 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILCiteR: Evidence-grounded Interpretable Local Citation Recommendation
Mar 13, 2024Existing Machine Learning approaches for local citation recommendation directly map or translate a query, which is typically a claim or an entity mention, to citation-worthy research papers. Within such a formulation, it is challenging to pinpoint why one should cite a specific research paper for a particular query, leading to limited recommendation interpretability. To alleviate this, we introduce the evidence-grounded local citation recommendation task, where the target latent space comprises evidence spans for recommending specific papers. Using a distantly-supervised evidence retrieval and multi-step re-ranking framework, our proposed system, ILCiteR, recommends papers to cite for a query grounded on similar evidence spans extracted from the existing research literature. Unlike past formulations that simply output recommendations, ILCiteR retrieves ranked lists of evidence span and recommended paper pairs. Secondly, previously proposed neural models for citation recommendation require expensive training on massive labeled data, ideally after every significant update to the pool of candidate papers. In contrast, ILCiteR relies solely on distant supervision from a dynamic evidence database and pre-trained Transformer-based Language Models without any model training. We contribute a novel dataset for the evidence-grounded local citation recommendation task and demonstrate the efficacy of our proposed conditional neural rank-ensembling approach for re-ranking evidence spans.
Towards Proactively Forecasting Sentence-Specific Information Popularity within Online News Documents
Dec 31, 2022



Multiple studies have focused on predicting the prospective popularity of an online document as a whole, without paying attention to the contributions of its individual parts. We introduce the task of proactively forecasting popularities of sentences within online news documents solely utilizing their natural language content. We model sentence-specific popularity forecasting as a sequence regression task. For training our models, we curate InfoPop, the first dataset containing popularity labels for over 1.7 million sentences from over 50,000 online news documents. To the best of our knowledge, this is the first dataset automatically created using streams of incoming search engine queries to generate sentence-level popularity annotations. We propose a novel transfer learning approach involving sentence salience prediction as an auxiliary task. Our proposed technique coupled with a BERT-based neural model exceeds nDCG values of 0.8 for proactive sentence-specific popularity forecasting. Notably, our study presents a non-trivial takeaway: though popularity and salience are different concepts, transfer learning from salience prediction enhances popularity forecasting. We release InfoPop and make our code publicly available: https://github.com/sayarghoshroy/InfoPopularity
* In 33rd ACM Conference on Hypertext and Social Media [HT '22] (Main Track), Link: https://dl.acm.org/doi/10.1145/3511095.3531268
Summaformers @ LaySumm 20, LongSumm 20
Jan 10, 2021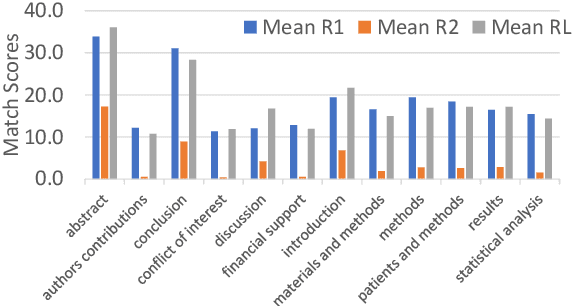
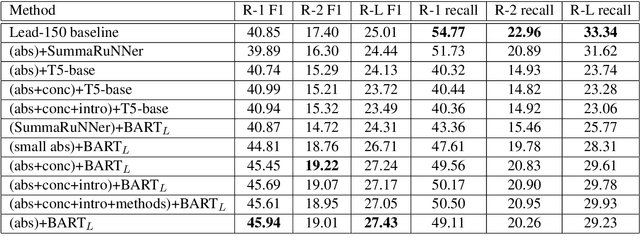
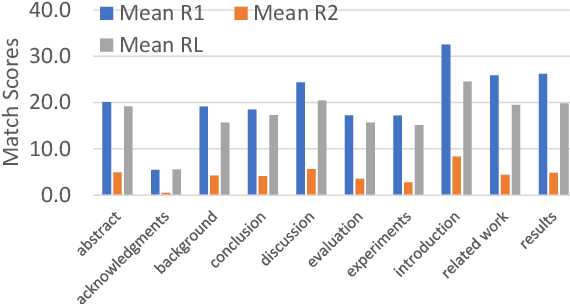

Automatic text summarization has been widely studied as an important task in natural language processing. Traditionally, various feature engineering and machine learning based systems have been proposed for extractive as well as abstractive text summarization. Recently, deep learning based, specifically Transformer-based systems have been immensely popular. Summarization is a cognitively challenging task - extracting summary worthy sentences is laborious, and expressing semantics in brief when doing abstractive summarization is complicated. In this paper, we specifically look at the problem of summarizing scientific research papers from multiple domains. We differentiate between two types of summaries, namely, (a) LaySumm: A very short summary that captures the essence of the research paper in layman terms restricting overtly specific technical jargon and (b) LongSumm: A much longer detailed summary aimed at providing specific insights into various ideas touched upon in the paper. While leveraging latest Transformer-based models, our systems are simple, intuitive and based on how specific paper sections contribute to human summaries of the two types described above. Evaluations against gold standard summaries using ROUGE metrics prove the effectiveness of our approach. On blind test corpora, our system ranks first and third for the LongSumm and LaySumm tasks respectively.
* Proceedings of the First Workshop on Scholarly Document Processing (SDP) at EMNLP 2020
Task Adaptive Pretraining of Transformers for Hostility Detection
Jan 09, 2021
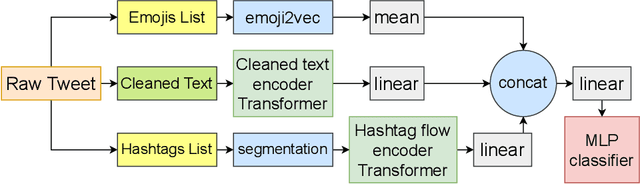
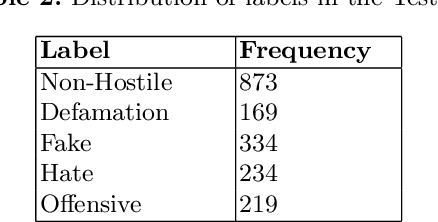
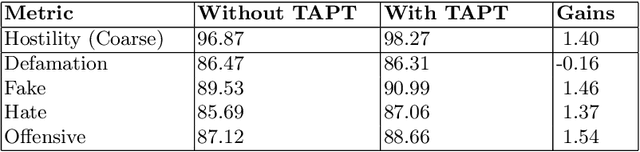
Identifying adverse and hostile content on the web and more particularly, on social media, has become a problem of paramount interest in recent years. With their ever increasing popularity, fine-tuning of pretrained Transformer-based encoder models with a classifier head are gradually becoming the new baseline for natural language classification tasks. In our work, we explore the gains attributed to Task Adaptive Pretraining (TAPT) prior to fine-tuning of Transformer-based architectures. We specifically study two problems, namely, (a) Coarse binary classification of Hindi Tweets into Hostile or Not, and (b) Fine-grained multi-label classification of Tweets into four categories: hate, fake, offensive, and defamation. Building up on an architecture which takes emojis and segmented hashtags into consideration for classification, we are able to experimentally showcase the performance upgrades due to TAPT. Our system (with team name 'iREL IIIT') ranked first in the 'Hostile Post Detection in Hindi' shared task with an F1 score of 97.16% for coarse-grained detection and a weighted F1 score of 62.96% for fine-grained multi-label classification on the provided blind test corpora.
Leveraging Multilingual Transformers for Hate Speech Detection
Jan 08, 2021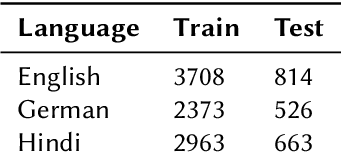
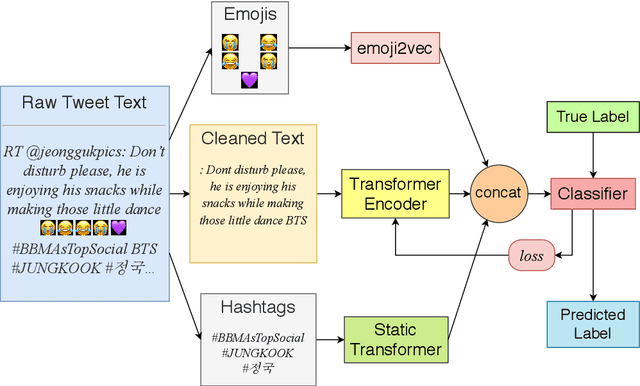
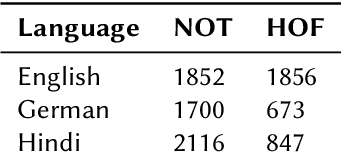
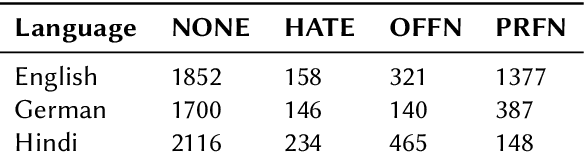
Detecting and classifying instances of hate in social media text has been a problem of interest in Natural Language Processing in the recent years. Our work leverages state of the art Transformer language models to identify hate speech in a multilingual setting. Capturing the intent of a post or a comment on social media involves careful evaluation of the language style, semantic content and additional pointers such as hashtags and emojis. In this paper, we look at the problem of identifying whether a Twitter post is hateful and offensive or not. We further discriminate the detected toxic content into one of the following three classes: (a) Hate Speech (HATE), (b) Offensive (OFFN) and (c) Profane (PRFN). With a pre-trained multilingual Transformer-based text encoder at the base, we are able to successfully identify and classify hate speech from multiple languages. On the provided testing corpora, we achieve Macro F1 scores of 90.29, 81.87 and 75.40 for English, German and Hindi respectively while performing hate speech detection and of 60.70, 53.28 and 49.74 during fine-grained classification. In our experiments, we show the efficacy of Perspective API features for hate speech classification and the effects of exploiting a multilingual training scheme. A feature selection study is provided to illustrate impacts of specific features upon the architecture's classification head.