 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupercharging Bayesian Inference with Reliable AI-Informed Priors
May 11, 2026Modern predictive systems encode beliefs that can act as useful prior information for statistical inference in data-limited settings. Using them for prior construction introduces a tradeoff: an informative prior built from a predictive model can sharpen inference from limited data, but also risks propagating error from the model into the posterior. We propose a framework for AI-informed prior elicitation that mitigates this tension by rectifying the AI-induced law that generates synthetic data before using it to inform a prior. The rectified law can be embedded into synthetic data-driven prior elicitation techniques, including as a base measure in a Dirichlet process (DP) prior on the data-generating process. We refer to the resulting prior and corresponding posterior as the rectified AI prior and rectified AI posterior. We establish Gaussian asymptotics for the rectified AI posterior under non-vanishing prior strength and derive a first-order expression for its centering bias. Our rectified AI priors substantially reduce bias compared to standard approaches, improve the coverage of credible intervals, and make AI-powered prior information more reliable. We additionally apply the rectified AI prior to a real skin disease classification task and show that it can meaningfully boost predictive performance.
Generative Bayesian Filtering and Parameter Learning
Nov 06, 2025Generative Bayesian Filtering (GBF) provides a powerful and flexible framework for performing posterior inference in complex nonlinear and non-Gaussian state-space models. Our approach extends Generative Bayesian Computation (GBC) to dynamic settings, enabling recursive posterior inference using simulation-based methods powered by deep neural networks. GBF does not require explicit density evaluations, making it particularly effective when observation or transition distributions are analytically intractable. To address parameter learning, we introduce the Generative-Gibbs sampler, which bypasses explicit density evaluation by iteratively sampling each variable from its implicit full conditional distribution. Such technique is broadly applicable and enables inference in hierarchical Bayesian models with intractable densities, including state-space models. We assess the performance of the proposed methodologies through both simulated and empirical studies, including the estimation of $\alpha$-stable stochastic volatility models. Our findings indicate that GBF significantly outperforms existing likelihood-free approaches in accuracy and robustness when dealing with intractable state-space models.
AI-Powered Bayesian Inference
Feb 26, 2025The advent of Generative Artificial Intelligence (GAI) has heralded an inflection point that changed how society thinks about knowledge acquisition. While GAI cannot be fully trusted for decision-making, it may still provide valuable information that can be integrated into a decision pipeline. Rather than seeing the lack of certitude and inherent randomness of GAI as a problem, we view it as an opportunity. Indeed, variable answers to given prompts can be leveraged to construct a prior distribution which reflects assuredness of AI predictions. This prior distribution may be combined with tailored datasets for a fully Bayesian analysis with an AI-driven prior. In this paper, we explore such a possibility within a non-parametric Bayesian framework. The basic idea consists of assigning a Dirichlet process prior distribution on the data-generating distribution with AI generative model as its baseline. Hyper-parameters of the prior can be tuned out-of-sample to assess the informativeness of the AI prior. Posterior simulation is achieved by computing a suitably randomized functional on an augmented data that consists of observed (labeled) data as well as fake data whose labels have been imputed using AI. This strategy can be parallelized and rapidly produces iid samples from the posterior by optimization as opposed to sampling from conditionals. Our method enables (predictive) inference and uncertainty quantification leveraging AI predictions in a coherent probabilistic manner.
Tree Bandits for Generative Bayes
Apr 16, 2024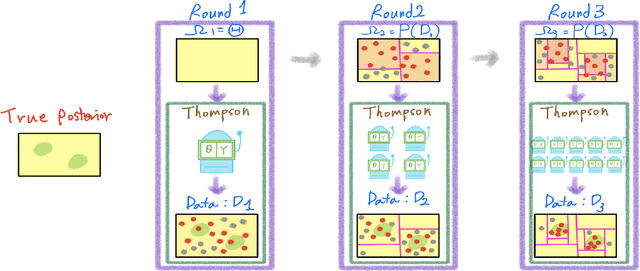
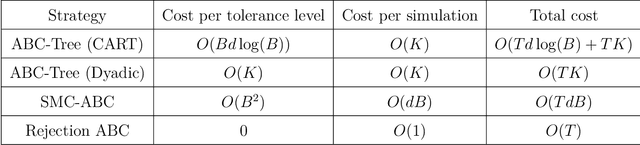
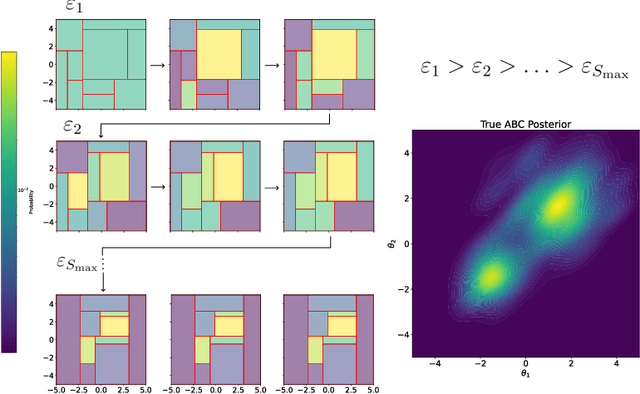
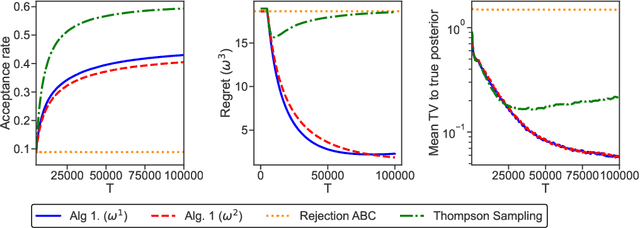
In generative models with obscured likelihood, Approximate Bayesian Computation (ABC) is often the tool of last resort for inference. However, ABC demands many prior parameter trials to keep only a small fraction that passes an acceptance test. To accelerate ABC rejection sampling, this paper develops a self-aware framework that learns from past trials and errors. We apply recursive partitioning classifiers on the ABC lookup table to sequentially refine high-likelihood regions into boxes. Each box is regarded as an arm in a binary bandit problem treating ABC acceptance as a reward. Each arm has a proclivity for being chosen for the next ABC evaluation, depending on the prior distribution and past rejections. The method places more splits in those areas where the likelihood resides, shying away from low-probability regions destined for ABC rejections. We provide two versions: (1) ABC-Tree for posterior sampling, and (2) ABC-MAP for maximum a posteriori estimation. We demonstrate accurate ABC approximability at much lower simulation cost. We justify the use of our tree-based bandit algorithms with nearly optimal regret bounds. Finally, we successfully apply our approach to the problem of masked image classification using deep generative models.
Measurement in the Age of LLMs: An Application to Ideological Scaling
Dec 14, 2023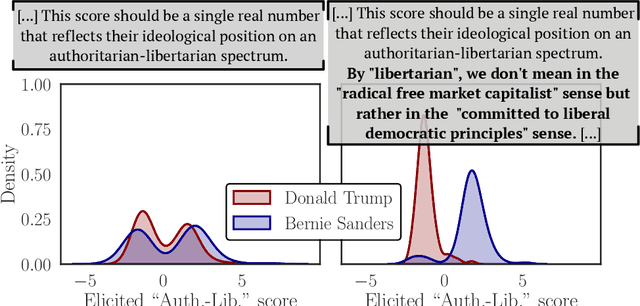

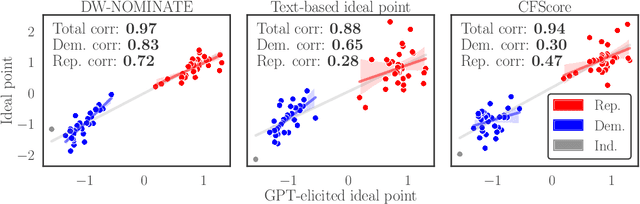
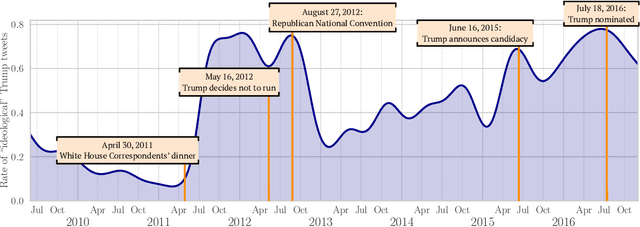
Much of social science is centered around terms like ``ideology'' or ``power'', which generally elude precise definition, and whose contextual meanings are trapped in surrounding language. This paper explores the use of large language models (LLMs) to flexibly navigate the conceptual clutter inherent to social scientific measurement tasks. We rely on LLMs' remarkable linguistic fluency to elicit ideological scales of both legislators and text, which accord closely to established methods and our own judgement. A key aspect of our approach is that we elicit such scores directly, instructing the LLM to furnish numeric scores itself. This approach affords a great deal of flexibility, which we showcase through a variety of different case studies. Our results suggest that LLMs can be used to characterize highly subtle and diffuse manifestations of political ideology in text.