 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHDeep: Mental Health Disorder Detection System based on Body-Area and Deep Neural Networks
Feb 20, 2021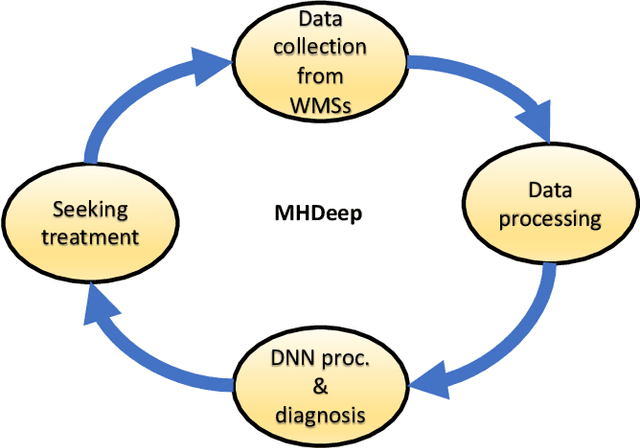
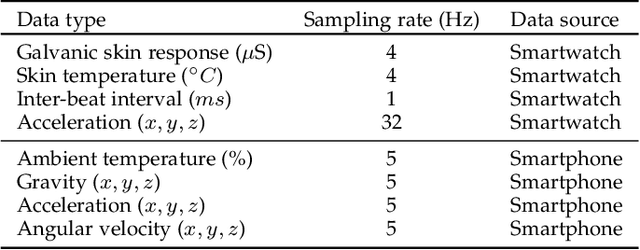
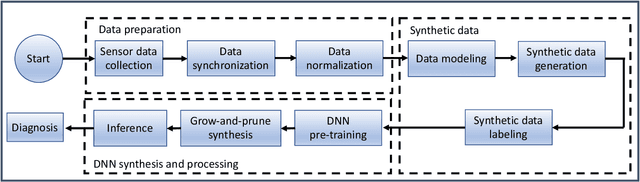

Mental health problems impact quality of life of millions of people around the world. However, diagnosis of mental health disorders is a challenging problem that often relies on self-reporting by patients about their behavioral patterns. Therefore, there is a need for new strategies for diagnosis of mental health problems. The recent introduction of body-area networks consisting of a plethora of accurate sensors embedded in smartwatches and smartphones and deep neural networks (DNNs) points towards a possible solution. However, disease diagnosis based on WMSs and DNNs, and their deployment on edge devices, remains a challenging problem. To this end, we propose a framework called MHDeep that utilizes commercially available WMSs and efficient DNN models to diagnose three important mental health disorders: schizoaffective, major depressive, and bipolar. MHDeep uses eight different categories of data obtained from sensors integrated in a smartwatch and smartphone. Due to limited available data, MHDeep uses a synthetic data generation module to augment real data with synthetic data drawn from the same probability distribution. We use the synthetic dataset to pre-train the DNN models, thus imposing a prior on the weights. We use a grow-and-prune DNN synthesis approach to learn both the architecture and weights during the training process. We use three different data partitions to evaluate the MHDeep models trained with data collected from 74 individuals. We conduct data instance level and patient level evaluations. MHDeep achieves an average test accuracy of 90.4%, 87.3%, and 82.4%, respectively, for classifications between healthy instances and schizoaffective disorder instances, major depressive disorder instances, and bipolar disorder instances. At the patient level, MHDeep DNNs achieve an accuracy of 100%, 100%, and 90.0% for the three mental health disorders, respectively.
TUTOR: Training Neural Networks Using Decision Rules as Model Priors
Oct 13, 2020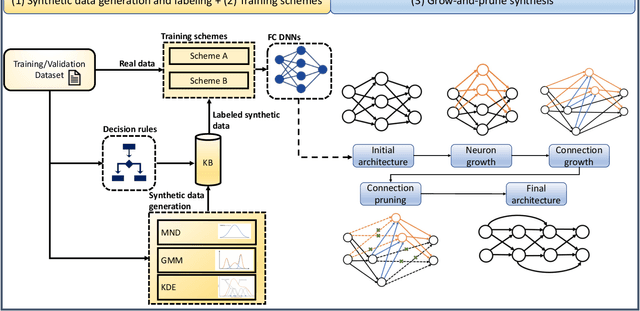


The human brain has the ability to carry out new tasks with limited experience. It utilizes prior learning experiences to adapt the solution strategy to new domains. On the other hand, deep neural networks (DNNs) generally need large amounts of data and computational resources for training. However, this requirement is not met in many settings. To address these challenges, we propose the TUTOR DNN synthesis framework. TUTOR targets non-image datasets. It synthesizes accurate DNN models with limited available data, and reduced memory and computational requirements. It consists of three sequential steps: (1) drawing synthetic data from the same probability distribution as the training data and labeling the synthetic data based on a set of rules extracted from the real dataset, (2) use of two training schemes that combine synthetic data and training data to learn DNN weights, and (3) employing a grow-and-prune synthesis paradigm to learn both the weights and the architecture of the DNN to reduce model size while ensuring its accuracy. We show that in comparison with fully-connected DNNs, on an average TUTOR reduces the need for data by 6.0x (geometric mean), improves accuracy by 3.6%, and reduces the number of parameters (floating-point operations) by 4.7x (4.3x) (geometric mean). Thus, TUTOR is a less data-hungry, accurate, and efficient DNN synthesis framework.
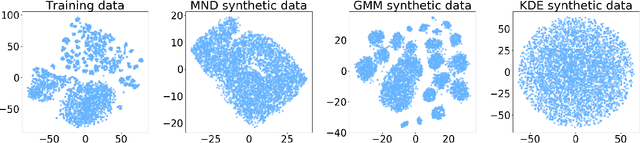
CovidDeep: SARS-CoV-2/COVID-19 Test Based on Wearable Medical Sensors and Efficient Neural Networks
Jul 28, 2020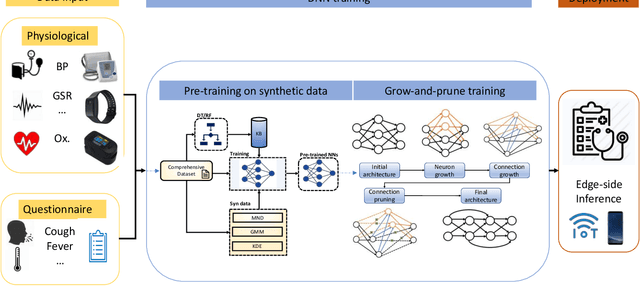
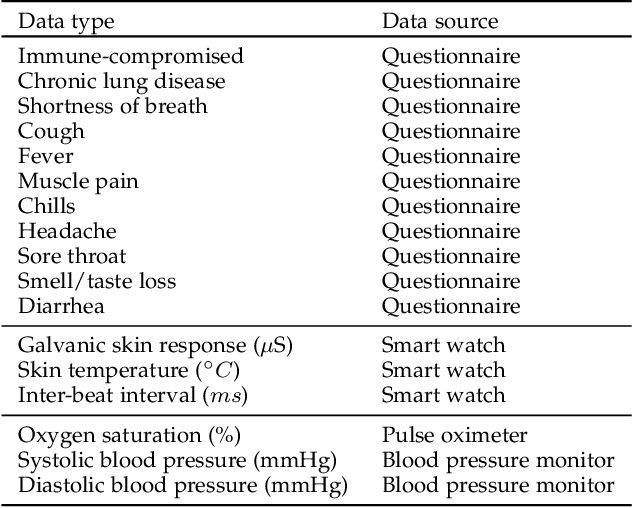
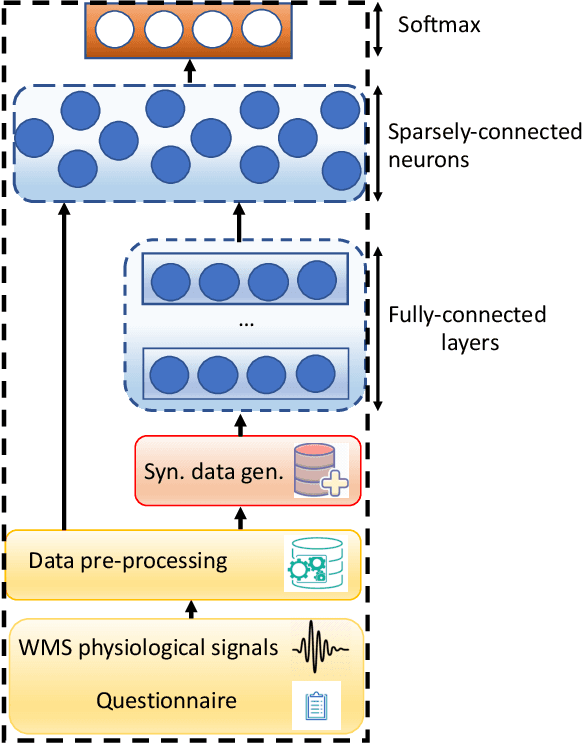
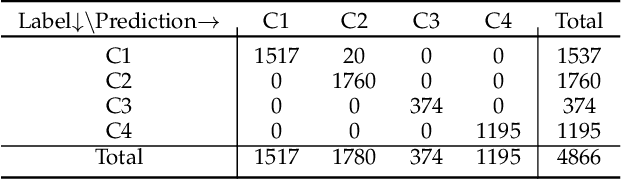
The novel coronavirus (SARS-CoV-2) has led to a pandemic. Due to its highly contagious nature, it has spread rapidly, resulting in major disruption to public health. In addition, it has also had a severe negative impact on the world economy. As a result, it is widely recognized now that widespread testing is key to containing the spread of the disease and opening up the economy. However, the current testing regime has been unable to keep up with testing demands. Hence, there is a need for an alternative approach for repeated large-scale testing of COVID-19. The emergence of wearable medical sensors (WMSs) and novel machine learning methods, such as deep neural networks (DNNs), points to a promising approach to address this challenge. WMSs enable continuous and user-transparent monitoring of the physiological signals. However, disease detection based on WMSs/DNNs and their deployment on resource-constrained edge devices remain challenging problems. In this work, we propose CovidDeep, a framework that combines efficient DNNs with commercially available WMSs for pervasive testing of the coronavirus. We collected data from 87 individuals, spanning four cohorts including healthy, asymptomatic (but SARS-CoV-2-positive) as well as moderately and severely symptomatic COVID-19 patients. We trained DNNs on various subsets of the features extracted from six WMS and questionnaire categories to perform ablation studies to determine which subsets are most efficacious in terms of test accuracy for a four-way classification. The highest test accuracy obtained was 99.4%. Since different WMS subsets may be more accessible (in terms of cost, availability, etc.) to different sets of people, we hope these DNN models will provide users with ample flexibility. The resultant DNNs can be easily deployed on edge devices, e.g., smartwatch or smartphone, which also has the benefit of preserving patient privacy.
STEERAGE: Synthesis of Neural Networks Using Architecture Search and Grow-and-Prune Methods
Dec 12, 2019
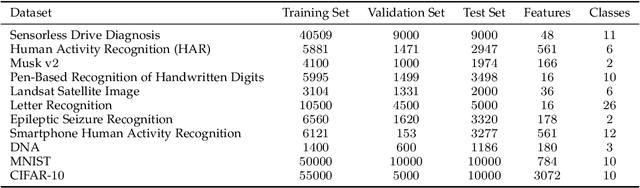

Neural networks (NNs) have been successfully deployed in many applications. However, architectural design of these models is still a challenging problem. Moreover, neural networks are known to have a lot of redundancy. This increases the computational cost of inference and poses an obstacle to deployment on Internet-of-Thing sensors and edge devices. To address these challenges, we propose the STEERAGE synthesis methodology. It consists of two complementary approaches: efficient architecture search, and grow-and-prune NN synthesis. The first step, covered in a global search module, uses an accuracy predictor to efficiently navigate the architectural search space. The predictor is built using boosted decision tree regression, iterative sampling, and efficient evolutionary search. The second step involves local search. By using various grow-and-prune methodologies for synthesizing convolutional and feed-forward NNs, it reduces the network redundancy, while boosting its performance. We have evaluated STEERAGE performance on various datasets, including MNIST and CIFAR-10. On MNIST dataset, our CNN architecture achieves an error rate of 0.66%, with 8.6x fewer parameters compared to the LeNet-5 baseline. For the CIFAR-10 dataset, we used the ResNet architectures as the baseline. Our STEERAGE-synthesized ResNet-18 has a 2.52% accuracy improvement over the original ResNet-18, 1.74% over ResNet-101, and 0.16% over ResNet-1001, while having comparable number of parameters and FLOPs to the original ResNet-18. This shows that instead of just increasing the number of layers to increase accuracy, an alternative is to use a better NN architecture with fewer layers. In addition, STEERAGE achieves an error rate of just 3.86% with a variant of ResNet architecture with 40 layers. To the best of our knowledge, this is the highest accuracy obtained by ResNet-based architectures on the CIFAR-10 dataset.
SCANN: Synthesis of Compact and Accurate Neural Networks
Apr 19, 2019
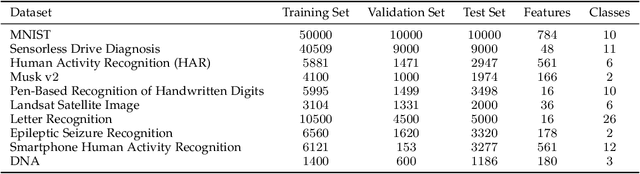
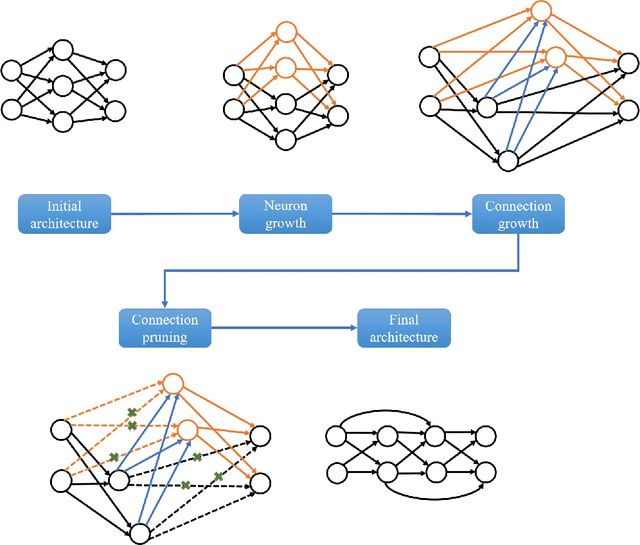
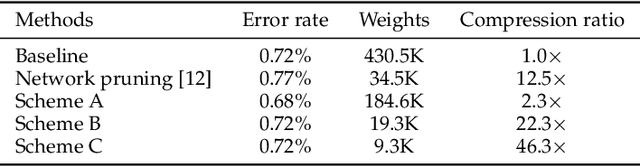
Artificial neural networks (ANNs) have become the driving force behind recent artificial intelligence (AI) research. An important problem with implementing a neural network is the design of its architecture. Typically, such an architecture is obtained manually by exploring its hyperparameter space and kept fixed during training. This approach is both time-consuming and inefficient. Furthermore, modern neural networks often contain millions of parameters, whereas many applications require small inference models. Also, while ANNs have found great success in big-data applications, there is also significant interest in using ANNs for medium- and small-data applications that can be run on energy-constrained edge devices. To address these challenges, we propose a neural network synthesis methodology (SCANN) that can generate very compact neural networks without loss in accuracy for small and medium-size datasets. We also use dimensionality reduction methods to reduce the feature size of the datasets, so as to alleviate the curse of dimensionality. Our final synthesis methodology consists of three steps: dataset dimensionality reduction, neural network compression in each layer, and neural network compression with SCANN. We evaluate SCANN on the medium-size MNIST dataset by comparing our synthesized neural networks to the well-known LeNet-5 baseline. Without any loss in accuracy, SCANN generates a $46.3\times$ smaller network than the LeNet-5 Caffe model. We also evaluate the efficiency of using dimensionality reduction alongside SCANN on nine small to medium-size datasets. Using this methodology enables us to reduce the number of connections in the network by up to $5078.7\times$ (geometric mean: $82.1\times$), with little to no drop in accuracy. We also show that our synthesis methodology yields neural networks that are much better at navigating the accuracy vs. energy efficiency space.