 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFruit Deformity Classification through Single-Input and Multi-Input Architectures based on CNN Models using Real and Synthetic Images
Dec 17, 2024The present study focuses on detecting the degree of deformity in fruits such as apples, mangoes, and strawberries during the process of inspecting their external quality, employing Single-Input and Multi-Input architectures based on convolutional neural network (CNN) models using sets of real and synthetic images. The datasets are segmented using the Segment Anything Model (SAM), which provides the silhouette of the fruits. Regarding the single-input architecture, the evaluation of the CNN models is performed only with real images, but a methodology is proposed to improve these results using a pre-trained model with synthetic images. In the Multi-Input architecture, branches with RGB images and fruit silhouettes are implemented as inputs for evaluating CNN models such as VGG16, MobileNetV2, and CIDIS. However, the results revealed that the Multi-Input architecture with the MobileNetV2 model was the most effective in identifying deformities in the fruits, achieving accuracies of 90\%, 94\%, and 92\% for apples, mangoes, and strawberries, respectively. In conclusion, the Multi-Input architecture with the MobileNetV2 model is the most accurate for classifying levels of deformity in fruits.
* 15 pages, 9 figures, CIARP 2024
Video-based Human Action Recognition using Deep Learning: A Review
Aug 07, 2022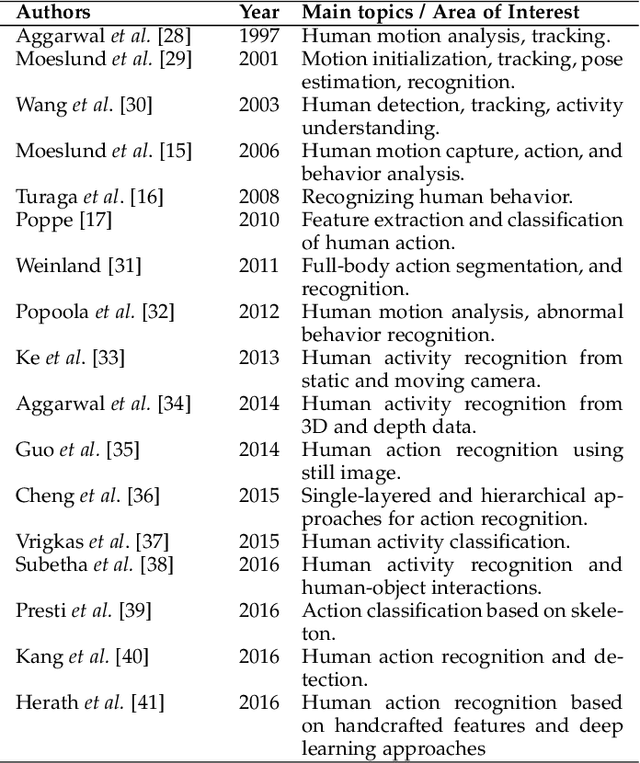

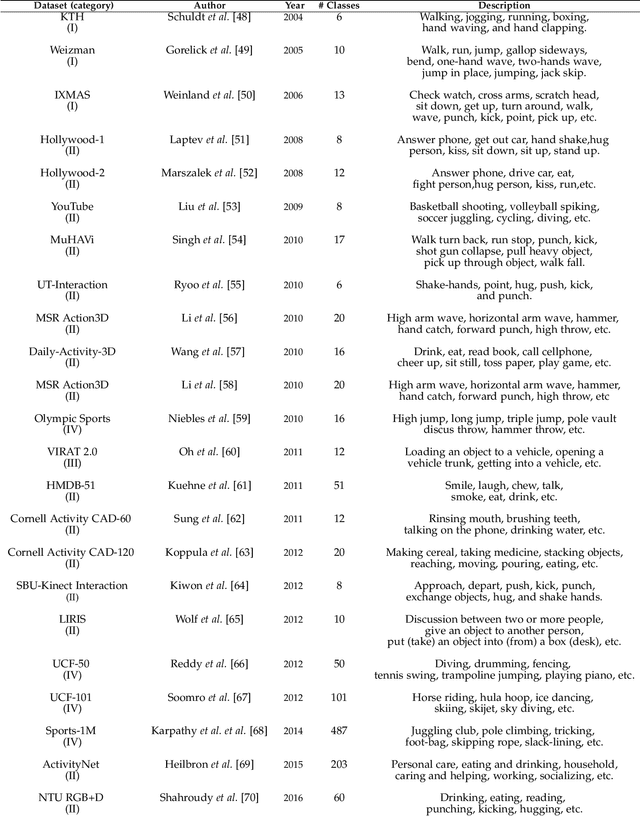

Human action recognition is an important application domain in computer vision. Its primary aim is to accurately describe human actions and their interactions from a previously unseen data sequence acquired by sensors. The ability to recognize, understand, and predict complex human actions enables the construction of many important applications such as intelligent surveillance systems, human-computer interfaces, health care, security, and military applications. In recent years, deep learning has been given particular attention by the computer vision community. This paper presents an overview of the current state-of-the-art in action recognition using video analysis with deep learning techniques. We present the most important deep learning models for recognizing human actions, and analyze them to provide the current progress of deep learning algorithms applied to solve human action recognition problems in realistic videos highlighting their advantages and disadvantages. Based on the quantitative analysis using recognition accuracies reported in the literature, our study identifies state-of-the-art deep architectures in action recognition and then provides current trends and open problems for future works in this field.
Sparse LiDAR and Stereo Fusion for Depth Estimationand 3D Object Detection
Mar 05, 2021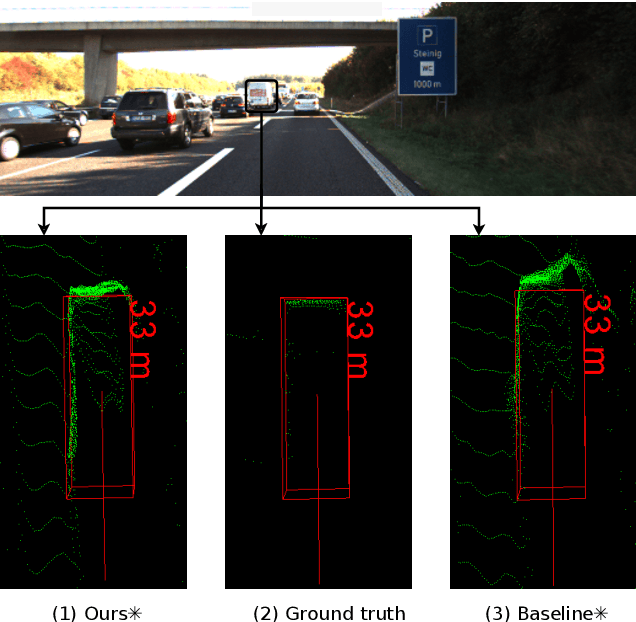
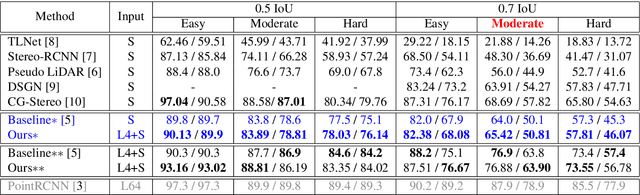

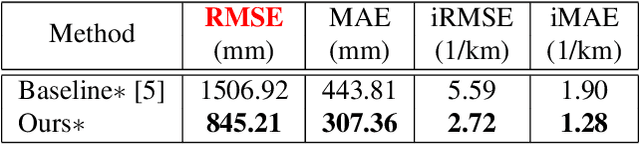
The ability to accurately detect and localize objects is recognized as being the most important for the perception of self-driving cars. From 2D to 3D object detection, the most difficult is to determine the distance from the ego-vehicle to objects. Expensive technology like LiDAR can provide a precise and accurate depth information, so most studies have tended to focus on this sensor showing a performance gap between LiDAR-based methods and camera-based methods. Although many authors have investigated how to fuse LiDAR with RGB cameras, as far as we know there are no studies to fuse LiDAR and stereo in a deep neural network for the 3D object detection task. This paper presents SLS-Fusion, a new approach to fuse data from 4-beam LiDAR and a stereo camera via a neural network for depth estimation to achieve better dense depth maps and thereby improves 3D object detection performance. Since 4-beam LiDAR is cheaper than the well-known 64-beam LiDAR, this approach is also classified as a low-cost sensors-based method. Through evaluation on the KITTI benchmark, it is shown that the proposed method significantly improves depth estimation performance compared to a baseline method. Also, when applying it to 3D object detection, a new state of the art on low-cost sensor based method is achieved.
Learning to Recognize 3D Human Action from A New Skeleton-based Representation Using Deep Convolutional Neural Networks
Dec 26, 2018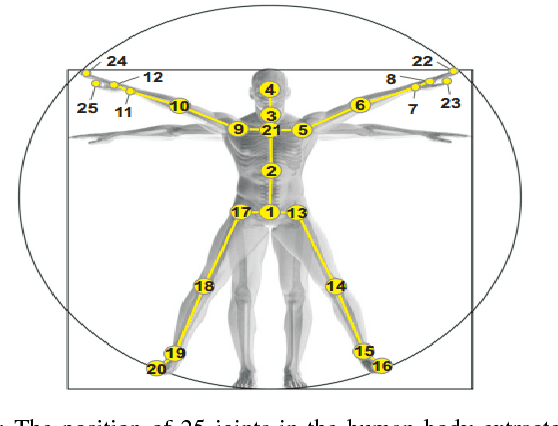

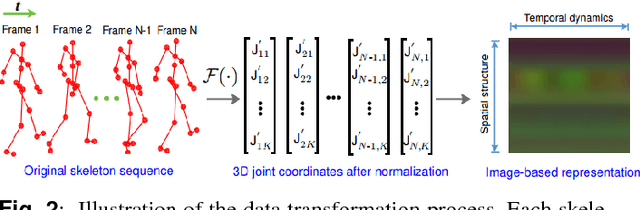
Recognizing human actions in untrimmed videos is an important challenging task. An effective 3D motion representation and a powerful learning model are two key factors influencing recognition performance. In this paper we introduce a new skeleton-based representation for 3D action recognition in videos. The key idea of the proposed representation is to transform 3D joint coordinates of the human body carried in skeleton sequences into RGB images via a color encoding process. By normalizing the 3D joint coordinates and dividing each skeleton frame into five parts, where the joints are concatenated according to the order of their physical connections, the color-coded representation is able to represent spatio-temporal evolutions of complex 3D motions, independently of the length of each sequence. We then design and train different Deep Convolutional Neural Networks (D-CNNs) based on the Residual Network architecture (ResNet) on the obtained image-based representations to learn 3D motion features and classify them into classes. Our method is evaluated on two widely used action recognition benchmarks: MSR Action3D and NTU-RGB+D, a very large-scale dataset for 3D human action recognition. The experimental results demonstrate that the proposed method outperforms previous state-of-the-art approaches whilst requiring less computation for training and prediction.
Motorcycle Classification in Urban Scenarios using Convolutional Neural Networks for Feature Extraction
Aug 28, 2018
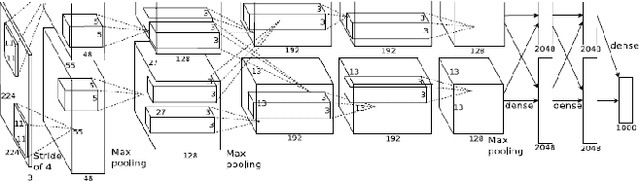
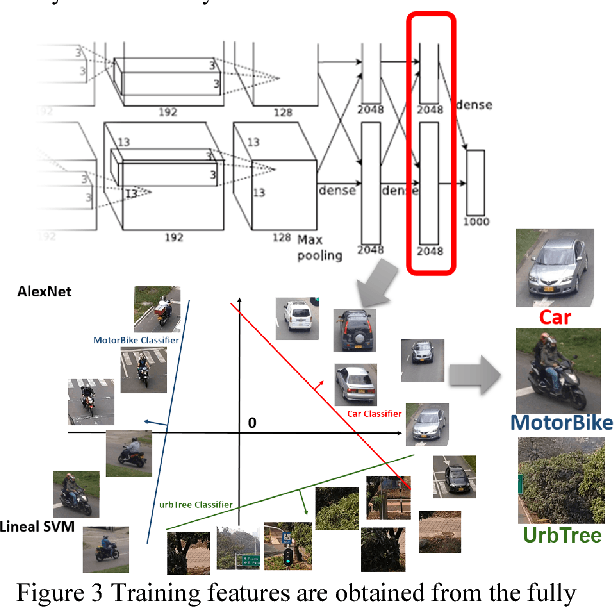
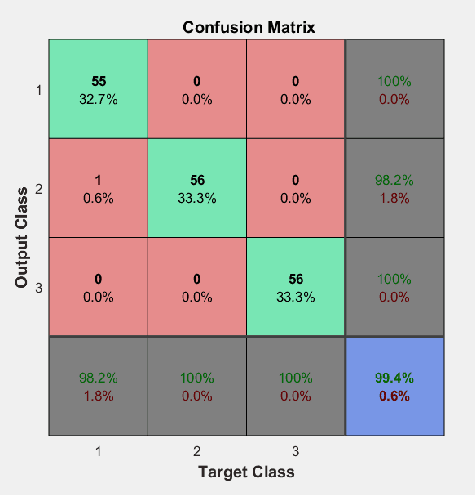
This paper presents a motorcycle classification system for urban scenarios using Convolutional Neural Network (CNN). Significant results on image classification has been achieved using CNNs at the expense of a high computational cost for training with thousands or even millions of examples. Nevertheless, features can be extracted from CNNs already trained. In this work AlexNet, included in the framework CaffeNet, is used to extract features from frames taken on a real urban scenario. The extracted features from the CNN are used to train a support vector machine (SVM) classifier to discriminate motorcycles from other road users. The obtained results show a mean accuracy of 99.40% and 99.29% on a classification task of three and five classes respectively. Further experiments are performed on a validation set of images showing a satisfactory classification.
* This paper were published by IET for the ICPRS 2017 Conference, Madrid Spain July 2017
Motorcycle detection and classification in urban Scenarios using a model based on Faster R-CNN
Aug 08, 2018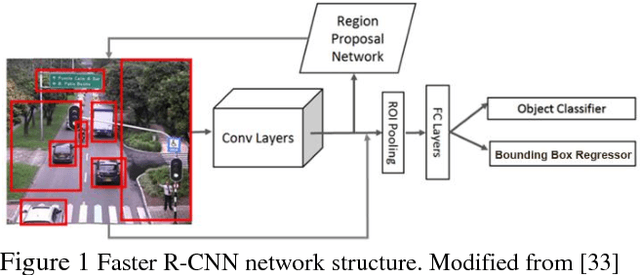
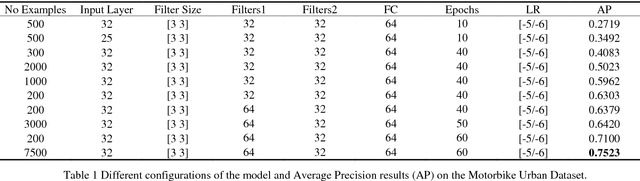
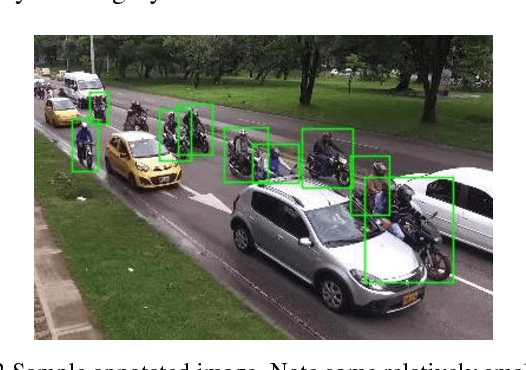
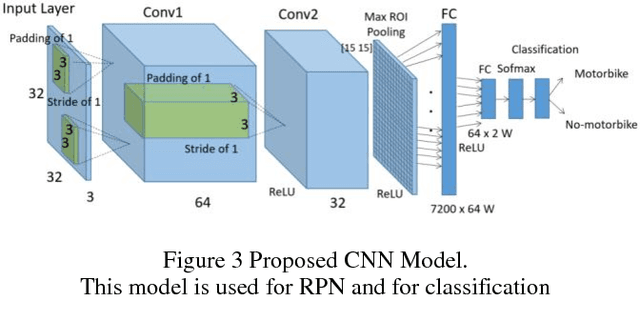
This paper introduces a Deep Learning Convolutional Neural Network model based on Faster-RCNN for motorcycle detection and classification on urban environments. The model is evaluated in occluded scenarios where more than 60% of the vehicles present a degree of occlusion. For training and evaluation, we introduce a new dataset of 7500 annotated images, captured under real traffic scenes, using a drone mounted camera. Several tests were carried out to design the network, achieving promising results of 75% in average precision (AP), even with the high number of occluded motorbikes, the low angle of capture and the moving camera. The model is also evaluated on low occlusions datasets, reaching results of up to 92% in AP.
Skeletal Movement to Color Map: A Novel Representation for 3D Action Recognition with Inception Residual Networks
Jul 18, 2018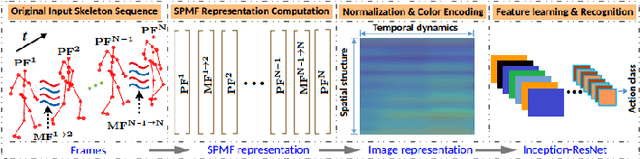


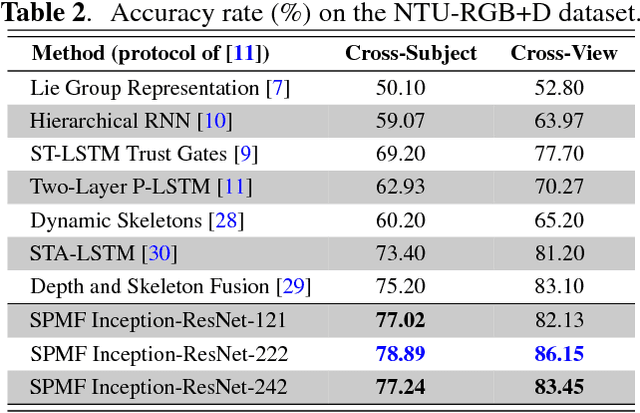
We propose a novel skeleton-based representation for 3D action recognition in videos using Deep Convolutional Neural Networks (D-CNNs). Two key issues have been addressed: First, how to construct a robust representation that easily captures the spatial-temporal evolutions of motions from skeleton sequences. Second, how to design D-CNNs capable of learning discriminative features from the new representation in a effective manner. To address these tasks, a skeletonbased representation, namely, SPMF (Skeleton Pose-Motion Feature) is proposed. The SPMFs are built from two of the most important properties of a human action: postures and their motions. Therefore, they are able to effectively represent complex actions. For learning and recognition tasks, we design and optimize new D-CNNs based on the idea of Inception Residual networks to predict actions from SPMFs. Our method is evaluated on two challenging datasets including MSR Action3D and NTU-RGB+D. Experimental results indicated that the proposed method surpasses state-of-the-art methods whilst requiring less computation.
Exploiting deep residual networks for human action recognition from skeletal data
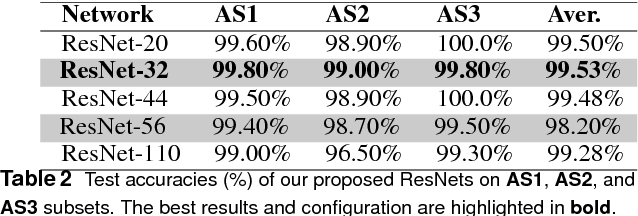
Mar 21, 2018
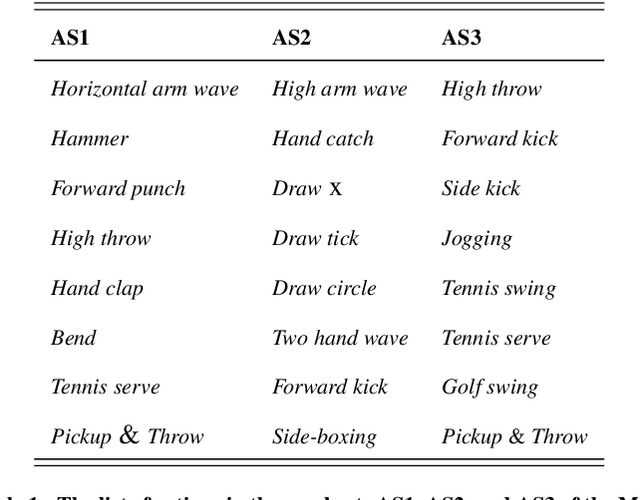
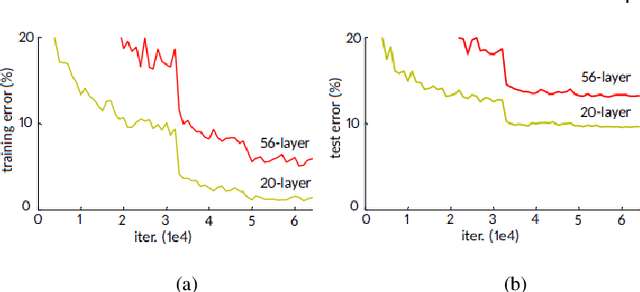
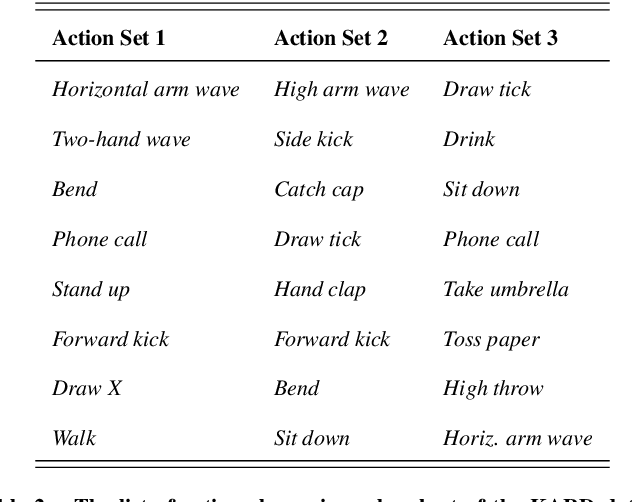
The computer vision community is currently focusing on solving action recognition problems in real videos, which contain thousands of samples with many challenges. In this process, Deep Convolutional Neural Networks (D-CNNs) have played a significant role in advancing the state-of-the-art in various vision-based action recognition systems. Recently, the introduction of residual connections in conjunction with a more traditional CNN model in a single architecture called Residual Network (ResNet) has shown impressive performance and great potential for image recognition tasks. In this paper, we investigate and apply deep ResNets for human action recognition using skeletal data provided by depth sensors. Firstly, the 3D coordinates of the human body joints carried in skeleton sequences are transformed into image-based representations and stored as RGB images. These color images are able to capture the spatial-temporal evolutions of 3D motions from skeleton sequences and can be efficiently learned by D-CNNs. We then propose a novel deep learning architecture based on ResNets to learn features from obtained color-based representations and classify them into action classes. The proposed method is evaluated on three challenging benchmark datasets including MSR Action 3D, KARD, and NTU-RGB+D datasets. Experimental results demonstrate that our method achieves state-of-the-art performance for all these benchmarks whilst requiring less computation resource. In particular, the proposed method surpasses previous approaches by a significant margin of 3.4% on MSR Action 3D dataset, 0.67% on KARD dataset, and 2.5% on NTU-RGB+D dataset.
Learning and Recognizing Human Action from Skeleton Movement with Deep Residual Neural Networks
Mar 21, 2018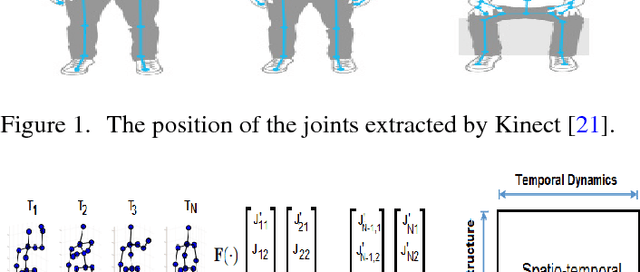
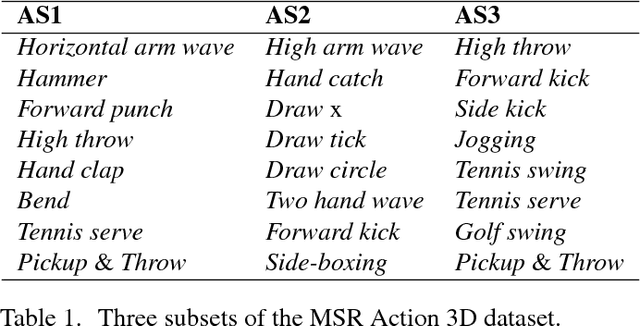
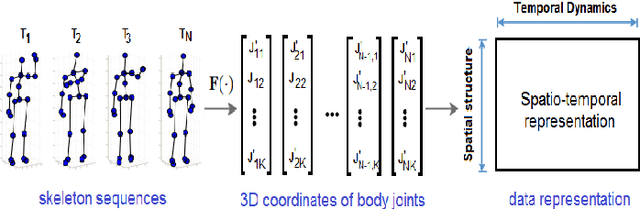
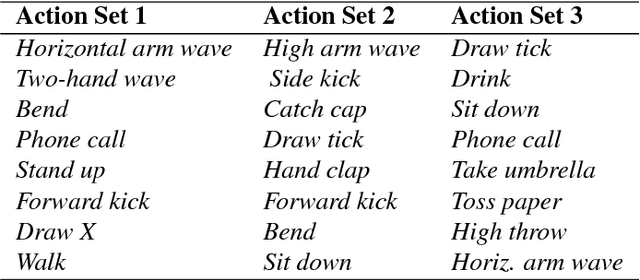
Automatic human action recognition is indispensable for almost artificial intelligent systems such as video surveillance, human-computer interfaces, video retrieval, etc. Despite a lot of progress, recognizing actions in an unknown video is still a challenging task in computer vision. Recently, deep learning algorithms have proved its great potential in many vision-related recognition tasks. In this paper, we propose the use of Deep Residual Neural Networks (ResNets) to learn and recognize human action from skeleton data provided by Kinect sensor. Firstly, the body joint coordinates are transformed into 3D-arrays and saved in RGB images space. Five different deep learning models based on ResNet have been designed to extract image features and classify them into classes. Experiments are conducted on two public video datasets for human action recognition containing various challenges. The results show that our method achieves the state-of-the-art performance comparing with existing approaches.