 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummaformers @ LaySumm 20, LongSumm 20
Paper and Code
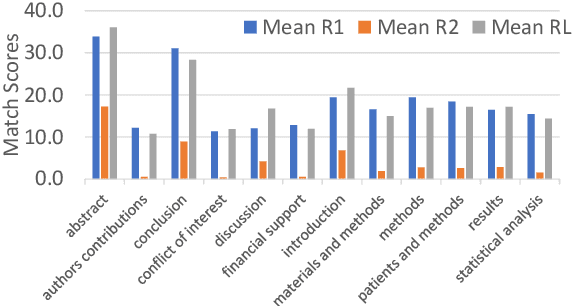
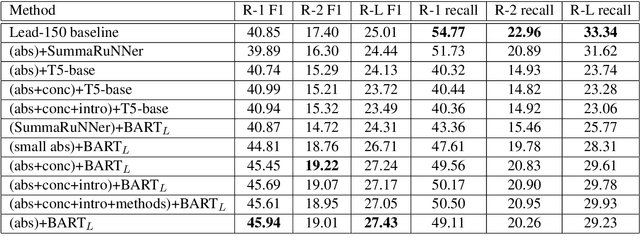
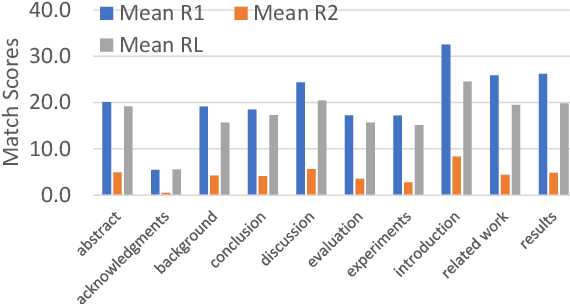

Automatic text summarization has been widely studied as an important task in natural language processing. Traditionally, various feature engineering and machine learning based systems have been proposed for extractive as well as abstractive text summarization. Recently, deep learning based, specifically Transformer-based systems have been immensely popular. Summarization is a cognitively challenging task - extracting summary worthy sentences is laborious, and expressing semantics in brief when doing abstractive summarization is complicated. In this paper, we specifically look at the problem of summarizing scientific research papers from multiple domains. We differentiate between two types of summaries, namely, (a) LaySumm: A very short summary that captures the essence of the research paper in layman terms restricting overtly specific technical jargon and (b) LongSumm: A much longer detailed summary aimed at providing specific insights into various ideas touched upon in the paper. While leveraging latest Transformer-based models, our systems are simple, intuitive and based on how specific paper sections contribute to human summaries of the two types described above. Evaluations against gold standard summaries using ROUGE metrics prove the effectiveness of our approach. On blind test corpora, our system ranks first and third for the LongSumm and LaySumm tasks respectively.