 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIC: Maximizing Informational Capacity in Adaptive Representations via Isotropic Subspace Alignment
May 28, 2026Although multi-scales representation learning enables elastic-dimension embeddings, nested subspaces often suffer from dimensional redundancy and spectral collapse. To address this, we introduce MIC, a framework that optimizes the geometric landscape of multi-granular embeddings through isotropic subspace alignment. MIC employs Soft Collapse Regularization (SCR) to mitigate redundancy between prefix and residual subspaces via cross-correlation penalties, alongside Spectral Isotropy Regularization (SIR) to ensure hyper-spherical uniformity in low-dimensional prefixes. By unifying these strategies through a self-distillation objective, MIC generates semantically dense representations that maintain high discriminative power. Our experiments demonstrate that MIC significantly outperforms standard baselines, particularly in high-compression scenarios where maintaining informational capacity is most critical.
EVL-ECG: Efficient ECG Interpretation With Multi-Aspect Heterogeneous Knowledge Distillation
May 28, 2026High-fidelity ECG interpretation is increasingly reliant on massive foundation models, yet their deployment in clinical edge-care remains hindered by extreme computational demands. While knowledge distillation (KD) is a promising solution, traditional methods fail to capture the complex spatio-temporal dependencies of ECG signals when transferring knowledge across heterogeneous architectures. In this paper, we propose EVL-ECG, a framework specifically designed for cross-architecture distillation of cardiac diagnostic logic. EVL-ECG introduces three ECG-aware innovations: (1) Multi-Head Cross-Attention Alignment, which harmonizes architectural discrepancies to preserve fine-grained morphological features; (2) Optimal Transport-based Visual Feature Matching, utilizing optimal transport to maintain global structural relationships across ECG leads despite mismatched token representations; and (3) Geometric Intra-Architecture Relation Matching, which distills the latent diagnostic reasoning of the teacher model. Evaluations across ECG benchmarks demonstrate that EVL-ECG yields improvements of up to 2.4% AUC and 1.1% clinical accuracy over existing baselines. Notably, EVL-ECG establishes an efficient 2B-parameter ECG foundation model, suitable for resource-constrained clinical environments.
Mitigating Data Scarcity in Psychological Defense Classification with Context-Aware Synthetic Augmentation
May 14, 2026Psychological defense mechanisms (PDMs) are unconscious cognitive processes that modulate how individuals perceive and respond to emotional distress. Automatically classifying PDMs from text is clinically valuable but severely hindered by data scarcity and class imbalance, challenges which generative augmentation alone cannot resolve without psychological grounding. In this work, we address these challenges in the PsyDefDetect shared task (BioNLP@ACL 2026) by proposing a context-aware synthetic augmentation framework combined with a hybrid classification model. Our hybrid model integrates contextual language representations with basic clinical features, along with 150 annotated defense items. Experiments demonstrate that definition quality in prompting directly governs generation fidelity and downstream performance. Our method surpasses DMRS Co-Pilot, reaching an accuracy of 58.26% (+40.25%) and a macro-F1 of 24.62% (+15.99%), thereby establishing a strong baseline for psychologically grounded defense mechanism classification in low-resource settings. Source code is available at: https://github.com/htdgv/CASA-PDC.
BTS-rPPG: Orthogonal Butterfly Temporal Shifting for Remote Photoplethysmography
Apr 02, 2026Remote photoplethysmography (rPPG) enables contactless physiological sensing from facial videos by analyzing subtle appearance variations induced by blood circulation. However, modeling the temporal dynamics of these signals remains challenging, as many deep learning methods rely on temporal shifting or convolutional operators that aggregate information primarily from neighboring frames, resulting in predominantly local temporal modeling and limited temporal receptive fields. To address this limitation, we propose BTS-rPPG, a temporal modeling framework based on Orthogonal Butterfly Temporal Shifting (BTS). Inspired by the butterfly communication pattern in the Fast Fourier Transform (FFT), BTS establishes structured frame interactions via an XOR-based butterfly pairing schedule, progressively expanding the temporal receptive field and enabling efficient propagation of information across distant frames. Furthermore, we introduce an orthogonal feature transfer mechanism (OFT) that filters the source feature with respect to the target context before temporal shifting, retaining only the orthogonal component for cross-frame transmission. This reduces redundant feature propagation and encourages complementary temporal interaction. Extensive experiments on multiple benchmark datasets demonstrate that BTS-rPPG improves long-range temporal modeling of physiological dynamics and consistently outperforms existing temporal modeling strategies for rPPG estimation.
HOT: Harmonic-Constrained Optimal Transport for Remote Photoplethysmography Domain Adaptation
Apr 02, 2026Remote photoplethysmography (rPPG) enables non-contact physiological measurement from facial videos; however, its practical deployment is often hindered by substantial performance degradation under domain shift. While recent deep learning-based rPPG methods have achieved strong performance on individual datasets, they frequently overfit to appearance-related factors, such as illumination, camera characteristics, and color response, that vary significantly across domains. To address this limitation, we introduce frequency domain adaptation (FDA) as a principled strategy for modeling appearance variation in rPPG. By transferring low-frequency spectral components that encode domain-dependent appearance characteristics, FDA encourages rPPG models to learn invariance to appearance variations while retaining cardiac-induced signals. To further support physiologically consistent alignment under such appearance variation, we propose Harmonic-Constrained Optimal Transport (HOT), which leverages the harmonic property of cardiac signals to guide alignment between original and FDA-transferred representations. Extensive cross-dataset experiments demonstrate that the proposed FDA and HOT framework effectively enhances the robustness and generalization of rPPG models across diverse datasets.
Synergizing Deep Learning and Biological Heuristics for Extreme Long-Tail White Blood Cell Classification
Mar 17, 2026Automated white blood cell (WBC) classification is essential for leukemia screening but remains challenged by extreme class imbalance, long-tail distributions, and domain shift, leading deep models to overfit dominant classes and fail on rare subtypes. We propose a hybrid framework for rare-class generalization that integrates a generative Pix2Pix-based restoration module for artifact removal, a Swin Transformer ensemble with MedSigLIP contrastive embeddings for robust representation learning, and a biologically-inspired refinement step using geometric spikiness and Mahalanobis-based morphological constraints to recover out-of-distribution predictions. Evaluated on the WBCBench 2026 challenge, our method achieves a Macro-F1 of 0.77139 on the private leaderboard, demonstrating strong performance under severe imbalance and highlighting the value of incorporating biological priors into deep learning for hematological image analysis.
Handling Supervision Scarcity in Chest X-ray Classification: Long-Tailed and Zero-Shot Learning
Feb 13, 2026Chest X-ray (CXR) classification in clinical practice is often limited by imperfect supervision, arising from (i) extreme long-tailed multi-label disease distributions and (ii) missing annotations for rare or previously unseen findings. The CXR-LT 2026 challenge addresses these issues on a PadChest-based benchmark with a 36-class label space split into 30 in-distribution classes for training and 6 out-of-distribution (OOD) classes for zero-shot evaluation. We present task-specific solutions tailored to the distinct supervision regimes. For Task 1 (long-tailed multi-label classification), we adopt an imbalance-aware multi-label learning strategy to improve recognition of tail classes while maintaining stable performance on frequent findings. For Task 2 (zero-shot OOD recognition), we propose a prediction approach that produces scores for unseen disease categories without using any supervised labels or examples from the OOD classes during training. Evaluated with macro-averaged mean Average Precision (mAP), our method achieves strong performance on both tasks, ranking first on the public leaderboard of the development phase. Code and pre-trained models are available at https://github.com/hieuphamha19/CXR_LT.
Digital FAST: An AI-Driven Multimodal Framework for Rapid and Early Stroke Screening
Jan 17, 2026Early identification of stroke symptoms is essential for enabling timely intervention and improving patient outcomes, particularly in prehospital settings. This study presents a fast, non-invasive multimodal deep learning framework for automatic binary stroke screening based on data collected during the F.A.S.T. assessment. The proposed approach integrates complementary information from facial expressions, speech signals, and upper-body movements to enhance diagnostic robustness. Facial dynamics are represented using landmark based features and modeled with a Transformer architecture to capture temporal dependencies. Speech signals are converted into mel spectrograms and processed using an Audio Spectrogram Transformer, while upper-body pose sequences are analyzed with an MLP-Mixer network to model spatiotemporal motion patterns. The extracted modality specific representations are combined through an attention-based fusion mechanism to effectively learn cross modal interactions. Experiments conducted on a self-collected dataset of 222 videos from 37 subjects demonstrate that the proposed multimodal model consistently outperforms unimodal baselines, achieving 95.83% accuracy and a 96.00% F1-score. The model attains a strong balance between sensitivity and specificity and successfully detects all stroke cases in the test set. These results highlight the potential of multimodal learning and transfer learning for early stroke screening, while emphasizing the need for larger, clinically representative datasets to support reliable real-world deployment.
CLEAR: Causal Learning Framework For Robust Histopathology Tumor Detection Under Out-Of-Distribution Shifts
Oct 16, 2025Domain shift in histopathology, often caused by differences in acquisition processes or data sources, poses a major challenge to the generalization ability of deep learning models. Existing methods primarily rely on modeling statistical correlations by aligning feature distributions or introducing statistical variation, yet they often overlook causal relationships. In this work, we propose a novel causal-inference-based framework that leverages semantic features while mitigating the impact of confounders. Our method implements the front-door principle by designing transformation strategies that explicitly incorporate mediators and observed tissue slides. We validate our method on the CAMELYON17 dataset and a private histopathology dataset, demonstrating consistent performance gains across unseen domains. As a result, our approach achieved up to a 7% improvement in both the CAMELYON17 dataset and the private histopathology dataset, outperforming existing baselines. These results highlight the potential of causal inference as a powerful tool for addressing domain shift in histopathology image analysis.
Personalized Privacy-Preserving Framework for Cross-Silo Federated Learning
Feb 22, 2023
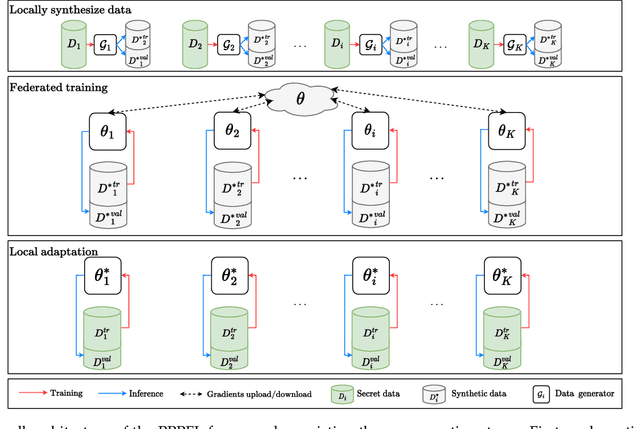
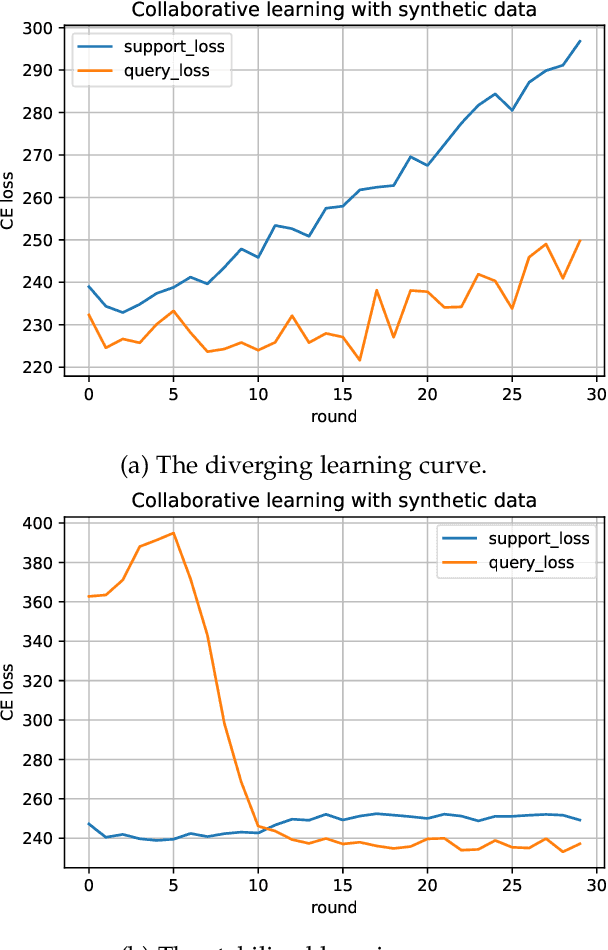
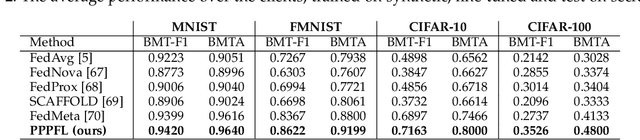
Federated learning (FL) is recently surging as a promising decentralized deep learning (DL) framework that enables DL-based approaches trained collaboratively across clients without sharing private data. However, in the context of the central party being active and dishonest, the data of individual clients might be perfectly reconstructed, leading to the high possibility of sensitive information being leaked. Moreover, FL also suffers from the nonindependent and identically distributed (non-IID) data among clients, resulting in the degradation in the inference performance on local clients' data. In this paper, we propose a novel framework, namely Personalized Privacy-Preserving Federated Learning (PPPFL), with a concentration on cross-silo FL to overcome these challenges. Specifically, we introduce a stabilized variant of the Model-Agnostic Meta-Learning (MAML) algorithm to collaboratively train a global initialization from clients' synthetic data generated by Differential Private Generative Adversarial Networks (DP-GANs). After reaching convergence, the global initialization will be locally adapted by the clients to their private data. Through extensive experiments, we empirically show that our proposed framework outperforms multiple FL baselines on different datasets, including MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100.