 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
OpenHuEval: Evaluating Large Language Model on Hungarian Specifics
Mar 27, 2025
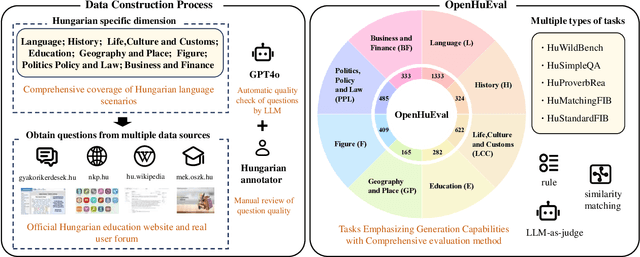


We introduce OpenHuEval, the first benchmark for LLMs focusing on the Hungarian language and specifics. OpenHuEval is constructed from a vast collection of Hungarian-specific materials sourced from multiple origins. In the construction, we incorporated the latest design principles for evaluating LLMs, such as using real user queries from the internet, emphasizing the assessment of LLMs' generative capabilities, and employing LLM-as-judge to enhance the multidimensionality and accuracy of evaluations. Ultimately, OpenHuEval encompasses eight Hungarian-specific dimensions, featuring five tasks and 3953 questions. Consequently, OpenHuEval provides the comprehensive, in-depth, and scientifically accurate assessment of LLM performance in the context of the Hungarian language and its specifics. We evaluated current mainstream LLMs, including both traditional LLMs and recently developed Large Reasoning Models. The results demonstrate the significant necessity for evaluation and model optimization tailored to the Hungarian language and specifics. We also established the framework for analyzing the thinking processes of LRMs with OpenHuEval, revealing intrinsic patterns and mechanisms of these models in non-English languages, with Hungarian serving as a representative example. We will release OpenHuEval at https://github.com/opendatalab/OpenHuEval .
Beyond Pixel-Wise Supervision for Medical Image Segmentation: From Traditional Models to Foundation Models
Apr 20, 2024



Medical image segmentation plays an important role in many image-guided clinical approaches. However, existing segmentation algorithms mostly rely on the availability of fully annotated images with pixel-wise annotations for training, which can be both labor-intensive and expertise-demanding, especially in the medical imaging domain where only experts can provide reliable and accurate annotations. To alleviate this challenge, there has been a growing focus on developing segmentation methods that can train deep models with weak annotations, such as image-level, bounding boxes, scribbles, and points. The emergence of vision foundation models, notably the Segment Anything Model (SAM), has introduced innovative capabilities for segmentation tasks using weak annotations for promptable segmentation enabled by large-scale pre-training. Adopting foundation models together with traditional learning methods has increasingly gained recent interest research community and shown potential for real-world applications. In this paper, we present a comprehensive survey of recent progress on annotation-efficient learning for medical image segmentation utilizing weak annotations before and in the era of foundation models. Furthermore, we analyze and discuss several challenges of existing approaches, which we believe will provide valuable guidance for shaping the trajectory of foundational models to further advance the field of medical image segmentation.
Competitive Ensembling Teacher-Student Framework for Semi-Supervised Left Atrium MRI Segmentation
Oct 21, 2023Semi-supervised learning has greatly advanced medical image segmentation since it effectively alleviates the need of acquiring abundant annotations from experts and utilizes unlabeled data which is much easier to acquire. Among existing perturbed consistency learning methods, mean-teacher model serves as a standard baseline for semi-supervised medical image segmentation. In this paper, we present a simple yet efficient competitive ensembling teacher student framework for semi-supervised for left atrium segmentation from 3D MR images, in which two student models with different task-level disturbances are introduced to learn mutually, while a competitive ensembling strategy is performed to ensemble more reliable information to teacher model. Different from the one-way transfer between teacher and student models, our framework facilitates the collaborative learning procedure of different student models with the guidance of teacher model and motivates different training networks for a competitive learning and ensembling procedure to achieve better performance. We evaluate our proposed method on the public Left Atrium (LA) dataset and it obtains impressive performance gains by exploiting the unlabeled data effectively and outperforms several existing semi-supervised methods.