 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Shape and Gait Representations Learning for Video-based Cloth-Changing Person Re-Identification
Paper and Code
Feb 06, 2024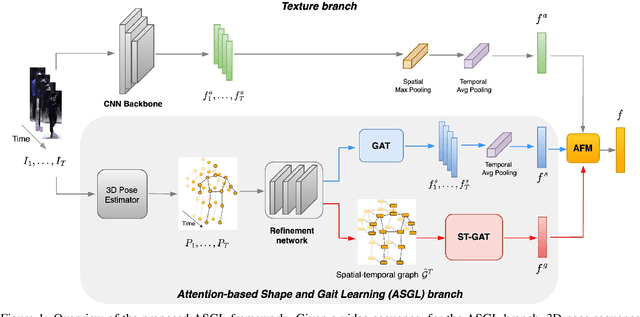
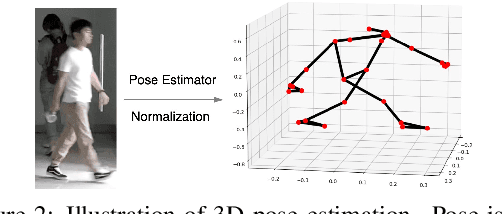
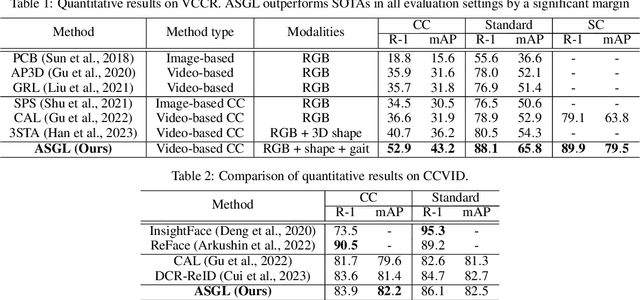
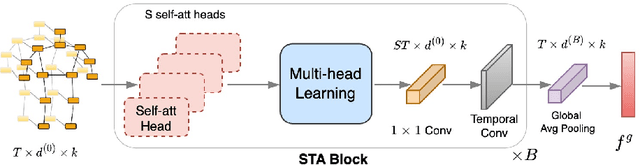
Current state-of-the-art Video-based Person Re-Identification (Re-ID) primarily relies on appearance features extracted by deep learning models. These methods are not applicable for long-term analysis in real-world scenarios where persons have changed clothes, making appearance information unreliable. In this work, we deal with the practical problem of Video-based Cloth-Changing Person Re-ID (VCCRe-ID) by proposing "Attention-based Shape and Gait Representations Learning" (ASGL) for VCCRe-ID. Our ASGL framework improves Re-ID performance under clothing variations by learning clothing-invariant gait cues using a Spatial-Temporal Graph Attention Network (ST-GAT). Given the 3D-skeleton-based spatial-temporal graph, our proposed ST-GAT comprises multi-head attention modules, which are able to enhance the robustness of gait embeddings under viewpoint changes and occlusions. The ST-GAT amplifies the important motion ranges and reduces the influence of noisy poses. Then, the multi-head learning module effectively reserves beneficial local temporal dynamics of movement. We also boost discriminative power of person representations by learning body shape cues using a GAT. Experiments on two large-scale VCCRe-ID datasets demonstrate that our proposed framework outperforms state-of-the-art methods by 12.2% in rank-1 accuracy and 7.0% in mAP.