-regularized weighting, and decision rule. Last, the global matchings of different levels are combined as the final matching. Experimental results on different face recognition tasks demonstrate the effectiveness of the proposed matcher at the cost of gallery generalization. Compared with the UR2D system, the proposed matcher improves the Rank-1 accuracy significantly by 3% and 0.18% on the UHDB31 dataset and IJB-A dataset, respectively.
A Face Recognition Signature Combining Patch-based Features with Soft Facial Attributes
Mar 25, 2018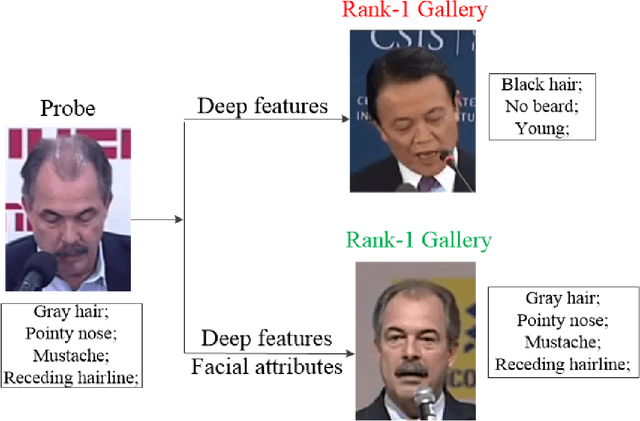


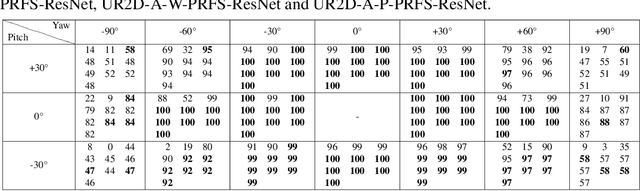
This paper focuses on improving face recognition performance with a new signature combining implicit facial features with explicit soft facial attributes. This signature has two components: the existing patch-based features and the soft facial attributes. A deep convolutional neural network adapted from state-of-the-art networks is used to learn the soft facial attributes. Then, a signature matcher is introduced that merges the contributions of both patch-based features and the facial attributes. In this matcher, the matching scores computed from patch-based features and the facial attributes are combined to obtain a final matching score. The matcher is also extended so that different weights are assigned to different facial attributes. The proposed signature and matcher have been evaluated with the UR2D system on the UHDB31 and IJB-A datasets. The experimental results indicate that the proposed signature achieve better performance than using only patch-based features. The Rank-1 accuracy is improved significantly by 4% and 0.37% on the two datasets when compared with the UR2D system.
When 3D-Aided 2D Face Recognition Meets Deep Learning: An extended UR2D for Pose-Invariant Face Recognition
Sep 19, 2017



Most of the face recognition works focus on specific modules or demonstrate a research idea. This paper presents a pose-invariant 3D-aided 2D face recognition system (UR2D) that is robust to pose variations as large as 90? by leveraging deep learning technology. The architecture and the interface of UR2D are described, and each module is introduced in detail. Extensive experiments are conducted on the UHDB31 and IJB-A, demonstrating that UR2D outperforms existing 2D face recognition systems such as VGG-Face, FaceNet, and a commercial off-the-shelf software (COTS) by at least 9% on the UHDB31 dataset and 3% on the IJB-A dataset on average in face identification tasks. UR2D also achieves state-of-the-art performance of 85% on the IJB-A dataset by comparing the Rank-1 accuracy score from template matching. It fills a gap by providing a 3D-aided 2D face recognition system that has compatible results with 2D face recognition systems using deep learning techniques.
End-to-end 3D face reconstruction with deep neural networks
Apr 17, 2017

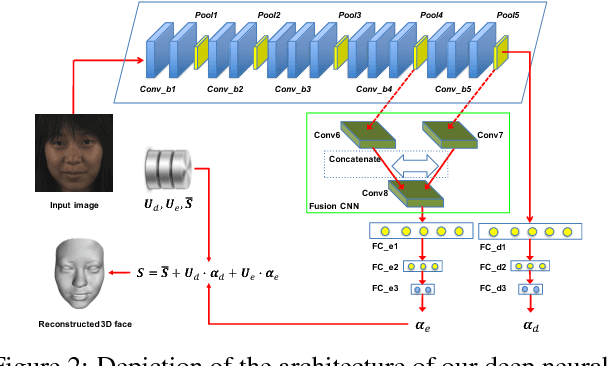

Monocular 3D facial shape reconstruction from a single 2D facial image has been an active research area due to its wide applications. Inspired by the success of deep neural networks (DNN), we propose a DNN-based approach for End-to-End 3D FAce Reconstruction (UH-E2FAR) from a single 2D image. Different from recent works that reconstruct and refine the 3D face in an iterative manner using both an RGB image and an initial 3D facial shape rendering, our DNN model is end-to-end, and thus the complicated 3D rendering process can be avoided. Moreover, we integrate in the DNN architecture two components, namely a multi-task loss function and a fusion convolutional neural network (CNN) to improve facial expression reconstruction. With the multi-task loss function, 3D face reconstruction is divided into neutral 3D facial shape reconstruction and expressive 3D facial shape reconstruction. The neutral 3D facial shape is class-specific. Therefore, higher layer features are useful. In comparison, the expressive 3D facial shape favors lower or intermediate layer features. With the fusion-CNN, features from different intermediate layers are fused and transformed for predicting the 3D expressive facial shape. Through extensive experiments, we demonstrate the superiority of our end-to-end framework in improving the accuracy of 3D face reconstruction.