 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan an LLM-Powered Socially Assistive Robot Effectively and Safely Deliver Cognitive Behavioral Therapy? A Study With University Students
Feb 27, 2024
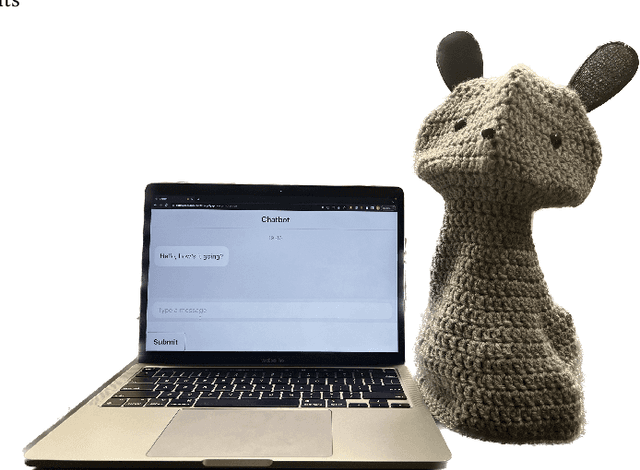
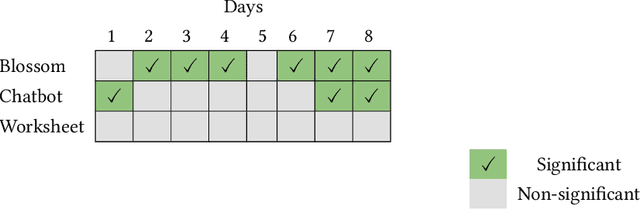

Cognitive behavioral therapy (CBT) is a widely used therapeutic method for guiding individuals toward restructuring their thinking patterns as a means of addressing anxiety, depression, and other challenges. We developed a large language model (LLM)-powered prompt-engineered socially assistive robot (SAR) that guides participants through interactive CBT at-home exercises. We evaluated the performance of the SAR through a 15-day study with 38 university students randomly assigned to interact daily with the robot or a chatbot (using the same LLM), or complete traditional CBT worksheets throughout the duration of the study. We measured weekly therapeutic outcomes, changes in pre-/post-session anxiety measures, and adherence to completing CBT exercises. We found that self-reported measures of general psychological distress significantly decreased over the study period in the robot and worksheet conditions but not the chatbot condition. Furthermore, the SAR enabled significant single-session improvements for more sessions than the other two conditions combined. Our findings suggest that SAR-guided LLM-powered CBT may be as effective as traditional worksheet methods in supporting therapeutic progress from the beginning to the end of the study and superior in decreasing user anxiety immediately after completing the CBT exercise.
Policy Learning and Evaluation with Randomized Quasi-Monte Carlo
Feb 21, 2022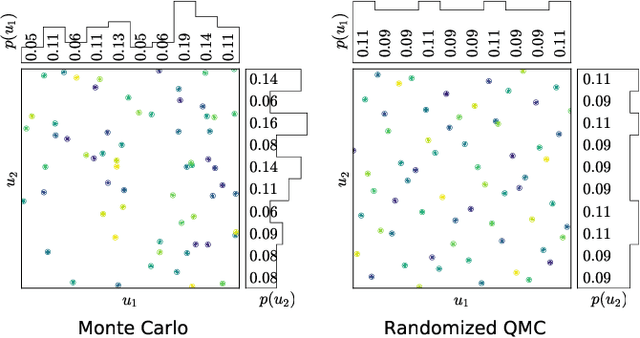
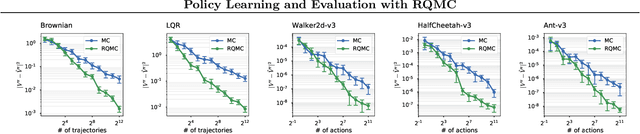
Reinforcement learning constantly deals with hard integrals, for example when computing expectations in policy evaluation and policy iteration. These integrals are rarely analytically solvable and typically estimated with the Monte Carlo method, which induces high variance in policy values and gradients. In this work, we propose to replace Monte Carlo samples with low-discrepancy point sets. We combine policy gradient methods with Randomized Quasi-Monte Carlo, yielding variance-reduced formulations of policy gradient and actor-critic algorithms. These formulations are effective for policy evaluation and policy improvement, as they outperform state-of-the-art algorithms on standardized continuous control benchmarks. Our empirical analyses validate the intuition that replacing Monte Carlo with Quasi-Monte Carlo yields significantly more accurate gradient estimates.