 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Task-Oriented Dialogue Generation with Contrastive Pre-training and Adversarial Filtering
May 20, 2022
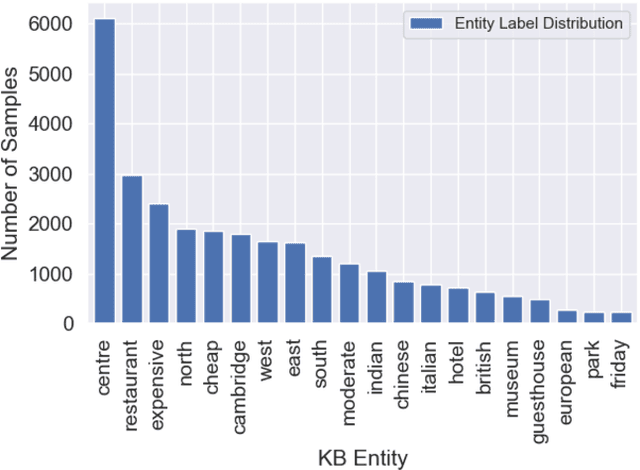


Data artifacts incentivize machine learning models to learn non-transferable generalizations by taking advantage of shortcuts in the data, and there is growing evidence that data artifacts play a role for the strong results that deep learning models achieve in recent natural language processing benchmarks. In this paper, we focus on task-oriented dialogue and investigate whether popular datasets such as MultiWOZ contain such data artifacts. We found that by only keeping frequent phrases in the training examples, state-of-the-art models perform similarly compared to the variant trained with full data, suggesting they exploit these spurious correlations to solve the task. Motivated by this, we propose a contrastive learning based framework to encourage the model to ignore these cues and focus on learning generalisable patterns. We also experiment with adversarial filtering to remove "easy" training instances so that the model would focus on learning from the "harder" instances. We conduct a number of generalization experiments -- e.g., cross-domain/dataset and adversarial tests -- to assess the robustness of our approach and found that it works exceptionally well.
An Interpretable Neuro-Symbolic Reasoning Framework for Task-Oriented Dialogue Generation
Mar 11, 2022


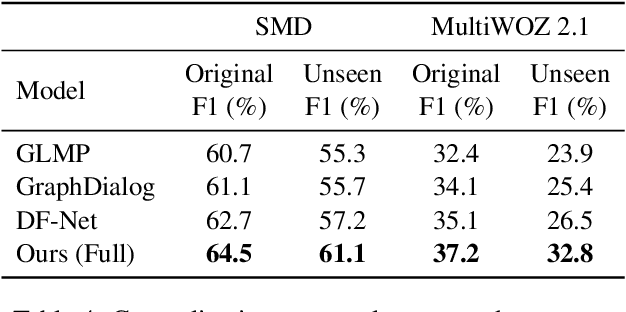
We study the interpretability issue of task-oriented dialogue systems in this paper. Previously, most neural-based task-oriented dialogue systems employ an implicit reasoning strategy that makes the model predictions uninterpretable to humans. To obtain a transparent reasoning process, we introduce neuro-symbolic to perform explicit reasoning that justifies model decisions by reasoning chains. Since deriving reasoning chains requires multi-hop reasoning for task-oriented dialogues, existing neuro-symbolic approaches would induce error propagation due to the one-phase design. To overcome this, we propose a two-phase approach that consists of a hypothesis generator and a reasoner. We first obtain multiple hypotheses, i.e., potential operations to perform the desired task, through the hypothesis generator. Each hypothesis is then verified by the reasoner, and the valid one is selected to conduct the final prediction. The whole system is trained by exploiting raw textual dialogues without using any reasoning chain annotations. Experimental studies on two public benchmark datasets demonstrate that the proposed approach not only achieves better results, but also introduces an interpretable decision process.
GraphDialog: Integrating Graph Knowledge into End-to-End Task-Oriented Dialogue Systems
Oct 04, 2020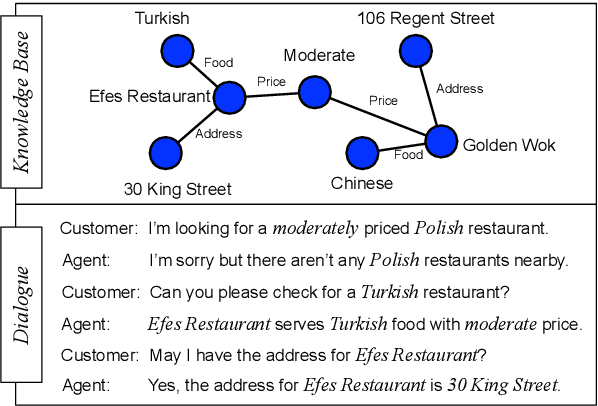

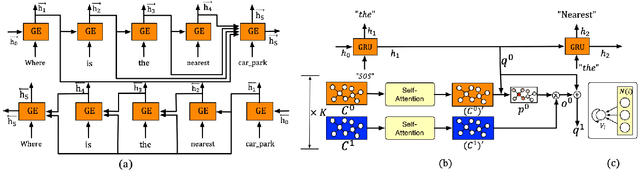
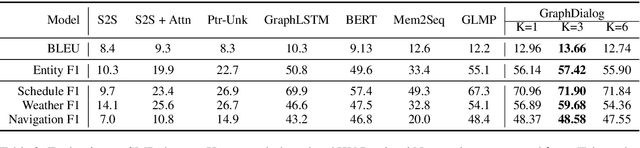
End-to-end task-oriented dialogue systems aim to generate system responses directly from plain text inputs. There are two challenges for such systems: one is how to effectively incorporate external knowledge bases (KBs) into the learning framework; the other is how to accurately capture the semantics of dialogue history. In this paper, we address these two challenges by exploiting the graph structural information in the knowledge base and in the dependency parsing tree of the dialogue. To effectively leverage the structural information in dialogue history, we propose a new recurrent cell architecture which allows representation learning on graphs. To exploit the relations between entities in KBs, the model combines multi-hop reasoning ability based on the graph structure. Experimental results show that the proposed model achieves consistent improvement over state-of-the-art models on two different task-oriented dialogue datasets.