 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Proactively Forecasting Sentence-Specific Information Popularity within Online News Documents
Dec 31, 2022



Multiple studies have focused on predicting the prospective popularity of an online document as a whole, without paying attention to the contributions of its individual parts. We introduce the task of proactively forecasting popularities of sentences within online news documents solely utilizing their natural language content. We model sentence-specific popularity forecasting as a sequence regression task. For training our models, we curate InfoPop, the first dataset containing popularity labels for over 1.7 million sentences from over 50,000 online news documents. To the best of our knowledge, this is the first dataset automatically created using streams of incoming search engine queries to generate sentence-level popularity annotations. We propose a novel transfer learning approach involving sentence salience prediction as an auxiliary task. Our proposed technique coupled with a BERT-based neural model exceeds nDCG values of 0.8 for proactive sentence-specific popularity forecasting. Notably, our study presents a non-trivial takeaway: though popularity and salience are different concepts, transfer learning from salience prediction enhances popularity forecasting. We release InfoPop and make our code publicly available: https://github.com/sayarghoshroy/InfoPopularity
* In 33rd ACM Conference on Hypertext and Social Media [HT '22] (Main Track), Link: https://dl.acm.org/doi/10.1145/3511095.3531268
Summaformers @ LaySumm 20, LongSumm 20
Jan 10, 2021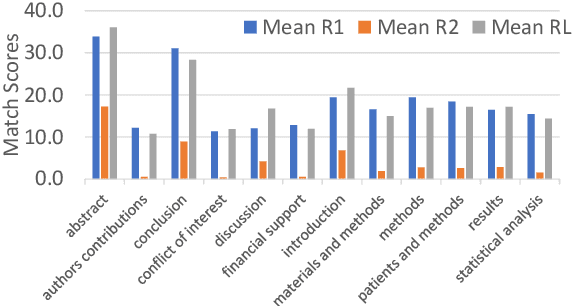
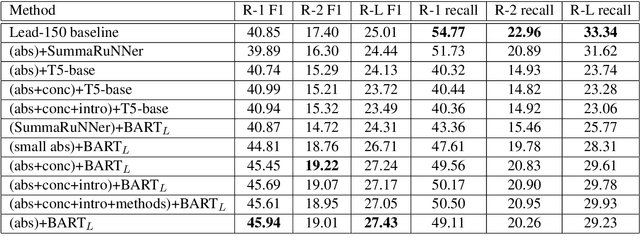
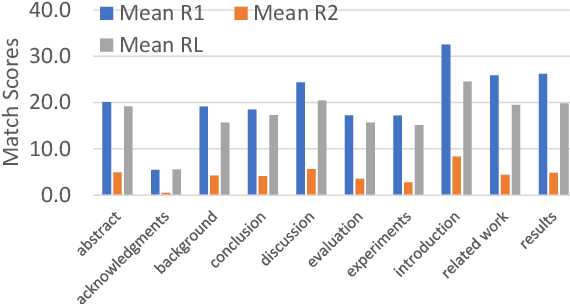

Automatic text summarization has been widely studied as an important task in natural language processing. Traditionally, various feature engineering and machine learning based systems have been proposed for extractive as well as abstractive text summarization. Recently, deep learning based, specifically Transformer-based systems have been immensely popular. Summarization is a cognitively challenging task - extracting summary worthy sentences is laborious, and expressing semantics in brief when doing abstractive summarization is complicated. In this paper, we specifically look at the problem of summarizing scientific research papers from multiple domains. We differentiate between two types of summaries, namely, (a) LaySumm: A very short summary that captures the essence of the research paper in layman terms restricting overtly specific technical jargon and (b) LongSumm: A much longer detailed summary aimed at providing specific insights into various ideas touched upon in the paper. While leveraging latest Transformer-based models, our systems are simple, intuitive and based on how specific paper sections contribute to human summaries of the two types described above. Evaluations against gold standard summaries using ROUGE metrics prove the effectiveness of our approach. On blind test corpora, our system ranks first and third for the LongSumm and LaySumm tasks respectively.
* Proceedings of the First Workshop on Scholarly Document Processing (SDP) at EMNLP 2020