 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-autoregressive Error Correction for CTC-based ASR with Phone-conditioned Masked LM
Sep 08, 2022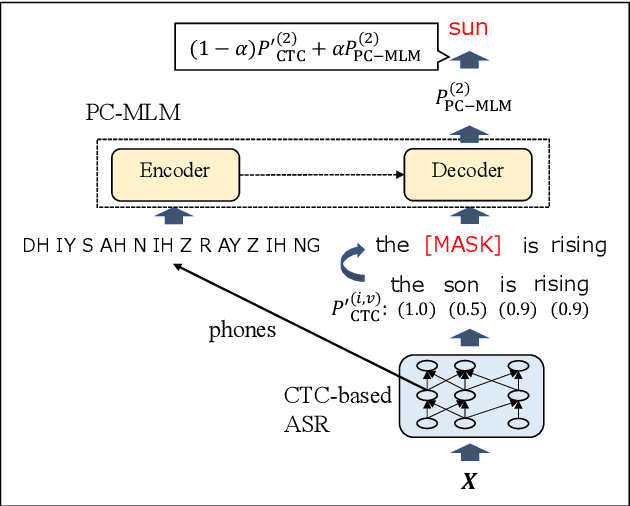
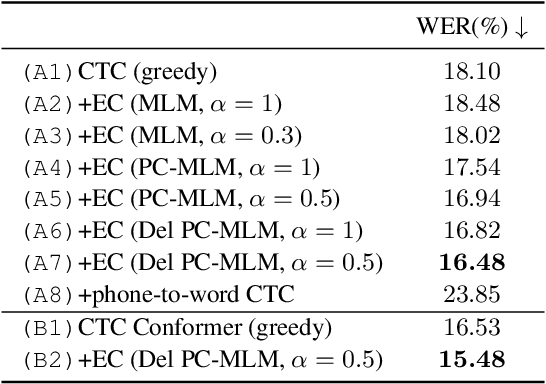
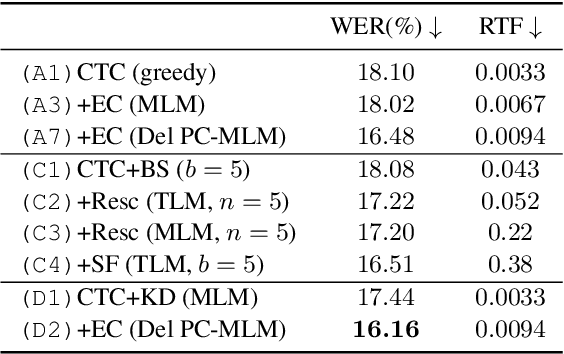
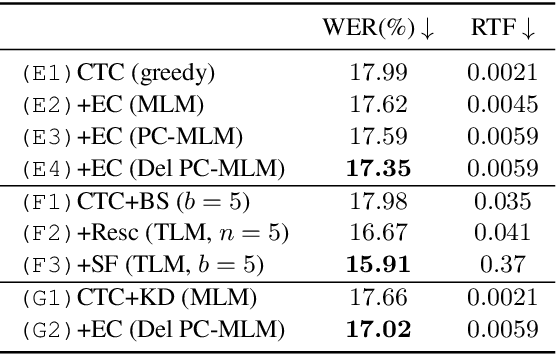
Connectionist temporal classification (CTC) -based models are attractive in automatic speech recognition (ASR) because of their non-autoregressive nature. To take advantage of text-only data, language model (LM) integration approaches such as rescoring and shallow fusion have been widely used for CTC. However, they lose CTC's non-autoregressive nature because of the need for beam search, which slows down the inference speed. In this study, we propose an error correction method with phone-conditioned masked LM (PC-MLM). In the proposed method, less confident word tokens in a greedy decoded output from CTC are masked. PC-MLM then predicts these masked word tokens given unmasked words and phones supplementally predicted from CTC. We further extend it to Deletable PC-MLM in order to address insertion errors. Since both CTC and PC-MLM are non-autoregressive models, the method enables fast LM integration. Experimental evaluations on the Corpus of Spontaneous Japanese (CSJ) and TED-LIUM2 in domain adaptation setting shows that our proposed method outperformed rescoring and shallow fusion in terms of inference speed, and also in terms of recognition accuracy on CSJ.
Distilling the Knowledge of BERT for Sequence-to-Sequence ASR
Aug 09, 2020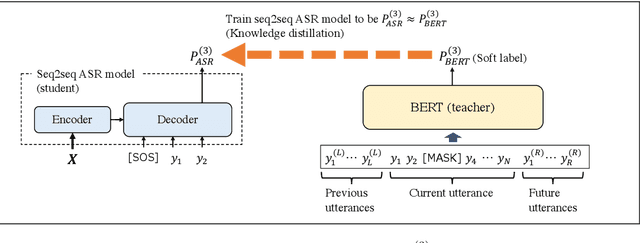
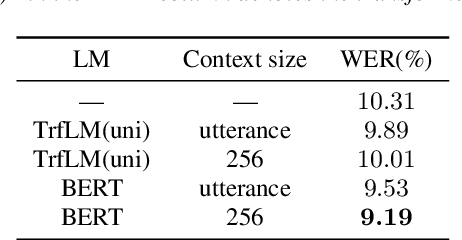
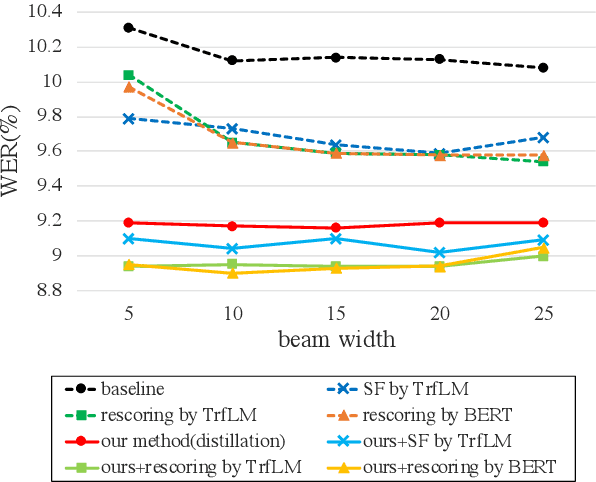
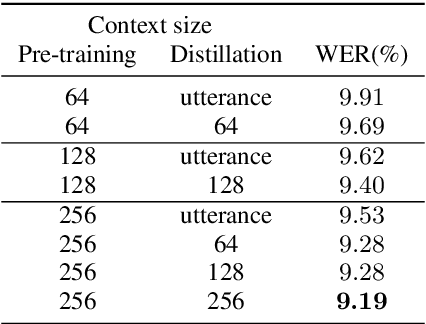
Attention-based sequence-to-sequence (seq2seq) models have achieved promising results in automatic speech recognition (ASR). However, as these models decode in a left-to-right way, they do not have access to context on the right. We leverage both left and right context by applying BERT as an external language model to seq2seq ASR through knowledge distillation. In our proposed method, BERT generates soft labels to guide the training of seq2seq ASR. Furthermore, we leverage context beyond the current utterance as input to BERT. Experimental evaluations show that our method significantly improves the ASR performance from the seq2seq baseline on the Corpus of Spontaneous Japanese (CSJ). Knowledge distillation from BERT outperforms that from a transformer LM that only looks at left context. We also show the effectiveness of leveraging context beyond the current utterance. Our method outperforms other LM application approaches such as n-best rescoring and shallow fusion, while it does not require extra inference cost.
End-to-end speech-to-dialog-act recognition
Apr 23, 2020


Spoken language understanding, which extracts intents and/or semantic concepts in utterances, is conventionally formulated as a post-processing of automatic speech recognition. It is usually trained with oracle transcripts, but needs to deal with errors by ASR. Moreover, there are acoustic features which are related with intents but not represented with the transcripts. In this paper, we present an end-to-end model which directly converts speech into dialog acts without the deterministic transcription process. In the proposed model, the dialog act recognition network is conjunct with an acoustic-to-word ASR model at its latent layer before the softmax layer, which provides a distributed representation of word-level ASR decoding information. Then, the entire network is fine-tuned in an end-to-end manner. This allows for stable training as well as robustness against ASR errors. The model is further extended to conduct DA segmentation jointly. Evaluations with the Switchboard corpus demonstrate that the proposed method significantly improves dialog act recognition accuracy from the conventional pipeline framework.
Speech Corpus of Ainu Folklore and End-to-end Speech Recognition for Ainu Language
Feb 19, 2020


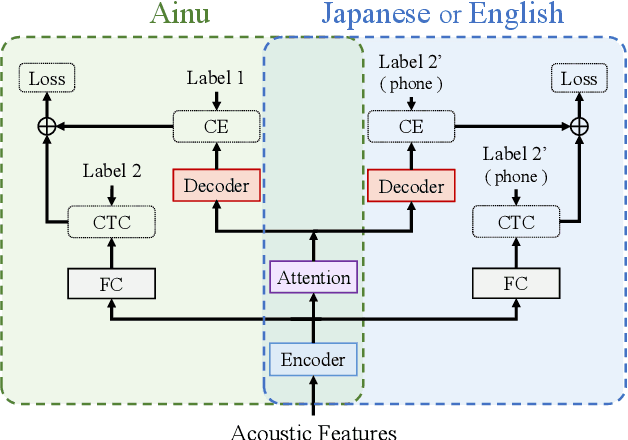
Ainu is an unwritten language that has been spoken by Ainu people who are one of the ethnic groups in Japan. It is recognized as critically endangered by UNESCO and archiving and documentation of its language heritage is of paramount importance. Although a considerable amount of voice recordings of Ainu folklore has been produced and accumulated to save their culture, only a quite limited parts of them are transcribed so far. Thus, we started a project of automatic speech recognition (ASR) for the Ainu language in order to contribute to the development of annotated language archives. In this paper, we report speech corpus development and the structure and performance of end-to-end ASR for Ainu. We investigated four modeling units (phone, syllable, word piece, and word) and found that the syllable-based model performed best in terms of both word and phone recognition accuracy, which were about 60% and over 85% respectively in speaker-open condition. Furthermore, word and phone accuracy of 80% and 90% has been achieved in a speaker-closed setting. We also found out that a multilingual ASR training with additional speech corpora of English and Japanese further improves the speaker-open test accuracy.