 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Robust Long-Form Speech Recognition with Hybrid H3-Conformer
Oct 05, 2024



Recently, Conformer has achieved state-of-the-art performance in many speech recognition tasks. However, the Transformer-based models show significant deterioration for long-form speech, such as lectures, because the self-attention mechanism becomes unreliable with the computation of the square order of the input length. To solve the problem, we incorporate a kind of state-space model, Hungry Hungry Hippos (H3), to replace or complement the multi-head self-attention (MHSA). H3 allows for efficient modeling of long-form sequences with a linear-order computation. In experiments using two datasets of CSJ and LibriSpeech, our proposed H3-Conformer model performs efficient and robust recognition of long-form speech. Moreover, we propose a hybrid of H3 and MHSA and show that using H3 in higher layers and MHSA in lower layers provides significant improvement in online recognition. We also investigate a parallel use of H3 and MHSA in all layers, resulting in the best performance.
Non-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022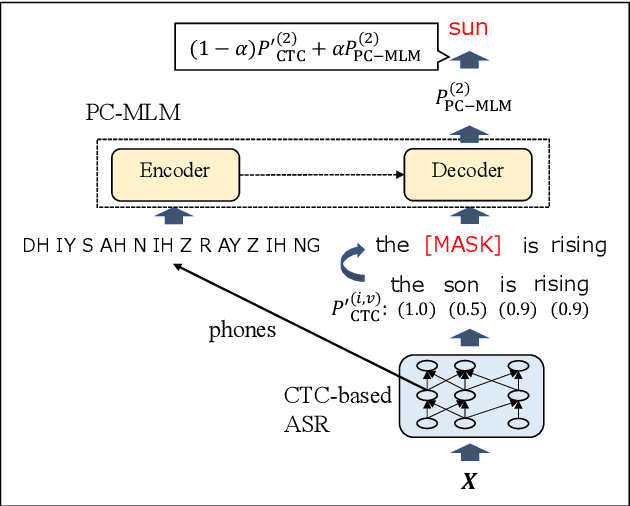
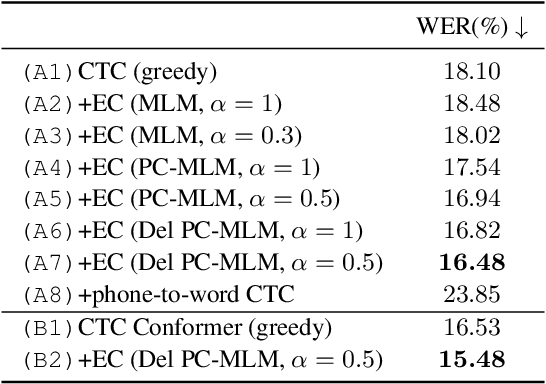
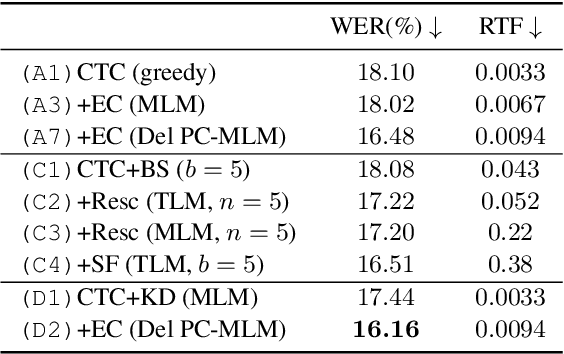
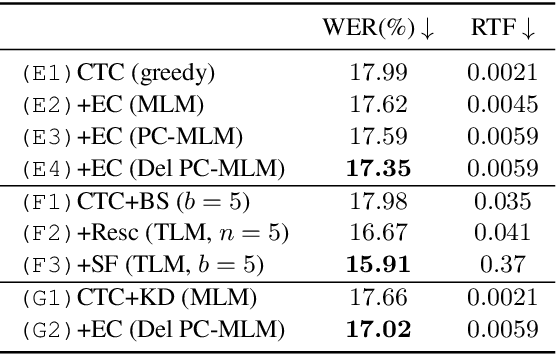
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
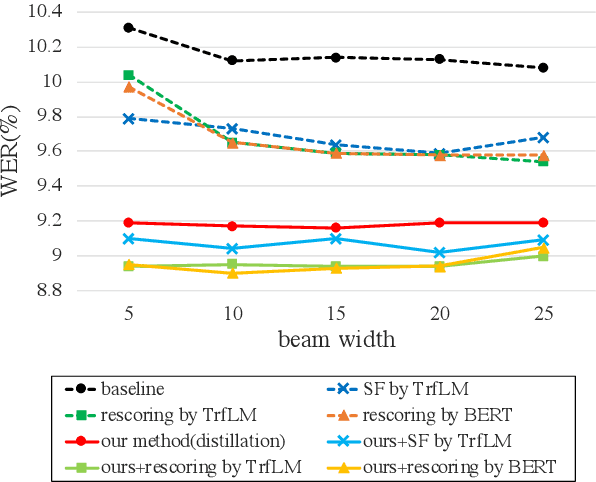
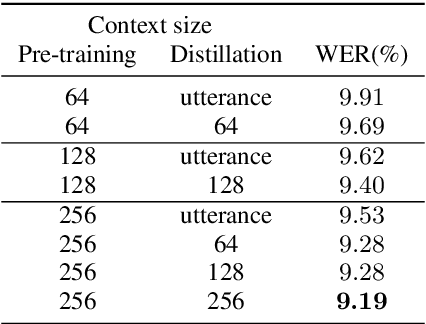
Distilling the Knowledge of BERT for CTC-based ASR
Sep 05, 2022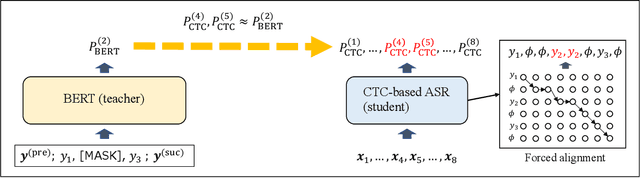

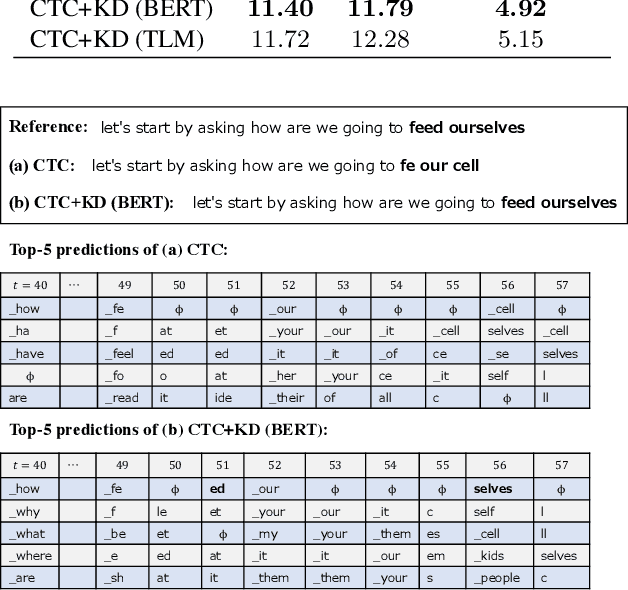
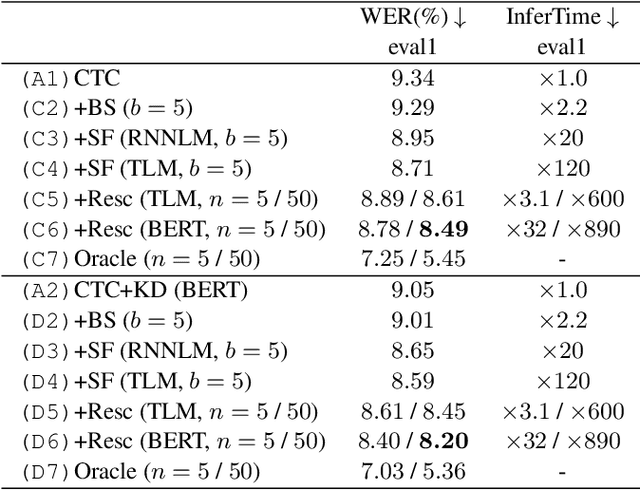
Connectionist temporal classification (CTC) -based models are attractive because of their fast inference in automatic speech recognition (ASR). Language model (LM) integration approaches such as shallow fusion and rescoring can improve the recognition accuracy of CTC-based ASR by taking advantage of the knowledge in text corpora. However, they significantly slow down the inference of CTC. In this study, we propose to distill the knowledge of BERT for CTC-based ASR, extending our previous study for attention-based ASR. CTC-based ASR learns the knowledge of BERT during training and does not use BERT during testing, which maintains the fast inference of CTC. Different from attention-based models, CTC-based models make frame-level predictions, so they need to be aligned with token-level predictions of BERT for distillation. We propose to obtain alignments by calculating the most plausible CTC paths. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 show that our method improves the performance of CTC-based ASR without the cost of inference speed.
ASR Rescoring and Confidence Estimation with ELECTRA
Oct 05, 2021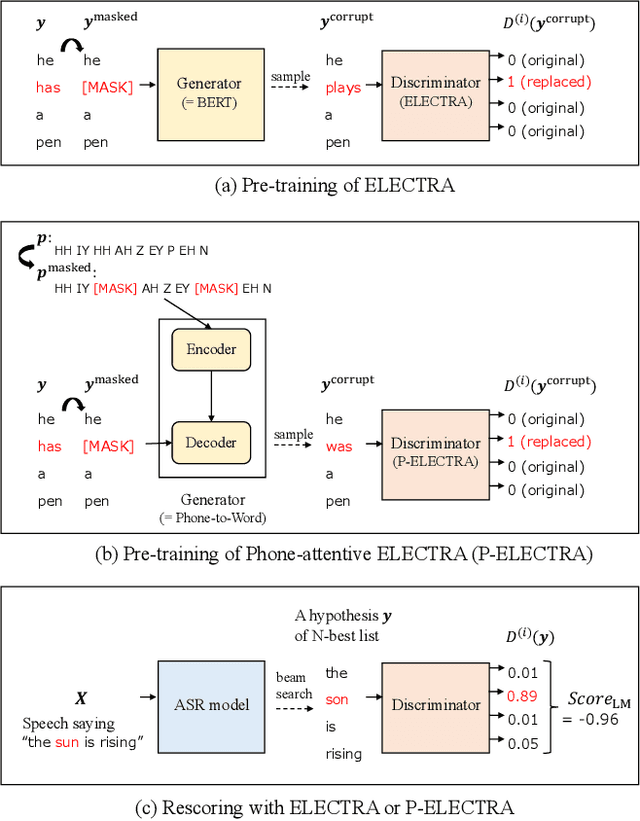

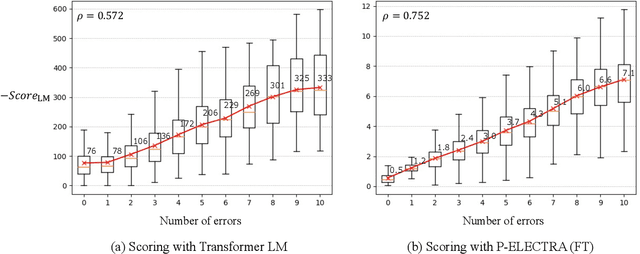
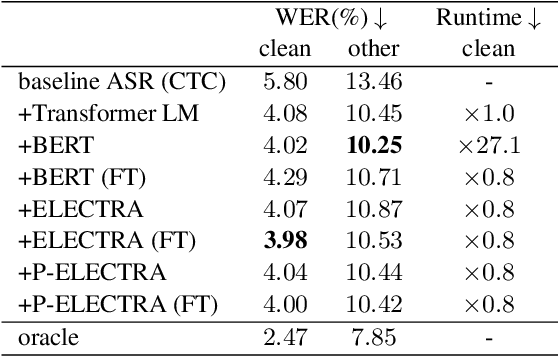
In automatic speech recognition (ASR) rescoring, the hypothesis with the fewest errors should be selected from the n-best list using a language model (LM). However, LMs are usually trained to maximize the likelihood of correct word sequences, not to detect ASR errors. We propose an ASR rescoring method for directly detecting errors with ELECTRA, which is originally a pre-training method for NLP tasks. ELECTRA is pre-trained to predict whether each word is replaced by BERT or not, which can simulate ASR error detection on large text corpora. To make this pre-training closer to ASR error detection, we further propose an extended version of ELECTRA called phone-attentive ELECTRA (P-ELECTRA). In the pre-training of P-ELECTRA, each word is replaced by a phone-to-word conversion model, which leverages phone information to generate acoustically similar words. Since our rescoring method is optimized for detecting errors, it can also be used for word-level confidence estimation. Experimental evaluations on the Librispeech and TED-LIUM2 corpora show that our rescoring method with ELECTRA is competitive with conventional rescoring methods with faster inference. ELECTRA also performs better in confidence estimation than BERT because it can learn to detect inappropriate words not only in fine-tuning but also in pre-training.
Distilling the Knowledge of BERT for Sequence-to-Sequence ASR
Aug 09, 2020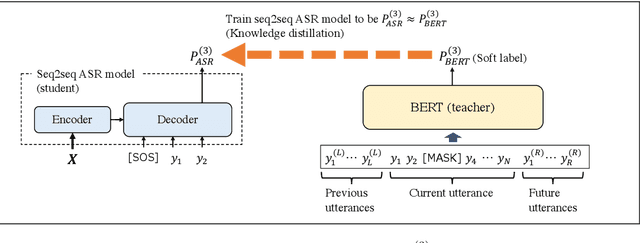
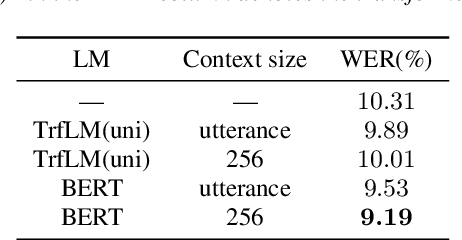
Attention-based sequence-to-sequence (seq2seq) models have achieved promising results in automatic speech recognition (ASR). However, as these models decode in a left-to-right way, they do not have access to context on the right. We leverage both left and right context by applying BERT as an external language model to seq2seq ASR through knowledge distillation. In our proposed method, BERT generates soft labels to guide the training of seq2seq ASR. Furthermore, we leverage context beyond the current utterance as input to BERT. Experimental evaluations show that our method significantly improves the ASR performance from the seq2seq baseline on the Corpus of Spontaneous Japanese (CSJ). Knowledge distillation from BERT outperforms that from a transformer LM that only looks at left context. We also show the effectiveness of leveraging context beyond the current utterance. Our method outperforms other LM application approaches such as n-best rescoring and shallow fusion, while it does not require extra inference cost.
Generative Adversarial Training Data Adaptation for Very Low-resource Automatic Speech Recognition
May 19, 2020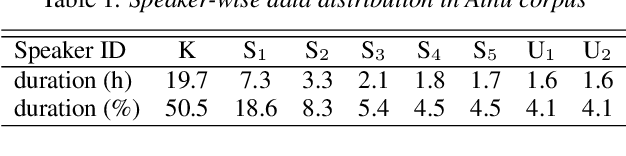
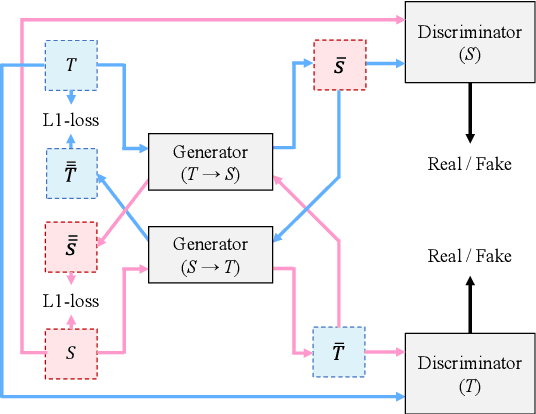


It is important to transcribe and archive speech data of endangered languages for preserving heritages of verbal culture and automatic speech recognition (ASR) is a powerful tool to facilitate this process. However, since endangered languages do not generally have large corpora with many speakers, the performance of ASR models trained on them are considerably poor in general. Nevertheless, we are often left with a lot of recordings of spontaneous speech data that have to be transcribed. In this work, for mitigating this speaker sparsity problem, we propose to convert the whole training speech data and make it sound like the test speaker in order to develop a highly accurate ASR system for this speaker. For this purpose, we utilize a CycleGAN-based non-parallel voice conversion technology to forge a labeled training data that is close to the test speaker's speech. We evaluated this speaker adaptation approach on two low-resource corpora, namely, Ainu and Mboshi. We obtained 35-60% relative improvement in phone error rate on the Ainu corpus, and 40% relative improvement was attained on the Mboshi corpus. This approach outperformed two conventional methods namely unsupervised adaptation and multilingual training with these two corpora.
Speech Corpus of Ainu Folklore and End-to-end Speech Recognition for Ainu Language
Feb 19, 2020


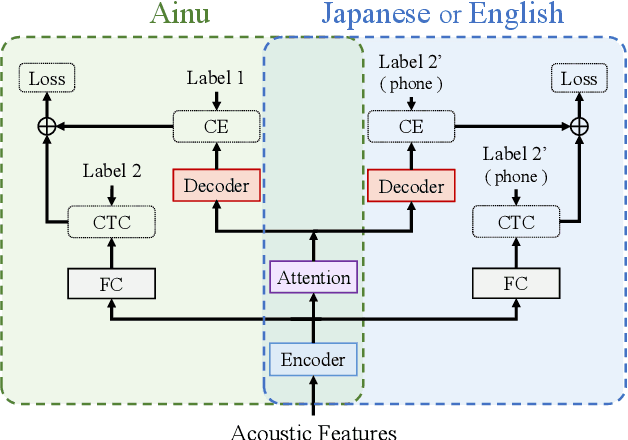
Ainu is an unwritten language that has been spoken by Ainu people who are one of the ethnic groups in Japan. It is recognized as critically endangered by UNESCO and archiving and documentation of its language heritage is of paramount importance. Although a considerable amount of voice recordings of Ainu folklore has been produced and accumulated to save their culture, only a quite limited parts of them are transcribed so far. Thus, we started a project of automatic speech recognition (ASR) for the Ainu language in order to contribute to the development of annotated language archives. In this paper, we report speech corpus development and the structure and performance of end-to-end ASR for Ainu. We investigated four modeling units (phone, syllable, word piece, and word) and found that the syllable-based model performed best in terms of both word and phone recognition accuracy, which were about 60% and over 85% respectively in speaker-open condition. Furthermore, word and phone accuracy of 80% and 90% has been achieved in a speaker-closed setting. We also found out that a multilingual ASR training with additional speech corpora of English and Japanese further improves the speaker-open test accuracy.
Improving OOV Detection and Resolution with External Language Models in Acoustic-to-Word ASR
Sep 22, 2019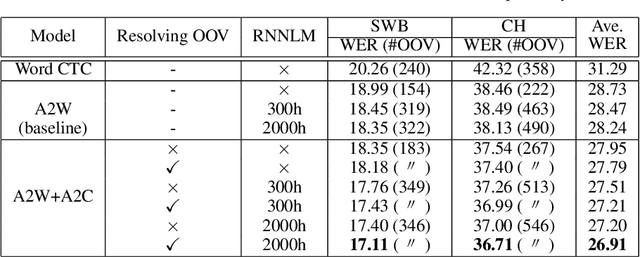
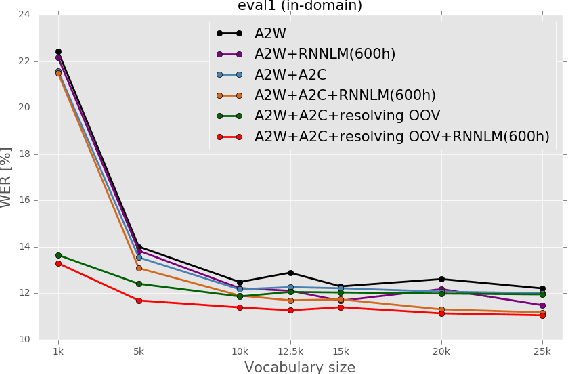


Acoustic-to-word (A2W) end-to-end automatic speech recognition (ASR) systems have attracted attention because of an extremely simplified architecture and fast decoding. To alleviate data sparseness issues due to infrequent words, the combination with an acoustic-to-character (A2C) model is investigated. Moreover, the A2C model can be used to recover out-of-vocabulary (OOV) words that are not covered by the A2W model, but this requires accurate detection of OOV words. A2W models learn contexts with both acoustic and transcripts; therefore they tend to falsely recognize OOV words as words in the vocabulary. In this paper, we tackle this problem by using external language models (LM), which are trained only with transcriptions and have better linguistic information to detect OOV words. The A2C model is used to resolve these OOV words. Experimental evaluations show that external LMs have the effects of not only reducing errors but also increasing the number of detected OOV words, and the proposed method significantly improves performances in English conversational and Japanese lecture corpora, especially for out-of-domain scenario. We also investigate the impact of the vocabulary size of A2W models and the data size for training LMs. Moreover, our approach can reduce the vocabulary size several times with marginal performance degradation.