 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving OOV Detection and Resolution with External Language Models in Acoustic-to-Word ASR
Paper and Code
Sep 22, 2019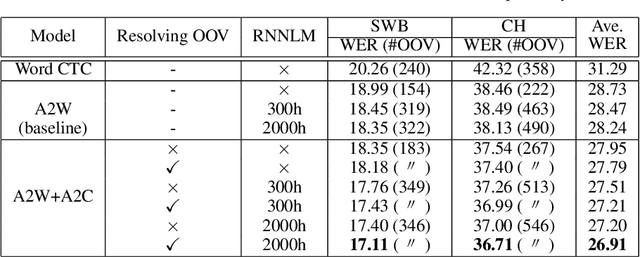
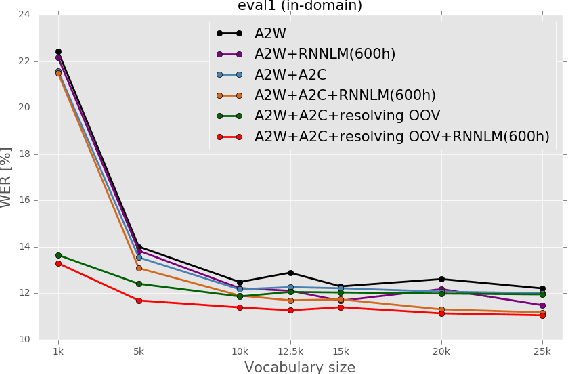


Acoustic-to-word (A2W) end-to-end automatic speech recognition (ASR) systems have attracted attention because of an extremely simplified architecture and fast decoding. To alleviate data sparseness issues due to infrequent words, the combination with an acoustic-to-character (A2C) model is investigated. Moreover, the A2C model can be used to recover out-of-vocabulary (OOV) words that are not covered by the A2W model, but this requires accurate detection of OOV words. A2W models learn contexts with both acoustic and transcripts; therefore they tend to falsely recognize OOV words as words in the vocabulary. In this paper, we tackle this problem by using external language models (LM), which are trained only with transcriptions and have better linguistic information to detect OOV words. The A2C model is used to resolve these OOV words. Experimental evaluations show that external LMs have the effects of not only reducing errors but also increasing the number of detected OOV words, and the proposed method significantly improves performances in English conversational and Japanese lecture corpora, especially for out-of-domain scenario. We also investigate the impact of the vocabulary size of A2W models and the data size for training LMs. Moreover, our approach can reduce the vocabulary size several times with marginal performance degradation.