 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP-DRL: A Synergistic Algorithm-Hardware Framework for Automatic Task Partitioning of Deep Reinforcement Learning on Versal ACAP
Mar 31, 2026Deep reinforcement learning has demonstrated remarkable success across various domains. However, the tight coupling between training and inference processes makes accelerating DRL training an essential challenge for DRL optimization. Two key issues hinder efficient DRL training: (1) the significant variation in computational intensity across different DRL algorithms and even among operations within the same algorithm complicates hardware platform selection, while (2) DRL's wide dynamic range could lead to substantial reward errors with conventional FP16+FP32 mixed-precision quantization. While existing work has primarily focused on accelerating DRL for specific computing units or optimizing inference-stage quantization, we propose AP-DRL to address the above challenges. AP-DRL is an automatic task partitioning framework that harnesses the heterogeneous architecture of AMD Versal ACAP (integrating CPUs, FPGAs, and AI Engines) to accelerate DRL training through intelligent hardware-aware optimization. Our approach begins with bottleneck analysis of CPU, FPGA, and AIE performance across diverse DRL workloads, informing the design principles for AP-DRL's inter-component task partitioning and quantization optimization. The framework then addresses the challenge of platform selection through design space exploration-based profiling and ILP-based partitioning models that match operations to optimal computing units based on their computational characteristics. For the quantization challenge, AP-DRL employs a hardware-aware algorithm coordinating FP32 (CPU), FP16 (FPGA/DSP), and BF16 (AI Engine) operations by leveraging Versal ACAP's native support for these precision formats. Comprehensive experiments indicate that AP-DRL can achieve speedup of up to 4.17$\times$ over programmable logic and up to 3.82$\times$ over AI Engine baselines while maintaining training convergence.
DAPO: Design Structure-Aware Pass Ordering in High-Level Synthesis with Graph Contrastive and Reinforcement Learning
Dec 12, 2025High-Level Synthesis (HLS) tools are widely adopted in FPGA-based domain-specific accelerator design. However, existing tools rely on fixed optimization strategies inherited from software compilations, limiting their effectiveness. Tailoring optimization strategies to specific designs requires deep semantic understanding, accurate hardware metric estimation, and advanced search algorithms -- capabilities that current approaches lack. We propose DAPO, a design structure-aware pass ordering framework that extracts program semantics from control and data flow graphs, employs contrastive learning to generate rich embeddings, and leverages an analytical model for accurate hardware metric estimation. These components jointly guide a reinforcement learning agent to discover design-specific optimization strategies. Evaluations on classic HLS designs demonstrate that our end-to-end flow delivers a 2.36 speedup over Vitis HLS on average.
AaP-ReID: Improved Attention-Aware Person Re-identification
Sep 27, 2023

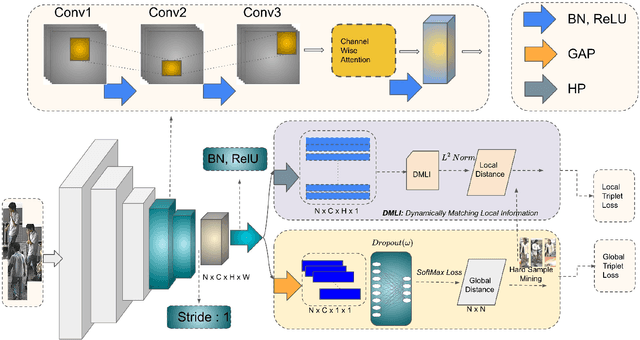
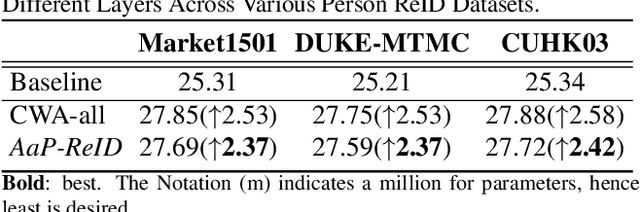
Person re-identification (ReID) is a well-known problem in the field of computer vision. The primary objective is to identify a specific individual within a gallery of images. However, this task is challenging due to various factors, such as pose variations, illumination changes, obstructions, and the presence ofconfusing backgrounds. Existing ReID methods often fail to capture discriminative features (e.g., head, shoes, backpacks) and instead capture irrelevant features when the target is occluded. Motivated by the success of part-based and attention-based ReID methods, we improve AlignedReID++ and present AaP-ReID, a more effective method for person ReID that incorporates channel-wise attention into a ResNet-based architecture. Our method incorporates the Channel-Wise Attention Bottleneck (CWAbottleneck) block and can learn discriminating features by dynamically adjusting the importance ofeach channel in the feature maps. We evaluated Aap-ReID on three benchmark datasets: Market-1501, DukeMTMC-reID, and CUHK03. When compared with state-of-the-art person ReID methods, we achieve competitive results with rank-1 accuracies of 95.6% on Market-1501, 90.6% on DukeMTMC-reID, and 82.4% on CUHK03.
Joint-YODNet: A Light-weight Object Detector for UAVs to Achieve Above 100fps
Sep 27, 2023
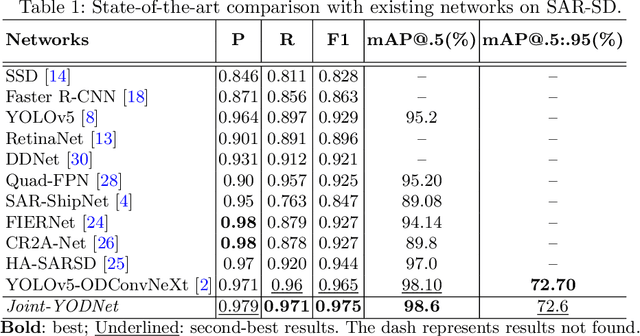
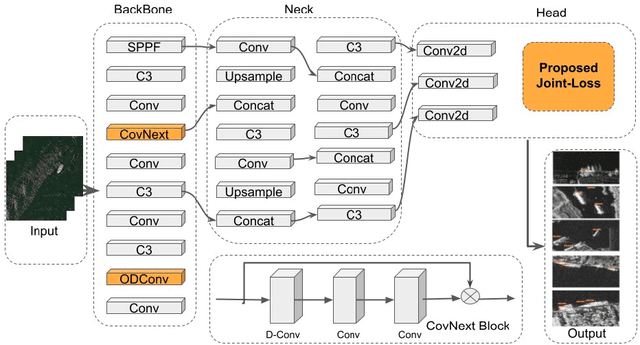

Small object detection via UAV (Unmanned Aerial Vehicle) images captured from drones and radar is a complex task with several formidable challenges. This domain encompasses numerous complexities that impede the accurate detection and localization of small objects. To address these challenges, we propose a novel method called JointYODNet for UAVs to detect small objects, leveraging a joint loss function specifically designed for this task. Our method revolves around the development of a joint loss function tailored to enhance the detection performance of small objects. Through extensive experimentation on a diverse dataset of UAV images captured under varying environmental conditions, we evaluated different variations of the loss function and determined the most effective formulation. The results demonstrate that our proposed joint loss function outperforms existing methods in accurately localizing small objects. Specifically, our method achieves a recall of 0.971, and a F1Score of 0.975, surpassing state-of-the-art techniques. Additionally, our method achieves a mAP@.5(%) of 98.6, indicating its robustness in detecting small objects across varying scales
YOLORe-IDNet: An Efficient Multi-Camera System for Person-Tracking
Sep 23, 2023

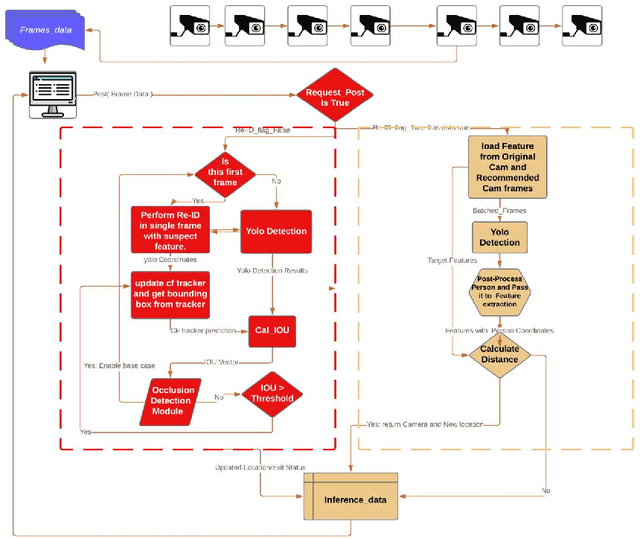
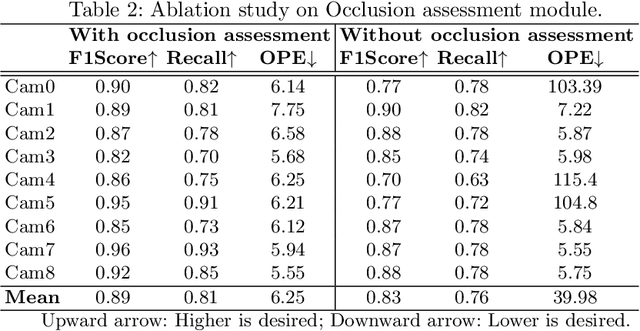
The growing need for video surveillance in public spaces has created a demand for systems that can track individuals across multiple cameras feeds in real-time. While existing tracking systems have achieved impressive performance using deep learning models, they often rely on pre-existing images of suspects or historical data. However, this is not always feasible in cases where suspicious individuals are identified in real-time and without prior knowledge. We propose a person-tracking system that combines correlation filters and Intersection Over Union (IOU) constraints for robust tracking, along with a deep learning model for cross-camera person re-identification (Re-ID) on top of YOLOv5. The proposed system quickly identifies and tracks suspect in real-time across multiple cameras and recovers well after full or partial occlusion, making it suitable for security and surveillance applications. It is computationally efficient and achieves a high F1-Score of 79% and an IOU of 59% comparable to existing state-of-the-art algorithms, as demonstrated in our evaluation on a publicly available OTB-100 dataset. The proposed system offers a robust and efficient solution for the real-time tracking of individuals across multiple camera feeds. Its ability to track targets without prior knowledge or historical data is a significant improvement over existing systems, making it well-suited for public safety and surveillance applications.
Hard-ODT: Hardware-Friendly Online Decision Tree Learning Algorithm and System
Dec 11, 2020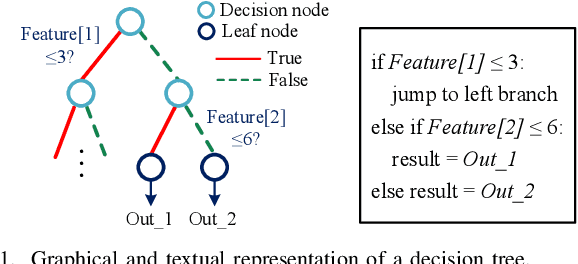
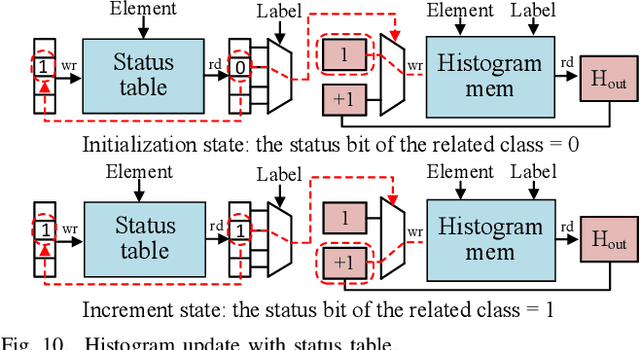
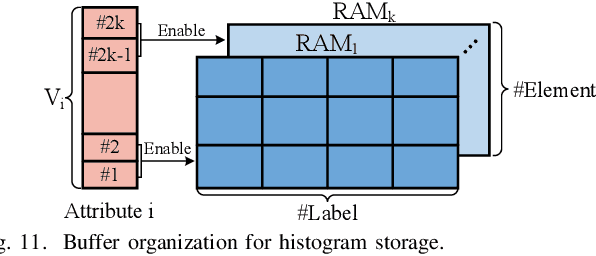
Decision trees are machine learning models commonly used in various application scenarios. In the era of big data, traditional decision tree induction algorithms are not suitable for learning large-scale datasets due to their stringent data storage requirement. Online decision tree learning algorithms have been devised to tackle this problem by concurrently training with incoming samples and providing inference results. However, even the most up-to-date online tree learning algorithms still suffer from either high memory usage or high computational intensity with dependency and long latency, making them challenging to implement in hardware. To overcome these difficulties, we introduce a new quantile-based algorithm to improve the induction of the Hoeffding tree, one of the state-of-the-art online learning models. The proposed algorithm is light-weight in terms of both memory and computational demand, while still maintaining high generalization ability. A series of optimization techniques dedicated to the proposed algorithm have been investigated from the hardware perspective, including coarse-grained and fine-grained parallelism, dynamic and memory-based resource sharing, pipelining with data forwarding. Following this, we present Hard-ODT, a high-performance, hardware-efficient and scalable online decision tree learning system on a field-programmable gate array (FPGA) with system-level optimization techniques. Performance and resource utilization are modeled for the complete learning system for early and fast analysis of the trade-off between various design metrics. Finally, we propose a design flow in which the proposed learning system is applied to FPGA run-time power monitoring as a case study.
Decision Tree Based Hardware Power Monitoring for Run Time Dynamic Power Management in FPGA
Sep 03, 2020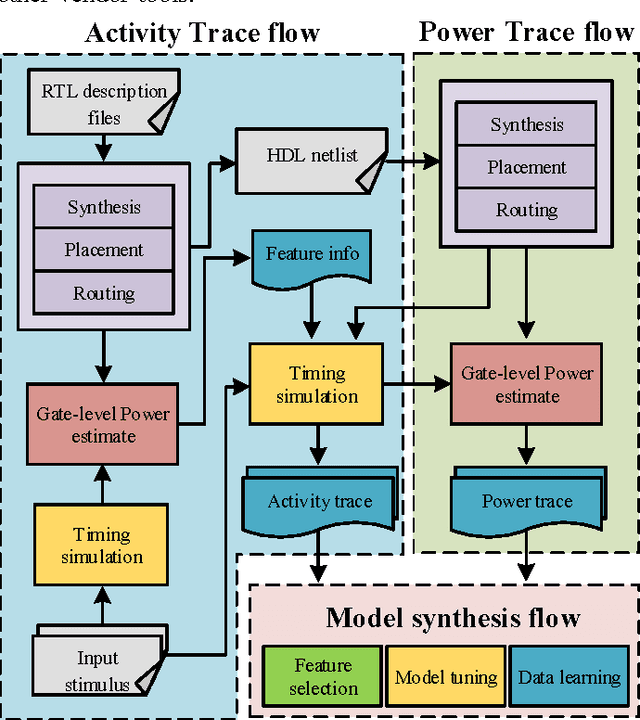
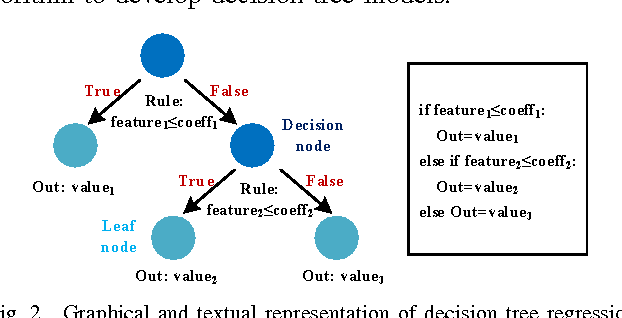
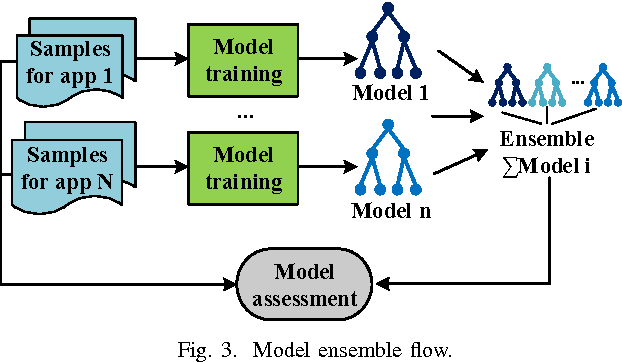
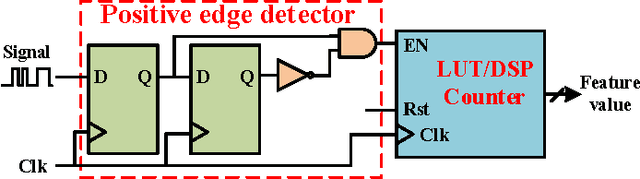
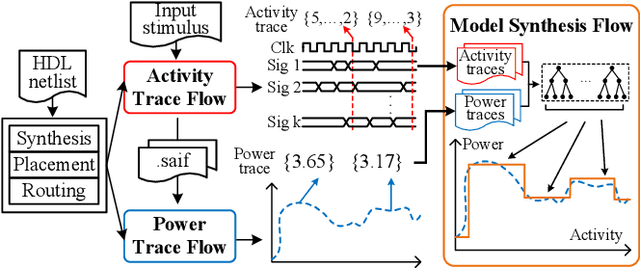
Fine-grained runtime power management techniques could be promising solutions for power reduction. Therefore, it is essential to establish accurate power monitoring schemes to obtain dynamic power variation in a short period (i.e., tens or hundreds of clock cycles). In this paper, we leverage a decision-tree-based power modeling approach to establish fine-grained hardware power monitoring on FPGA platforms. A generic and complete design flow is developed to implement the decision tree power model which is capable of precisely estimating dynamic power in a fine-grained manner. A flexible architecture of the hardware power monitoring is proposed, which can be instrumented in any RTL design for runtime power estimation, dispensing with the need for extra power measurement devices. Experimental results of applying the proposed model to benchmarks with different resource types reveal an average error up to 4% for dynamic power estimation. Moreover, the overheads of area, power and performance incurred by the power monitoring circuitry are extremely low. Finally, we apply our power monitoring technique to the power management using phase shedding with an on-chip multi-phase regulator as a proof of concept and the results demonstrate 14% efficiency enhancement for the power supply of the FPGA internal logic.
An Ensemble Learning Approach for In-situ Monitoring of FPGA Dynamic Power
Sep 03, 2020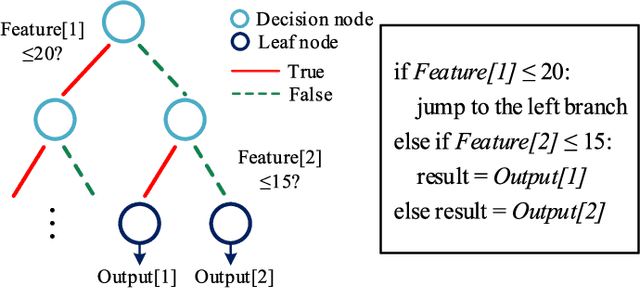
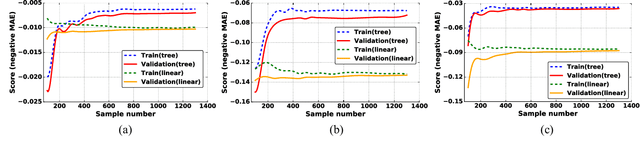
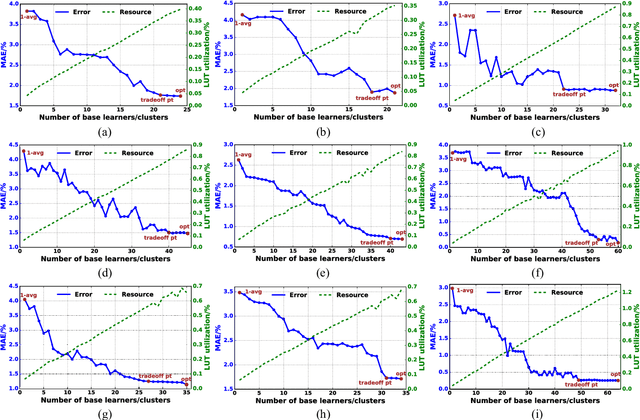
As field-programmable gate arrays become prevalent in critical application domains, their power consumption is of high concern. In this paper, we present and evaluate a power monitoring scheme capable of accurately estimating the runtime dynamic power of FPGAs in a fine-grained timescale, in order to support emerging power management techniques. In particular, we describe a novel and specialized ensemble model which can be decomposed into multiple customized decision-tree-based base learners. To aid in model synthesis, a generic computer-aided design flow is proposed to generate samples, select features, tune hyperparameters and train the ensemble estimator. Besides this, a hardware realization of the trained ensemble estimator is presented for on-chip real-time power estimation. In the experiments, we first show that a single decision tree model can achieve prediction error within 4.51% of a commercial gate-level power estimation tool, which is 2.41--6.07x lower than provided by the commonly used linear model. More importantly, we study the extra gains in inference accuracy using the proposed ensemble model. Experimental results reveal that the ensemble monitoring method can further improve the accuracy of power predictions to within a maximum error of 1.90%. Moreover, the lookup table (LUT) overhead of the ensemble monitoring hardware employing up to 64 base learners is within 1.22% of the target FPGA, indicating its light-weight and scalable characteristics.
Towards Efficient and Scalable Acceleration of Online Decision Tree Learning on FPGA
Sep 03, 2020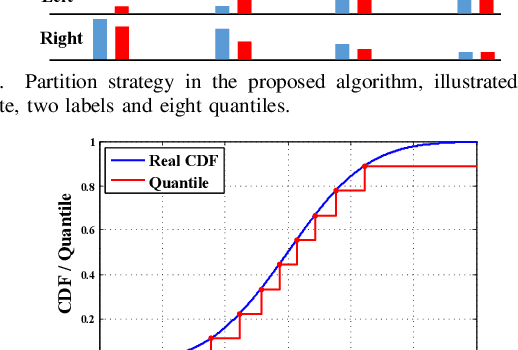
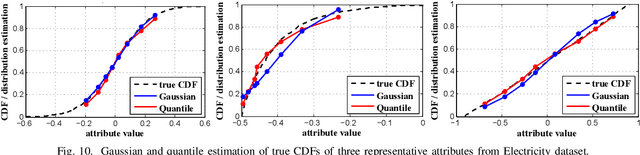

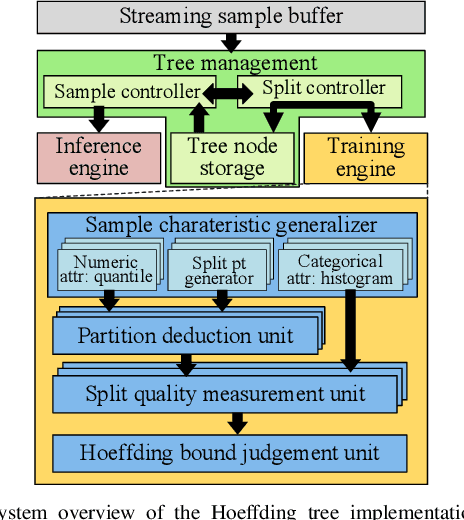
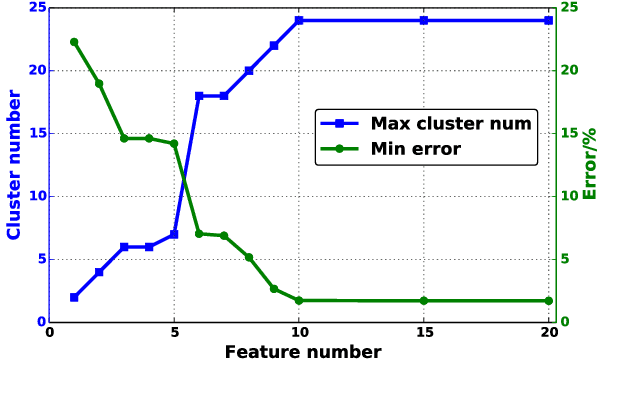
Decision trees are machine learning models commonly used in various application scenarios. In the era of big data, traditional decision tree induction algorithms are not suitable for learning large-scale datasets due to their stringent data storage requirement. Online decision tree learning algorithms have been devised to tackle this problem by concurrently training with incoming samples and providing inference results. However, even the most up-to-date online tree learning algorithms still suffer from either high memory usage or high computational intensity with dependency and long latency, making them challenging to implement in hardware. To overcome these difficulties, we introduce a new quantile-based algorithm to improve the induction of the Hoeffding tree, one of the state-of-the-art online learning models. The proposed algorithm is light-weight in terms of both memory and computational demand, while still maintaining high generalization ability. A series of optimization techniques dedicated to the proposed algorithm have been investigated from the hardware perspective, including coarse-grained and fine-grained parallelism, dynamic and memory-based resource sharing, pipelining with data forwarding. We further present a high-performance, hardware-efficient and scalable online decision tree learning system on a field-programmable gate array (FPGA) with system-level optimization techniques. Experimental results show that our proposed algorithm outperforms the state-of-the-art Hoeffding tree learning method, leading to 0.05% to 12.3% improvement in inference accuracy. Real implementation of the complete learning system on the FPGA demonstrates a 384x to 1581x speedup in execution time over the state-of-the-art design.
FP-Stereo: Hardware-Efficient Stereo Vision for Embedded Applications
Jul 01, 2020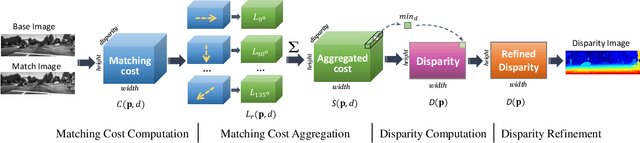
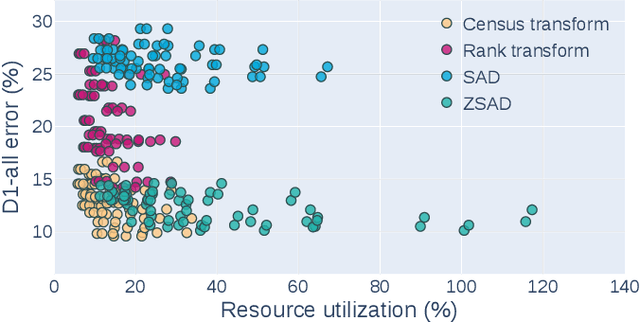
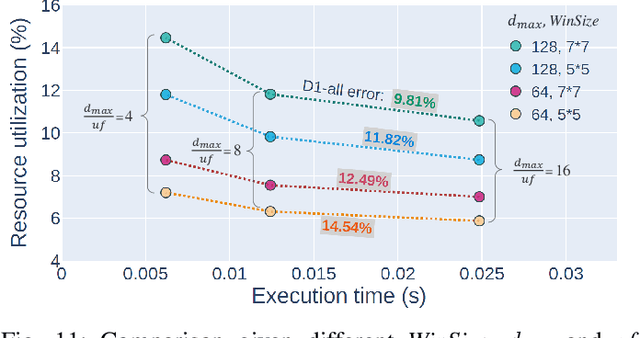
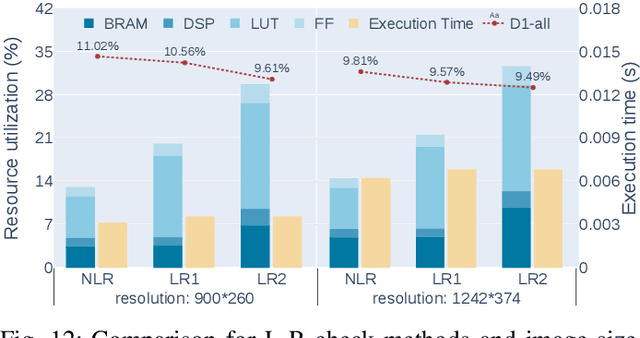
Fast and accurate depth estimation, or stereo matching, is essential in embedded stereo vision systems, requiring substantial design effort to achieve an appropriate balance among accuracy, speed and hardware cost. To reduce the design effort and achieve the right balance, we propose FP-Stereo for building high-performance stereo matching pipelines on FPGAs automatically. FP-Stereo consists of an open-source hardware-efficient library, allowing designers to obtain the desired implementation instantly. Diverse methods are supported in our library for each stage of the stereo matching pipeline and a series of techniques are developed to exploit the parallelism and reduce the resource overhead. To improve the usability, FP-Stereo can generate synthesizable C code of the FPGA accelerator with our optimized HLS templates automatically. To guide users for the right design choice meeting specific application requirements, detailed comparisons are performed on various configurations of our library to investigate the accuracy/speed/cost trade-off. Experimental results also show that FP-Stereo outperforms the state-of-the-art FPGA design from all aspects, including 6.08% lower error, 2x faster speed, 30% less resource usage and 40% less energy consumption. Compared to GPU designs, FP-Stereo achieves the same accuracy at a competitive speed while consuming much less energy.