 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Post-Processing Tool and Feasibility Study for Three-Dimensional Imaging with Electrical Impedance Tomography During Deep Brain Stimulation Surgery
Apr 11, 2022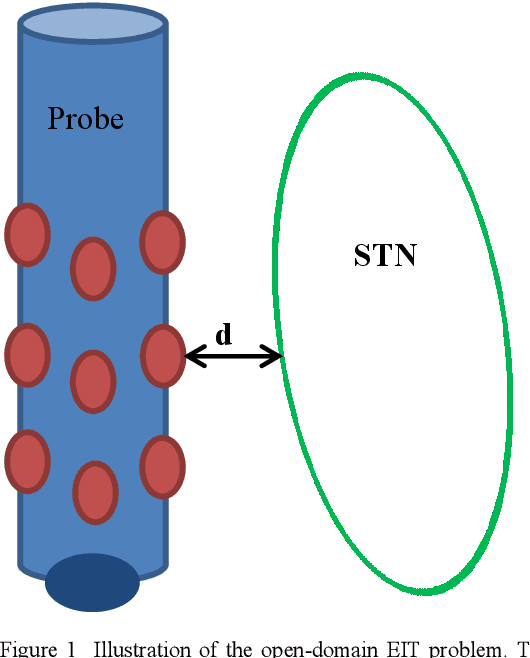
Electrical impedance tomography (EIT) is a promising technique for biomedical imaging. The strength of EIT is its ability to reconstruct images of the body's internal structures through radiation-safe techniques. EIT is regarded as safe for patients' health, and it is currently being actively researched. This paper investigates the application of EIT during deep brain stimulation (DBS) surgery as a means to identify targets during operations. DBS involves a surgical procedure in which a lead or electrode array is implanted in a specific target area in the brain. Electrical stimulations are then used to modulate neural circuits within the target area to reduce disabling neurological symptoms. The main difficulty in performing DBS surgery is to accurately position the lead in the target area before commencing the treatment. Brain tissue shifts during DBS surgery can be as large as the target size when compared with the pre-operative magnetic resonance imaging (MRI) or computed tomography (CT) images. To address this problem, a solution based on open-domain EIT to reconstruct images surrounding the probe during DBS surgery is proposed. Data acquisition and image reconstruction were performed, and artificial intelligence was applied to enhance the resulting images. The results showed that the proposed method is rapid, produces valuable high-quality images, and constitutes a first step towards in-vivo study.
A Feasibility Study on Real-Time High Resolution Imaging of the Brain Using Electrical Impedance Tomography
Mar 07, 2022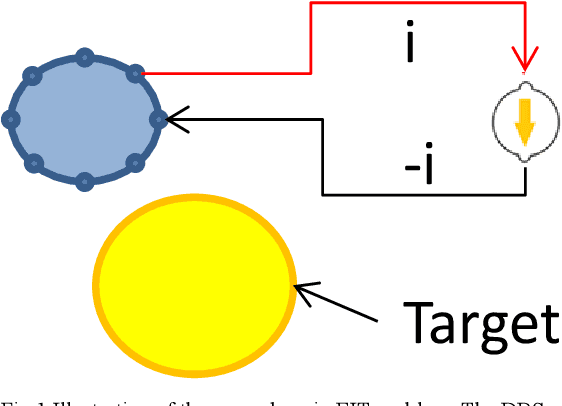
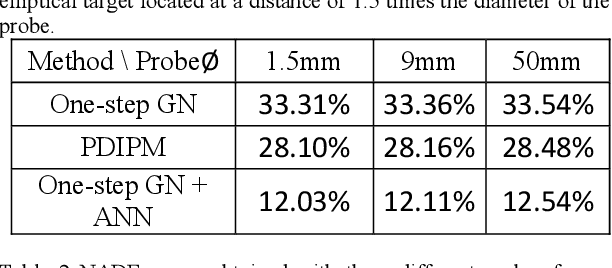


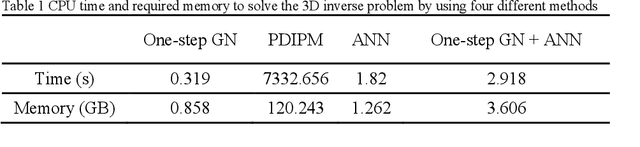
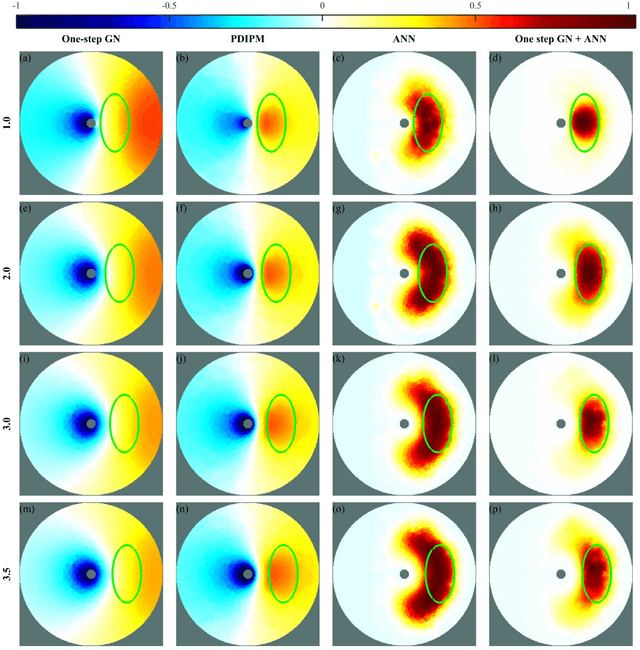
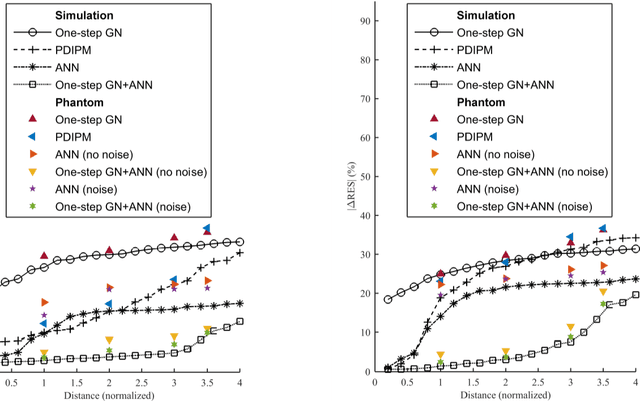
Objective: The strengths of Electrical Impedance Tomography (EIT) are its capability of imaging the internal body by using a noninvasive, radiation safe technique, and the absence of known hazards. In this paper we introduce a novel idea of using EIT in microelectrodes during Deep Brain Stimulation (DBS) surgery in order to obtain an image of the electrical conductivities of the brain tissues surrounding the microelectrodes. DBS is a surgical treatment involving the implantation of a medical probe inside the brain. For such application, the EIT reconstruction method has to offer both high quality and robustness against noise. Methods: A post-processing method for open-domain EIT is introduced in this paper, which combines linear and nonlinear methods in order to use the advantages of both with limited drawbacks. The reconstruction method is a two-steps method, the first solves the inverse problem with a linear algorithm and the second brings the nonlinear aspects back into the image. Results: The proposed method is tested on both simulation and phantom data, and compared to three widely used method for EIT imaging. Resulting images and errors gives a strong advantage to the proposed solution. Conclusion: High quality reconstruction from phantom data validates the efficiency of the novel reconstruction method. Significance: This feasibility study presents an efficient method for open domain EIT and opens the way to clinical trials.
Optimal Explanations of Linear Models
Jul 08, 2019
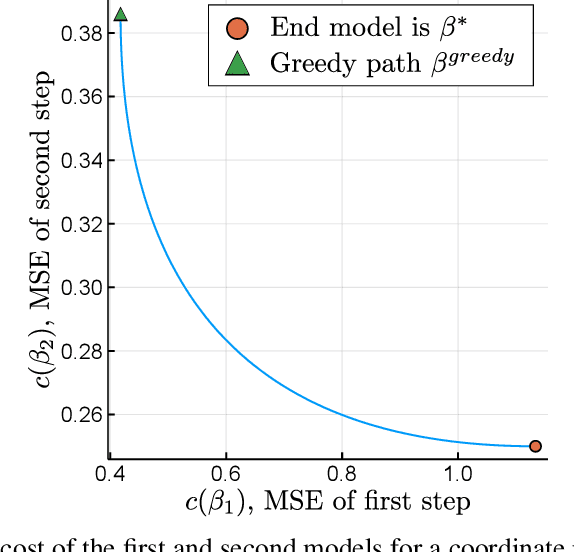
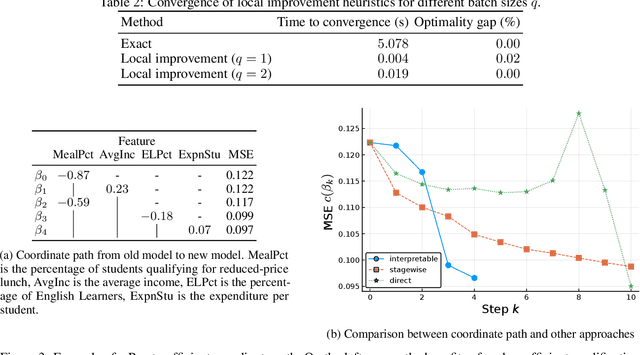
When predictive models are used to support complex and important decisions, the ability to explain a model's reasoning can increase trust, expose hidden biases, and reduce vulnerability to adversarial attacks. However, attempts at interpreting models are often ad hoc and application-specific, and the concept of interpretability itself is not well-defined. We propose a general optimization framework to create explanations for linear models. Our methodology decomposes a linear model into a sequence of models of increasing complexity using coordinate updates on the coefficients. Computing this decomposition optimally is a difficult optimization problem for which we propose exact algorithms and scalable heuristics. By solving this problem, we can derive a parametrized family of interpretability metrics for linear models that generalizes typical proxies, and study the tradeoff between interpretability and predictive accuracy.
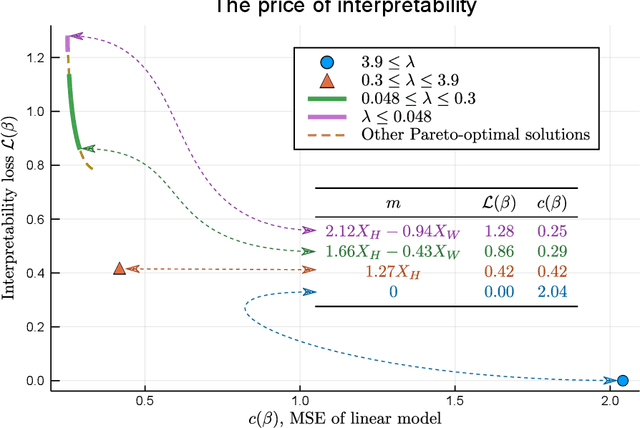
The Price of Interpretability
Jul 08, 2019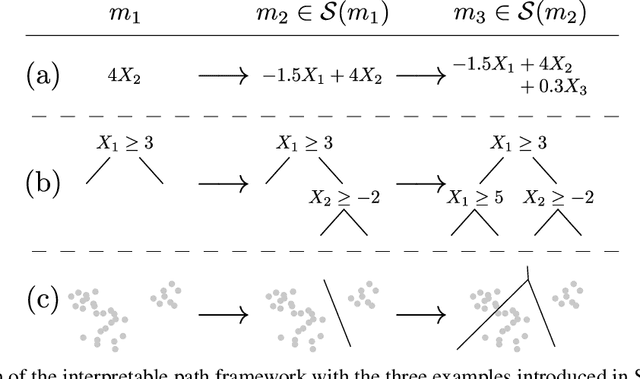

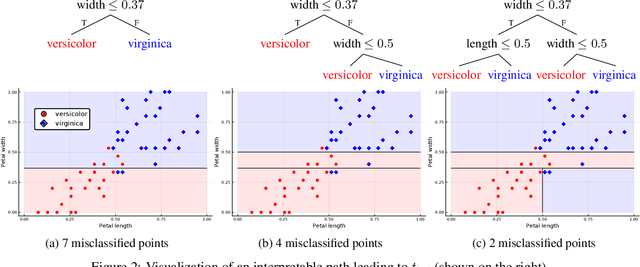

When quantitative models are used to support decision-making on complex and important topics, understanding a model's ``reasoning'' can increase trust in its predictions, expose hidden biases, or reduce vulnerability to adversarial attacks. However, the concept of interpretability remains loosely defined and application-specific. In this paper, we introduce a mathematical framework in which machine learning models are constructed in a sequence of interpretable steps. We show that for a variety of models, a natural choice of interpretable steps recovers standard interpretability proxies (e.g., sparsity in linear models). We then generalize these proxies to yield a parametrized family of consistent measures of model interpretability. This formal definition allows us to quantify the ``price'' of interpretability, i.e., the tradeoff with predictive accuracy. We demonstrate practical algorithms to apply our framework on real and synthetic datasets.