 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Explanations of Linear Models
Paper and Code
Jul 08, 2019
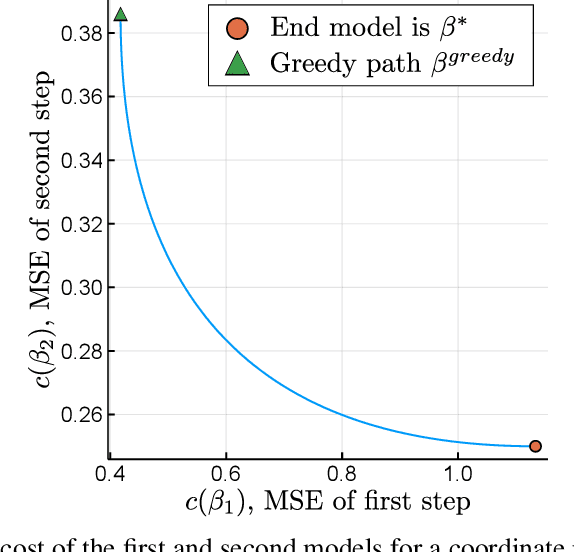
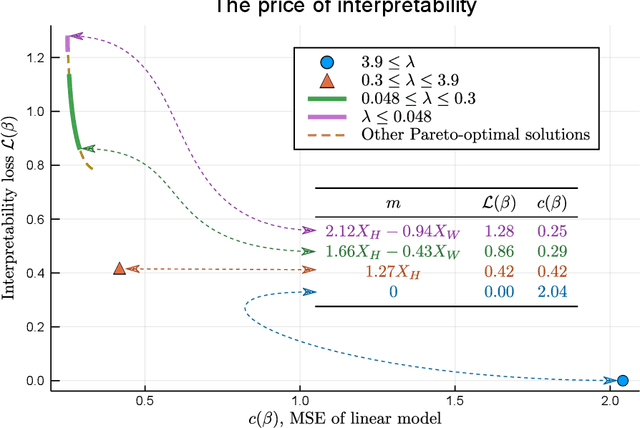
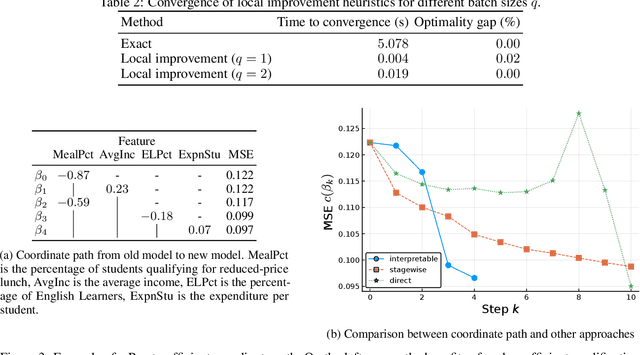
When predictive models are used to support complex and important decisions, the ability to explain a model's reasoning can increase trust, expose hidden biases, and reduce vulnerability to adversarial attacks. However, attempts at interpreting models are often ad hoc and application-specific, and the concept of interpretability itself is not well-defined. We propose a general optimization framework to create explanations for linear models. Our methodology decomposes a linear model into a sequence of models of increasing complexity using coordinate updates on the coefficients. Computing this decomposition optimally is a difficult optimization problem for which we propose exact algorithms and scalable heuristics. By solving this problem, we can derive a parametrized family of interpretability metrics for linear models that generalizes typical proxies, and study the tradeoff between interpretability and predictive accuracy.