 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Pure Textual Reasoning for Blind Image Quality Assessment
Jan 05, 2026Textual reasoning has recently been widely adopted in Blind Image Quality Assessment (BIQA). However, it remains unclear how textual information contributes to quality prediction and to what extent text can represent the score-related image contents. This work addresses these questions from an information-flow perspective by comparing existing BIQA models with three paradigms designed to learn the image-text-score relationship: Chain-of-Thought, Self-Consistency, and Autoencoder. Our experiments show that the score prediction performance of the existing model significantly drops when only textual information is used for prediction. Whereas the Chain-of-Thought paradigm introduces little improvement in BIQA performance, the Self-Consistency paradigm significantly reduces the gap between image- and text-conditioned predictions, narrowing the PLCC/SRCC difference to 0.02/0.03. The Autoencoder-like paradigm is less effective in closing the image-text gap, yet it reveals a direction for further optimization. These findings provide insights into how to improve the textual reasoning for BIQA and high-level vision tasks.
Guiding Perception-Reasoning Closer to Human in Blind Image Quality Assessment
Dec 18, 2025Humans assess image quality through a perception-reasoning cascade, integrating sensory cues with implicit reasoning to form self-consistent judgments. In this work, we investigate how a model can acquire both human-like and self-consistent reasoning capability for blind image quality assessment (BIQA). We first collect human evaluation data that capture several aspects of human perception-reasoning pipeline. Then, we adopt reinforcement learning, using human annotations as reward signals to guide the model toward human-like perception and reasoning. To enable the model to internalize self-consistent reasoning capability, we design a reward that drives the model to infer the image quality purely from self-generated descriptions. Empirically, our approach achieves score prediction performance comparable to state-of-the-art BIQA systems under general metrics, including Pearson and Spearman correlation coefficients. In addition to the rating score, we assess human-model alignment using ROUGE-1 to measure the similarity between model-generated and human perception-reasoning chains. On over 1,000 human-annotated samples, our model reaches a ROUGE-1 score of 0.512 (cf. 0.443 for baseline), indicating substantial coverage of human explanations and marking a step toward human-like interpretable reasoning in BIQA.
Building Reasonable Inference for Vision-Language Models in Blind Image Quality Assessment
Dec 10, 2025Recent progress in BIQA has been driven by VLMs, whose semantic reasoning abilities suggest that they might extract visual features, generate descriptive text, and infer quality in a human-like manner. However, these models often produce textual descriptions that contradict their final quality predictions, and the predicted scores can change unstably during inference - behaviors not aligned with human reasoning. To understand these issues, we analyze the factors that cause contradictory assessments and instability. We first estimate the relationship between the final quality predictions and the generated visual features, finding that the predictions are not fully grounded in the features and that the logical connection between them is weak. Moreover, decoding intermediate VLM layers shows that the model frequently relies on a limited set of candidate tokens, which contributes to prediction instability. To encourage more human-like reasoning, we introduce a two-stage tuning method that explicitly separates visual perception from quality inference. In the first stage, the model learns visual features; in the second, it infers quality solely from these features. Experiments on SPAQ and KONIQ demonstrate that our approach reduces prediction instability from 22.00% to 12.39% and achieves average gains of 0.3124/0.3507 in SRCC/PLCC across LIVE, CSIQ, SPAQ, and KONIQ compared to the baseline. Further analyses show that our method improves both stability and the reliability of the inference process.
* Accepted to the ICONIP (International Conference on Neural Information Processing), 2025
Investigate the Low-level Visual Perception in Vision-Language based Image Quality Assessment
Dec 10, 2025Recent advances in Image Quality Assessment (IQA) have leveraged Multi-modal Large Language Models (MLLMs) to generate descriptive explanations. However, despite their strong visual perception modules, these models often fail to reliably detect basic low-level distortions such as blur, noise, and compression, and may produce inconsistent evaluations across repeated inferences. This raises an essential question: do MLLM-based IQA systems truly perceive the visual features that matter? To examine this issue, we introduce a low-level distortion perception task that requires models to classify specific distortion types. Our component-wise analysis shows that although MLLMs are structurally capable of representing such distortions, they tend to overfit training templates, leading to biases in quality scoring. As a result, critical low-level features are weakened or lost during the vision-language alignment transfer stage. Furthermore, by computing the semantic distance between visual features and corresponding semantic tokens before and after component-wise fine-tuning, we show that improving the alignment of the vision encoder dramatically enhances distortion recognition accuracy, increasing it from 14.92% to 84.43%. Overall, these findings indicate that incorporating dedicated constraints on the vision encoder can strengthen text-explainable visual representations and enable MLLM-based pipelines to produce more coherent and interpretable reasoning in vision-centric tasks.
Modelling Human Visual Motion Processing with Trainable Motion Energy Sensing and a Self-attention Network for Adaptive Motion Integration
May 16, 2023



Visual motion processing is essential for organisms to perceive and interact with dynamic environments. Despite extensive research in cognitive neuroscience, image-computable models that can extract informative motion flow from natural scenes in a manner consistent with human visual processing have yet to be established. Meanwhile, recent advancements in computer vision (CV), propelled by deep learning, have led to significant progress in optical flow estimation, a task closely related to motion perception. Here we propose an image-computable model of human motion perception by bridging the gap between human and CV models. Specifically, we introduce a novel two-stage approach that combines trainable motion energy sensing with a recurrent self-attention network for adaptive motion integration and segregation. This model architecture aims to capture the computations in V1-MT, the core structure for motion perception in the biological visual system. In silico neurophysiology reveals that our model's unit responses are similar to mammalian neural recordings regarding motion pooling and speed tuning. The proposed model can also replicate human responses to a range of stimuli examined in past psychophysical studies. The experimental results on the Sintel benchmark demonstrate that our model predicts human responses better than the ground truth, whereas the CV models show the opposite. Further partial correlation analysis indicates our model outperforms several state-of-the-art CV models in explaining the human responses that deviate from the ground truth. Our study provides a computational architecture consistent with human visual motion processing, although the physiological correspondence may not be exact.
Unsupervised Learning Optical Flow in Multi-frame Dynamic Environment Using Temporal Dynamic Modeling
Apr 14, 2023

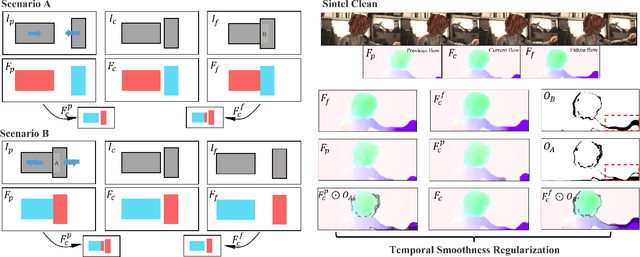

For visual estimation of optical flow, a crucial function for many vision tasks, unsupervised learning, using the supervision of view synthesis has emerged as a promising alternative to supervised methods, since ground-truth flow is not readily available in many cases. However, unsupervised learning is likely to be unstable when pixel tracking is lost due to occlusion and motion blur, or the pixel matching is impaired due to variation in image content and spatial structure over time. In natural environments, dynamic occlusion or object variation is a relatively slow temporal process spanning several frames. We, therefore, explore the optical flow estimation from multiple-frame sequences of dynamic scenes, whereas most of the existing unsupervised approaches are based on temporal static models. We handle the unsupervised optical flow estimation with a temporal dynamic model by introducing a spatial-temporal dual recurrent block based on the predictive coding structure, which feeds the previous high-level motion prior to the current optical flow estimator. Assuming temporal smoothness of optical flow, we use motion priors of the adjacent frames to provide more reliable supervision of the occluded regions. To grasp the essence of challenging scenes, we simulate various scenarios across long sequences, including dynamic occlusion, content variation, and spatial variation, and adopt self-supervised distillation to make the model understand the object's motion patterns in a prolonged dynamic environment. Experiments on KITTI 2012, KITTI 2015, Sintel Clean, and Sintel Final datasets demonstrate the effectiveness of our methods on unsupervised optical flow estimation. The proposal achieves state-of-the-art performance with advantages in memory overhead.
Optimizing Facial Expressions of an Android Robot Effectively: a Bayesian Optimization Approach
Jan 13, 2023Expressing various facial emotions is an important social ability for efficient communication between humans. A key challenge in human-robot interaction research is providing androids with the ability to make various human-like facial expressions for efficient communication with humans. The android Nikola, we have developed, is equipped with many actuators for facial muscle control. While this enables Nikola to simulate various human expressions, it also complicates identification of the optimal parameters for producing desired expressions. Here, we propose a novel method that automatically optimizes the facial expressions of our android. We use a machine vision algorithm to evaluate the magnitudes of seven basic emotions, and employ the Bayesian Optimization algorithm to identify the parameters that produce the most convincing facial expressions. Evaluations by naive human participants demonstrate that our method improves the rated strength of the android's facial expressions of anger, disgust, sadness, and surprise compared with the previous method that relied on Ekman's theory and parameter adjustments by a human expert.