 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Learning and Evaluation with Randomized Quasi-Monte Carlo
Paper and Code
Feb 21, 2022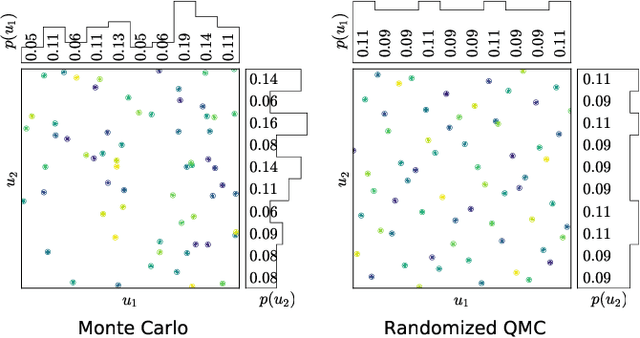
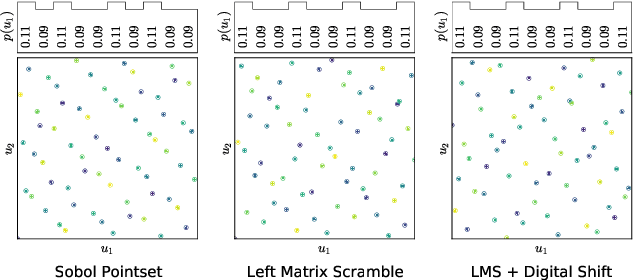
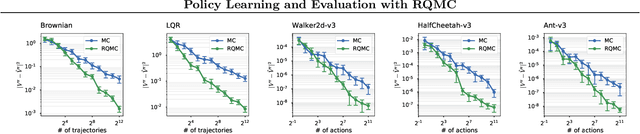
Reinforcement learning constantly deals with hard integrals, for example when computing expectations in policy evaluation and policy iteration. These integrals are rarely analytically solvable and typically estimated with the Monte Carlo method, which induces high variance in policy values and gradients. In this work, we propose to replace Monte Carlo samples with low-discrepancy point sets. We combine policy gradient methods with Randomized Quasi-Monte Carlo, yielding variance-reduced formulations of policy gradient and actor-critic algorithms. These formulations are effective for policy evaluation and policy improvement, as they outperform state-of-the-art algorithms on standardized continuous control benchmarks. Our empirical analyses validate the intuition that replacing Monte Carlo with Quasi-Monte Carlo yields significantly more accurate gradient estimates.