 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTUTOR: Training Neural Networks Using Decision Rules as Model Priors
Paper and Code
Oct 13, 2020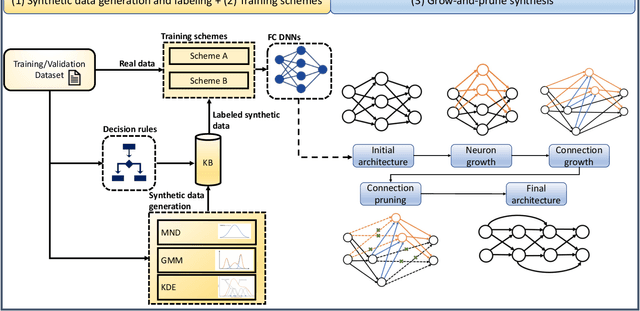

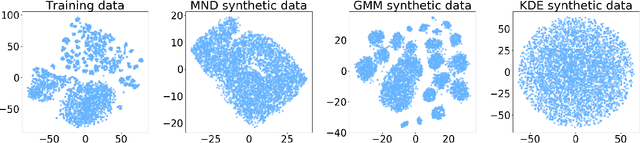

The human brain has the ability to carry out new tasks with limited experience. It utilizes prior learning experiences to adapt the solution strategy to new domains. On the other hand, deep neural networks (DNNs) generally need large amounts of data and computational resources for training. However, this requirement is not met in many settings. To address these challenges, we propose the TUTOR DNN synthesis framework. TUTOR targets non-image datasets. It synthesizes accurate DNN models with limited available data, and reduced memory and computational requirements. It consists of three sequential steps: (1) drawing synthetic data from the same probability distribution as the training data and labeling the synthetic data based on a set of rules extracted from the real dataset, (2) use of two training schemes that combine synthetic data and training data to learn DNN weights, and (3) employing a grow-and-prune synthesis paradigm to learn both the weights and the architecture of the DNN to reduce model size while ensuring its accuracy. We show that in comparison with fully-connected DNNs, on an average TUTOR reduces the need for data by 6.0x (geometric mean), improves accuracy by 3.6%, and reduces the number of parameters (floating-point operations) by 4.7x (4.3x) (geometric mean). Thus, TUTOR is a less data-hungry, accurate, and efficient DNN synthesis framework.