 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Quality Aware Approaches for Addressing Model Drift of Semantic Segmentation Models
Feb 11, 2024In the midst of the rapid integration of artificial intelligence (AI) into real world applications, one pressing challenge we confront is the phenomenon of model drift, wherein the performance of AI models gradually degrades over time, compromising their effectiveness in real-world, dynamic environments. Once identified, we need techniques for handling this drift to preserve the model performance and prevent further degradation. This study investigates two prominent quality aware strategies to combat model drift: data quality assessment and data conditioning based on prior model knowledge. The former leverages image quality assessment metrics to meticulously select high-quality training data, improving the model robustness, while the latter makes use of learned feature vectors from existing models to guide the selection of future data, aligning it with the model's prior knowledge. Through comprehensive experimentation, this research aims to shed light on the efficacy of these approaches in enhancing the performance and reliability of semantic segmentation models, thereby contributing to the advancement of computer vision capabilities in real-world scenarios.
Attention-based Shape and Gait Representations Learning for Video-based Cloth-Changing Person Re-Identification
Feb 06, 2024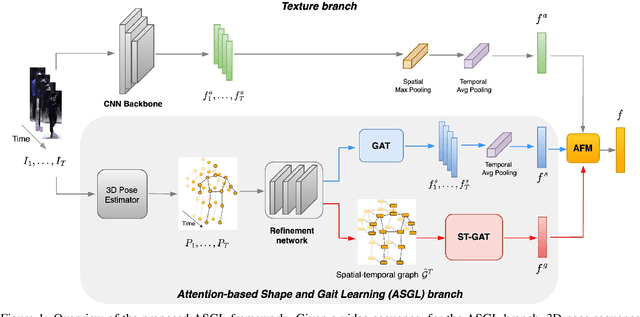
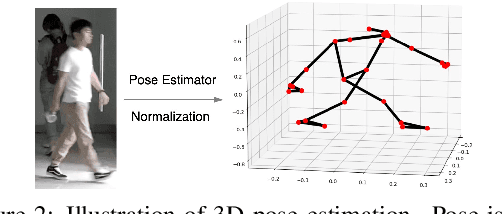
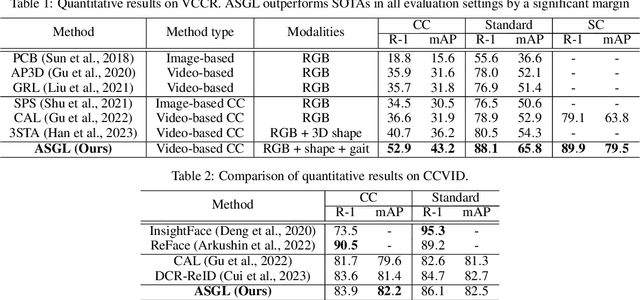
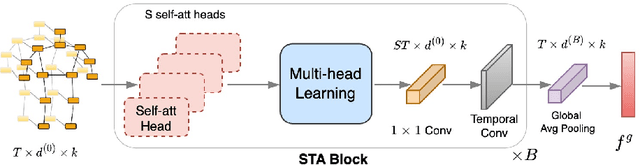
Current state-of-the-art Video-based Person Re-Identification (Re-ID) primarily relies on appearance features extracted by deep learning models. These methods are not applicable for long-term analysis in real-world scenarios where persons have changed clothes, making appearance information unreliable. In this work, we deal with the practical problem of Video-based Cloth-Changing Person Re-ID (VCCRe-ID) by proposing "Attention-based Shape and Gait Representations Learning" (ASGL) for VCCRe-ID. Our ASGL framework improves Re-ID performance under clothing variations by learning clothing-invariant gait cues using a Spatial-Temporal Graph Attention Network (ST-GAT). Given the 3D-skeleton-based spatial-temporal graph, our proposed ST-GAT comprises multi-head attention modules, which are able to enhance the robustness of gait embeddings under viewpoint changes and occlusions. The ST-GAT amplifies the important motion ranges and reduces the influence of noisy poses. Then, the multi-head learning module effectively reserves beneficial local temporal dynamics of movement. We also boost discriminative power of person representations by learning body shape cues using a GAT. Experiments on two large-scale VCCRe-ID datasets demonstrate that our proposed framework outperforms state-of-the-art methods by 12.2% in rank-1 accuracy and 7.0% in mAP.