 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Assessment of Feature Detection Methods for 2-D FS Sonar Imagery
Sep 11, 2024

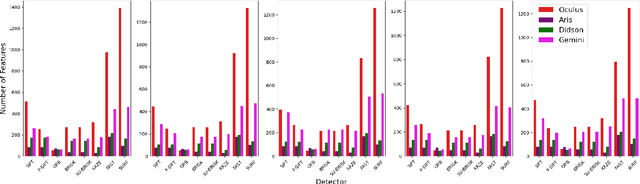
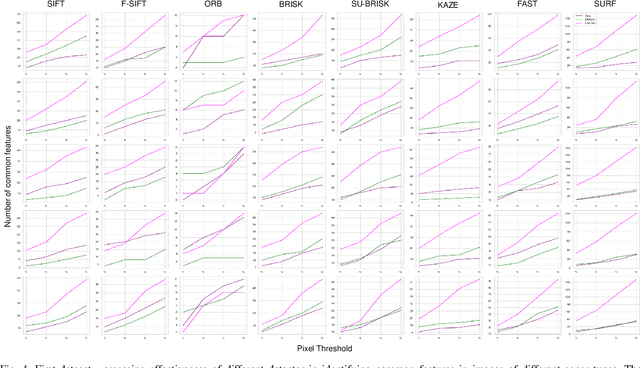
Underwater robot perception is crucial in scientific subsea exploration and commercial operations. The key challenges include non-uniform lighting and poor visibility in turbid environments. High-frequency forward-look sonar cameras address these issues, by providing high-resolution imagery at maximum range of tens of meters, despite complexities posed by high degree of speckle noise, and lack of color and texture. In particular, robust feature detection is an essential initial step for automated object recognition, localization, navigation, and 3-D mapping. Various local feature detectors developed for RGB images are not well-suited for sonar data. To assess their performances, we evaluate a number of feature detectors using real sonar images from five different sonar devices. Performance metrics such as detection accuracy, false positives, and robustness to variations in target characteristics and sonar devices are applied to analyze the experimental results. The study would provide a deeper insight into the bottlenecks of feature detection for sonar data, and developing more effective methods
MARVIS: Motion & Geometry Aware Real and Virtual Image Segmentation
Mar 14, 2024



Tasks such as autonomous navigation, 3D reconstruction, and object recognition near the water surfaces are crucial in marine robotics applications. However, challenges arise due to dynamic disturbances, e.g., light reflections and refraction from the random air-water interface, irregular liquid flow, and similar factors, which can lead to potential failures in perception and navigation systems. Traditional computer vision algorithms struggle to differentiate between real and virtual image regions, significantly complicating tasks. A virtual image region is an apparent representation formed by the redirection of light rays, typically through reflection or refraction, creating the illusion of an object's presence without its actual physical location. This work proposes a novel approach for segmentation on real and virtual image regions, exploiting synthetic images combined with domain-invariant information, a Motion Entropy Kernel, and Epipolar Geometric Consistency. Our segmentation network does not need to be re-trained if the domain changes. We show this by deploying the same segmentation network in two different domains: simulation and the real world. By creating realistic synthetic images that mimic the complexities of the water surface, we provide fine-grained training data for our network (MARVIS) to discern between real and virtual images effectively. By motion & geometry-aware design choices and through comprehensive experimental analysis, we achieve state-of-the-art real-virtual image segmentation performance in unseen real world domain, achieving an IoU over 78% and a F1-Score over 86% while ensuring a small computational footprint. MARVIS offers over 43 FPS (8 FPS) inference rates on a single GPU (CPU core). Our code and dataset are available here https://github.com/jiayi-wu-umd/MARVIS.