 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Multilingual Transformers for Hate Speech Detection
Paper and Code
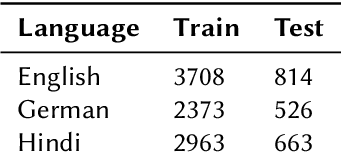
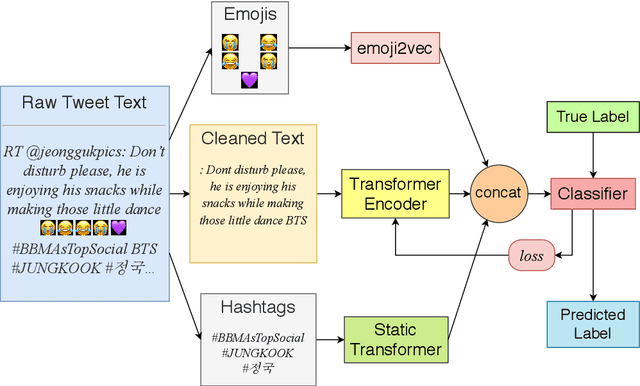
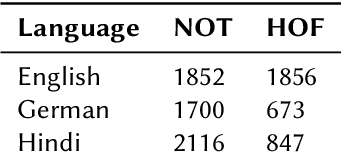
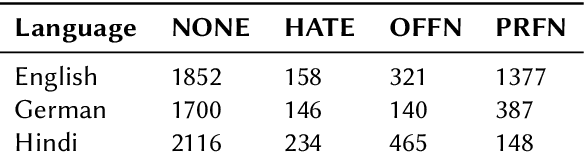
Detecting and classifying instances of hate in social media text has been a problem of interest in Natural Language Processing in the recent years. Our work leverages state of the art Transformer language models to identify hate speech in a multilingual setting. Capturing the intent of a post or a comment on social media involves careful evaluation of the language style, semantic content and additional pointers such as hashtags and emojis. In this paper, we look at the problem of identifying whether a Twitter post is hateful and offensive or not. We further discriminate the detected toxic content into one of the following three classes: (a) Hate Speech (HATE), (b) Offensive (OFFN) and (c) Profane (PRFN). With a pre-trained multilingual Transformer-based text encoder at the base, we are able to successfully identify and classify hate speech from multiple languages. On the provided testing corpora, we achieve Macro F1 scores of 90.29, 81.87 and 75.40 for English, German and Hindi respectively while performing hate speech detection and of 60.70, 53.28 and 49.74 during fine-grained classification. In our experiments, we show the efficacy of Perspective API features for hate speech classification and the effects of exploiting a multilingual training scheme. A feature selection study is provided to illustrate impacts of specific features upon the architecture's classification head.