 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based Human Action Recognition using Deep Learning: A Review
Aug 07, 2022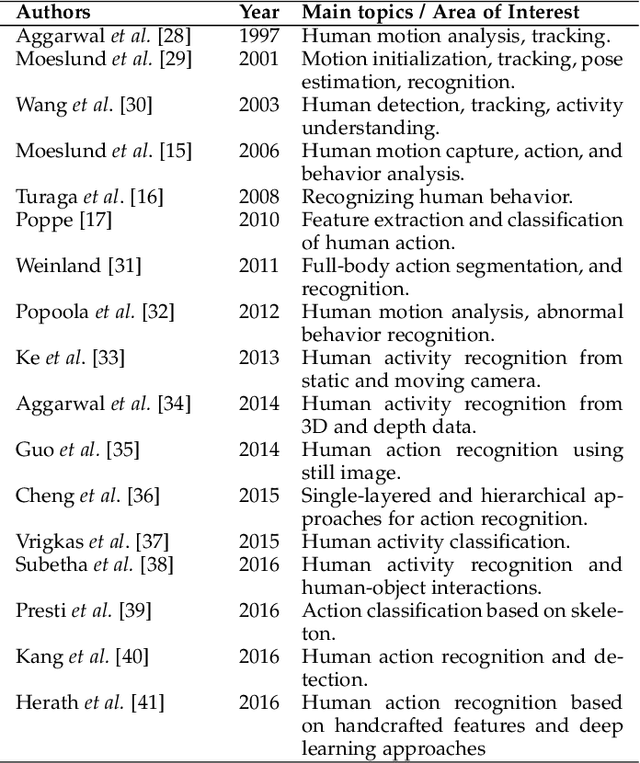

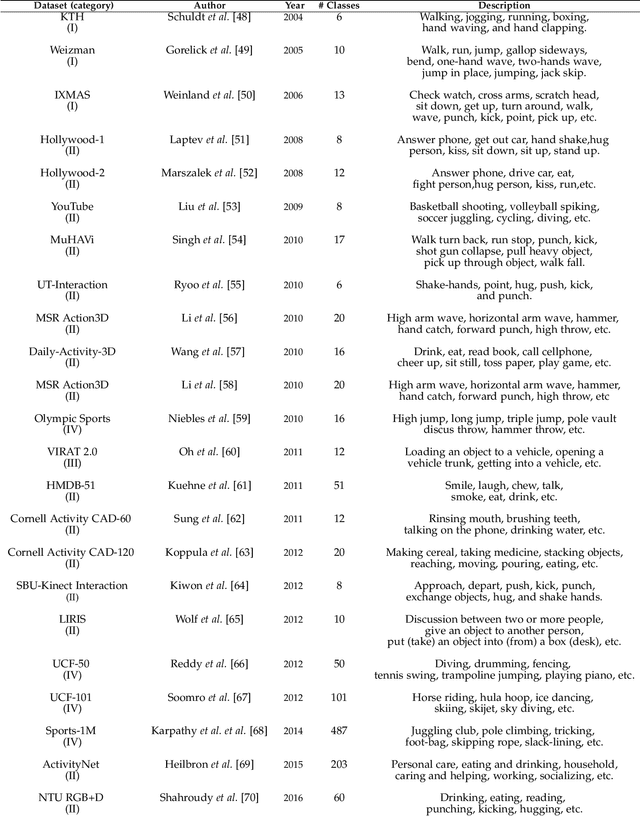

Human action recognition is an important application domain in computer vision. Its primary aim is to accurately describe human actions and their interactions from a previously unseen data sequence acquired by sensors. The ability to recognize, understand, and predict complex human actions enables the construction of many important applications such as intelligent surveillance systems, human-computer interfaces, health care, security, and military applications. In recent years, deep learning has been given particular attention by the computer vision community. This paper presents an overview of the current state-of-the-art in action recognition using video analysis with deep learning techniques. We present the most important deep learning models for recognizing human actions, and analyze them to provide the current progress of deep learning algorithms applied to solve human action recognition problems in realistic videos highlighting their advantages and disadvantages. Based on the quantitative analysis using recognition accuracies reported in the literature, our study identifies state-of-the-art deep architectures in action recognition and then provides current trends and open problems for future works in this field.
Sparse LiDAR and Stereo Fusion for Depth Estimationand 3D Object Detection
Mar 05, 2021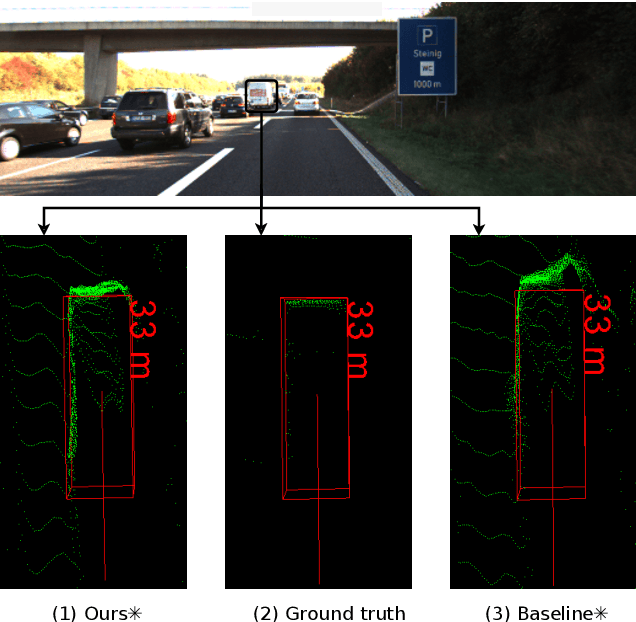
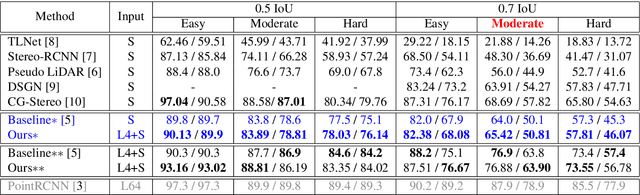

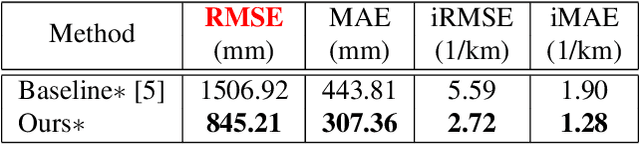
The ability to accurately detect and localize objects is recognized as being the most important for the perception of self-driving cars. From 2D to 3D object detection, the most difficult is to determine the distance from the ego-vehicle to objects. Expensive technology like LiDAR can provide a precise and accurate depth information, so most studies have tended to focus on this sensor showing a performance gap between LiDAR-based methods and camera-based methods. Although many authors have investigated how to fuse LiDAR with RGB cameras, as far as we know there are no studies to fuse LiDAR and stereo in a deep neural network for the 3D object detection task. This paper presents SLS-Fusion, a new approach to fuse data from 4-beam LiDAR and a stereo camera via a neural network for depth estimation to achieve better dense depth maps and thereby improves 3D object detection performance. Since 4-beam LiDAR is cheaper than the well-known 64-beam LiDAR, this approach is also classified as a low-cost sensors-based method. Through evaluation on the KITTI benchmark, it is shown that the proposed method significantly improves depth estimation performance compared to a baseline method. Also, when applying it to 3D object detection, a new state of the art on low-cost sensor based method is achieved.
A Unified Deep Framework for Joint 3D Pose Estimation and Action Recognition from a Single RGB Camera
Jul 16, 2019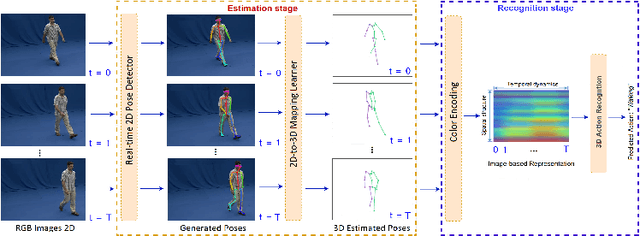
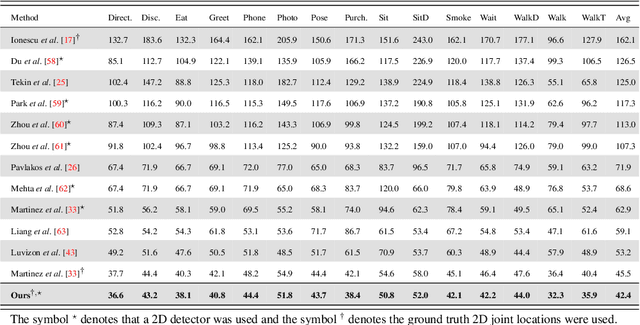
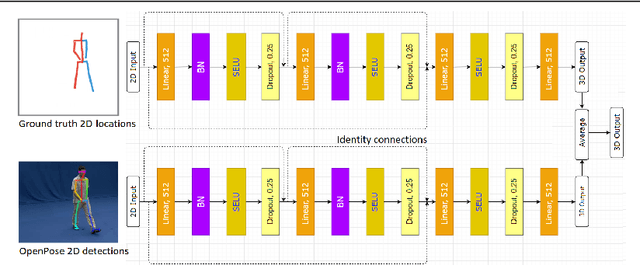

We present a deep learning-based multitask framework for joint 3D human pose estimation and action recognition from RGB video sequences. Our approach proceeds along two stages. In the first, we run a real-time 2D pose detector to determine the precise pixel location of important keypoints of the body. A two-stream neural network is then designed and trained to map detected 2D keypoints into 3D poses. In the second, we deploy the Efficient Neural Architecture Search (ENAS) algorithm to find an optimal network architecture that is used for modeling the spatio-temporal evolution of the estimated 3D poses via an image-based intermediate representation and performing action recognition. Experiments on Human3.6M, MSR Action3D and SBU Kinect Interaction datasets verify the effectiveness of the proposed method on the targeted tasks. Moreover, we show that our method requires a low computational budget for training and inference.
A Deep Learning Approach for Real-Time 3D Human Action Recognition from Skeletal Data
Jul 08, 2019
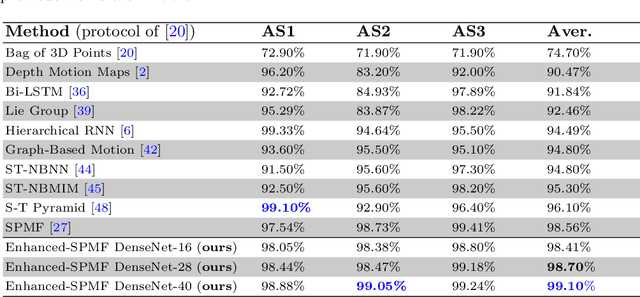

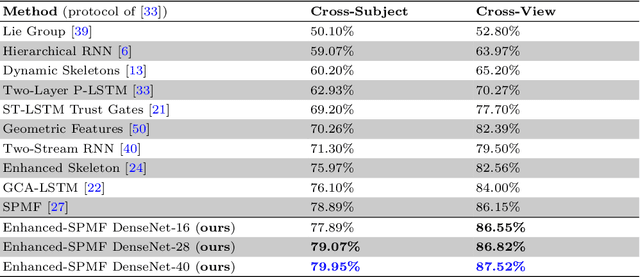
We present a new deep learning approach for real-time 3D human action recognition from skeletal data and apply it to develop a vision-based intelligent surveillance system. Given a skeleton sequence, we propose to encode skeleton poses and their motions into a single RGB image. An Adaptive Histogram Equalization (AHE) algorithm is then applied on the color images to enhance their local patterns and generate more discriminative features. For learning and classification tasks, we design Deep Neural Networks based on the Densely Connected Convolutional Architecture (DenseNet) to extract features from enhanced-color images and classify them into classes. Experimental results on two challenging datasets show that the proposed method reaches state-of-the-art accuracy, whilst requiring low computational time for training and inference. This paper also introduces CEMEST, a new RGB-D dataset depicting passenger behaviors in public transport. It consists of 203 untrimmed real-world surveillance videos of realistic normal and anomalous events. We achieve promising results on real conditions of this dataset with the support of data augmentation and transfer learning techniques. This enables the construction of real-world applications based on deep learning for enhancing monitoring and security in public transport.
Learning to Recognize 3D Human Action from A New Skeleton-based Representation Using Deep Convolutional Neural Networks
Dec 26, 2018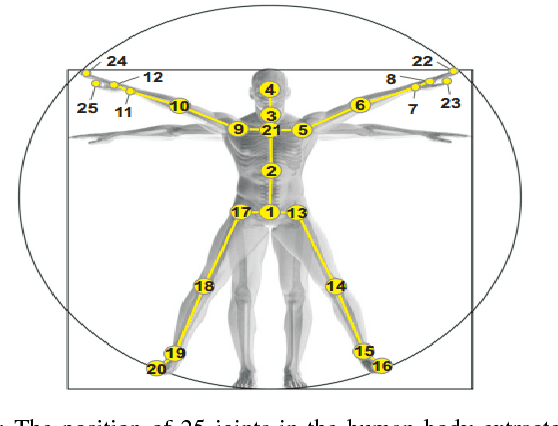

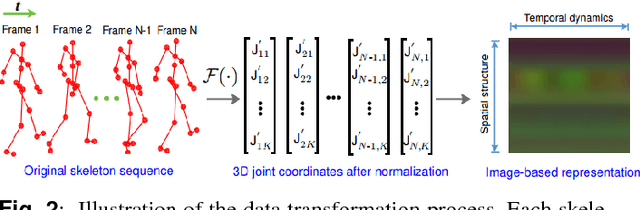
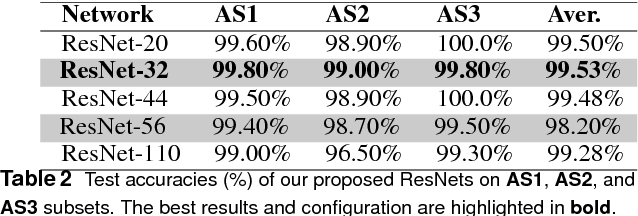
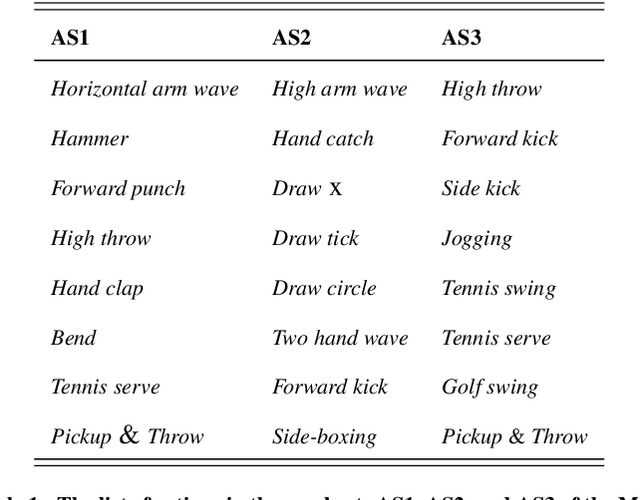
Recognizing human actions in untrimmed videos is an important challenging task. An effective 3D motion representation and a powerful learning model are two key factors influencing recognition performance. In this paper we introduce a new skeleton-based representation for 3D action recognition in videos. The key idea of the proposed representation is to transform 3D joint coordinates of the human body carried in skeleton sequences into RGB images via a color encoding process. By normalizing the 3D joint coordinates and dividing each skeleton frame into five parts, where the joints are concatenated according to the order of their physical connections, the color-coded representation is able to represent spatio-temporal evolutions of complex 3D motions, independently of the length of each sequence. We then design and train different Deep Convolutional Neural Networks (D-CNNs) based on the Residual Network architecture (ResNet) on the obtained image-based representations to learn 3D motion features and classify them into classes. Our method is evaluated on two widely used action recognition benchmarks: MSR Action3D and NTU-RGB+D, a very large-scale dataset for 3D human action recognition. The experimental results demonstrate that the proposed method outperforms previous state-of-the-art approaches whilst requiring less computation for training and prediction.
Skeletal Movement to Color Map: A Novel Representation for 3D Action Recognition with Inception Residual Networks
Jul 18, 2018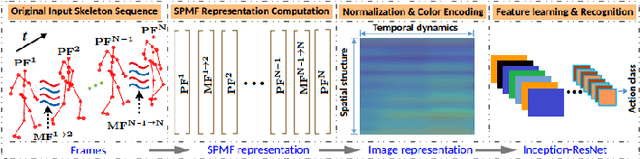


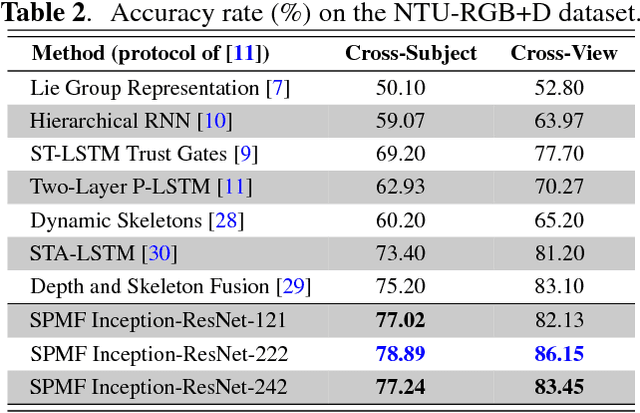
We propose a novel skeleton-based representation for 3D action recognition in videos using Deep Convolutional Neural Networks (D-CNNs). Two key issues have been addressed: First, how to construct a robust representation that easily captures the spatial-temporal evolutions of motions from skeleton sequences. Second, how to design D-CNNs capable of learning discriminative features from the new representation in a effective manner. To address these tasks, a skeletonbased representation, namely, SPMF (Skeleton Pose-Motion Feature) is proposed. The SPMFs are built from two of the most important properties of a human action: postures and their motions. Therefore, they are able to effectively represent complex actions. For learning and recognition tasks, we design and optimize new D-CNNs based on the idea of Inception Residual networks to predict actions from SPMFs. Our method is evaluated on two challenging datasets including MSR Action3D and NTU-RGB+D. Experimental results indicated that the proposed method surpasses state-of-the-art methods whilst requiring less computation.
Exploiting deep residual networks for human action recognition from skeletal data
Mar 21, 2018
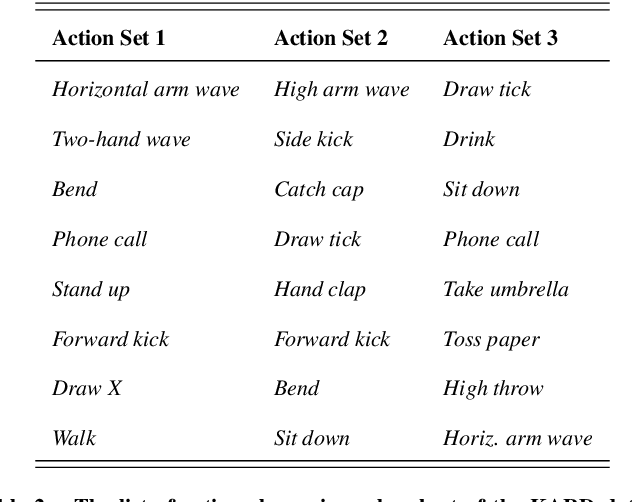
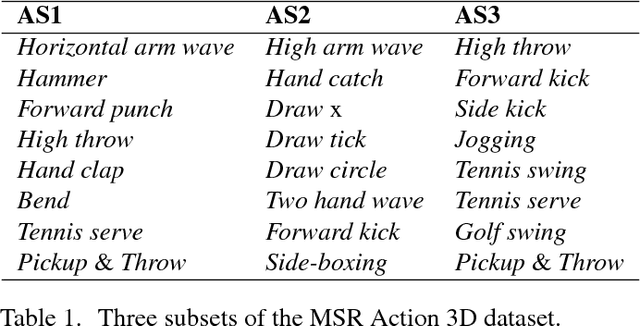
The computer vision community is currently focusing on solving action recognition problems in real videos, which contain thousands of samples with many challenges. In this process, Deep Convolutional Neural Networks (D-CNNs) have played a significant role in advancing the state-of-the-art in various vision-based action recognition systems. Recently, the introduction of residual connections in conjunction with a more traditional CNN model in a single architecture called Residual Network (ResNet) has shown impressive performance and great potential for image recognition tasks. In this paper, we investigate and apply deep ResNets for human action recognition using skeletal data provided by depth sensors. Firstly, the 3D coordinates of the human body joints carried in skeleton sequences are transformed into image-based representations and stored as RGB images. These color images are able to capture the spatial-temporal evolutions of 3D motions from skeleton sequences and can be efficiently learned by D-CNNs. We then propose a novel deep learning architecture based on ResNets to learn features from obtained color-based representations and classify them into action classes. The proposed method is evaluated on three challenging benchmark datasets including MSR Action 3D, KARD, and NTU-RGB+D datasets. Experimental results demonstrate that our method achieves state-of-the-art performance for all these benchmarks whilst requiring less computation resource. In particular, the proposed method surpasses previous approaches by a significant margin of 3.4% on MSR Action 3D dataset, 0.67% on KARD dataset, and 2.5% on NTU-RGB+D dataset.
Learning and Recognizing Human Action from Skeleton Movement with Deep Residual Neural Networks
Mar 21, 2018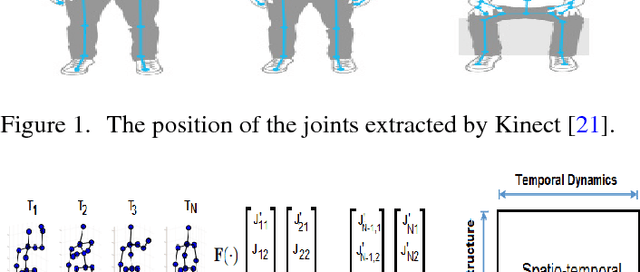
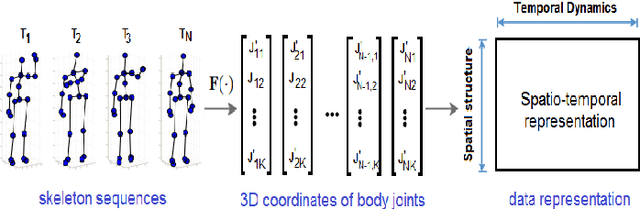
Automatic human action recognition is indispensable for almost artificial intelligent systems such as video surveillance, human-computer interfaces, video retrieval, etc. Despite a lot of progress, recognizing actions in an unknown video is still a challenging task in computer vision. Recently, deep learning algorithms have proved its great potential in many vision-related recognition tasks. In this paper, we propose the use of Deep Residual Neural Networks (ResNets) to learn and recognize human action from skeleton data provided by Kinect sensor. Firstly, the body joint coordinates are transformed into 3D-arrays and saved in RGB images space. Five different deep learning models based on ResNet have been designed to extract image features and classify them into classes. Experiments are conducted on two public video datasets for human action recognition containing various challenges. The results show that our method achieves the state-of-the-art performance comparing with existing approaches.