 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomness Is All You Need: Semantic Traversal of Problem-Solution Spaces with Large Language Models
Feb 08, 2024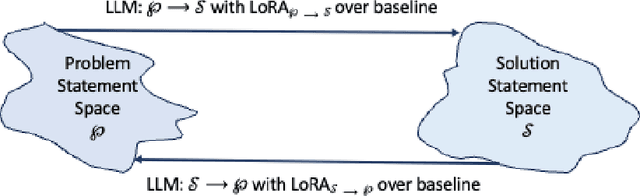



We present a novel approach to exploring innovation problem and solution domains using LLM fine-tuning with a custom idea database. By semantically traversing the bi-directional problem and solution tree at different temperature levels we achieve high diversity in solution edit distance while still remaining close to the original problem statement semantically. In addition to finding a variety of solutions to a given problem, this method can also be used to refine and clarify the original problem statement. As further validation of the approach, we implemented a proof-of-concept Slack bot to serve as an innovation assistant.
Why Neural Networks Work
Nov 26, 2022We argue that many properties of fully-connected feedforward neural networks (FCNNs), also called multi-layer perceptrons (MLPs), are explainable from the analysis of a single pair of operations, namely a random projection into a higher-dimensional space than the input, followed by a sparsification operation. For convenience, we call this pair of successive operations expand-and-sparsify following the terminology of Dasgupta. We show how expand-and-sparsify can explain the observed phenomena that have been discussed in the literature, such as the so-called Lottery Ticket Hypothesis, the surprisingly good performance of randomly-initialized untrained neural networks, the efficacy of Dropout in training and most importantly, the mysterious generalization ability of overparameterized models, first highlighted by Zhang et al. and subsequently identified even in non-neural network models by Belkin et al.
Reinforcement Learning for Standards Design
Oct 13, 2021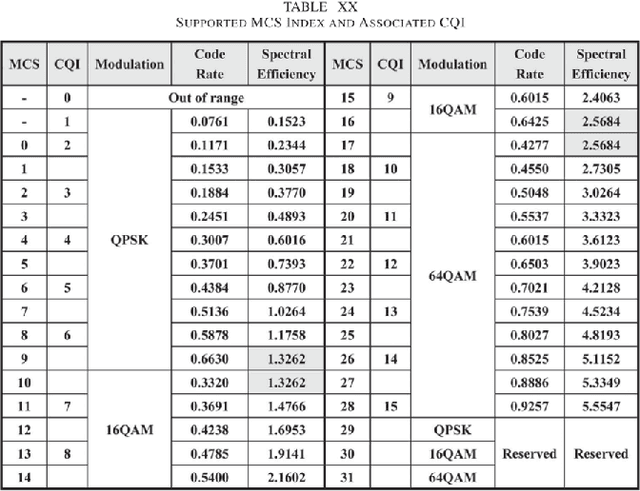

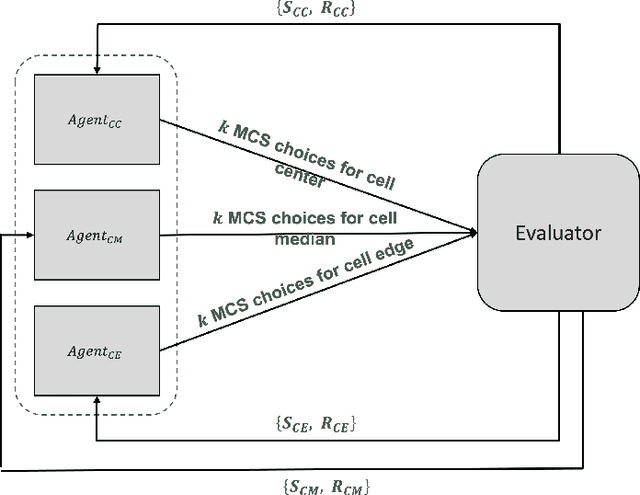
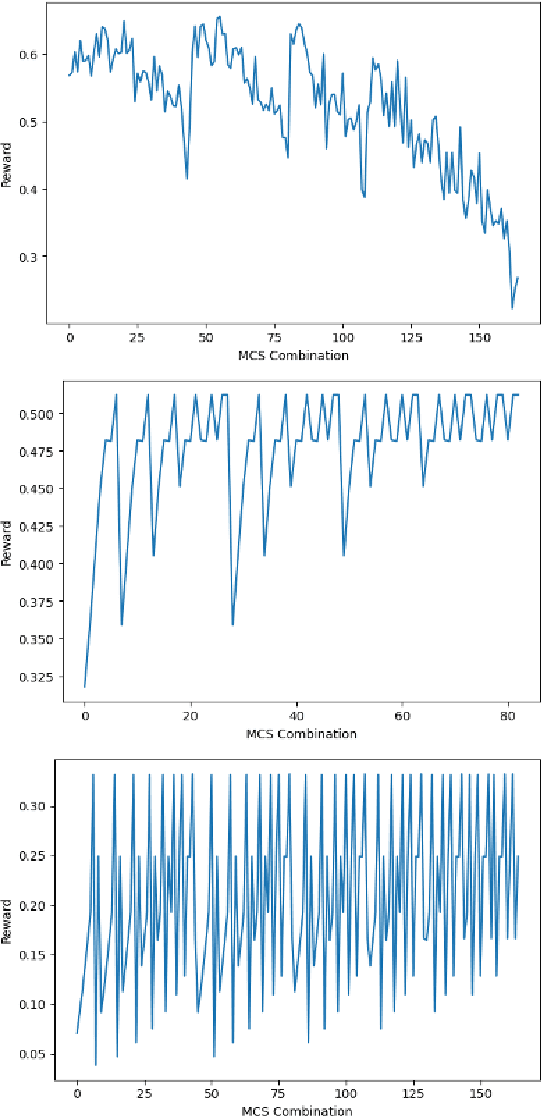
Communications standards are designed via committees of humans holding repeated meetings over months or even years until consensus is achieved. This includes decisions regarding the modulation and coding schemes to be supported over an air interface. We propose a way to "automate" the selection of the set of modulation and coding schemes to be supported over a given air interface and thereby streamline both the standards design process and the ease of extending the standard to support new modulation schemes applicable to new higher-level applications and services. Our scheme involves machine learning, whereby a constructor entity submits proposals to an evaluator entity, which returns a score for the proposal. The constructor employs reinforcement learning to iterate on its submitted proposals until a score is achieved that was previously agreed upon by both constructor and evaluator to be indicative of satisfying the required design criteria (including performance metrics for transmissions over the interface).
General Information Bottleneck Objectives and their Applications to Machine Learning
Dec 20, 2019

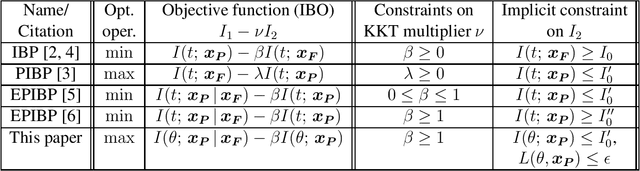
We view the Information Bottleneck Principle (IBP: Tishby et al., 1999; Schwartz-Ziv and Tishby, 2017) and Predictive Information Bottleneck Principle (PIBP: Still et al., 2007; Alemi, 2019) as special cases of a family of general information bottleneck objectives (IBOs). Each IBO corresponds to a particular constrained optimization problem where the constraints apply to: (a) the mutual information between the training data and the learned model parameters or extracted representation of the data, and (b) the mutual information between the learned model parameters or extracted representation of the data and the test data (if any). The heuristics behind the IBP and PIBP are shown to yield different constraints in the corresponding constrained optimization problem formulations. We show how other heuristics lead to a new IBO, different from both the IBP and PIBP, and use the techniques from (Alemi, 2019) to derive and optimize a variational upper bound on the new IBO. We then apply the theory of general IBOs to resolve the seeming contradiction between, on the one hand, the recommendations of IBP and PIBP to maximize the mutual information between the model parameters and test data, and on the other, recent information-theoretic results (see Xu and Raginsky, 2017) suggesting that this mutual information should be minimized. The key insight is that the heuristics (and thus the constraints in the constrained optimization problems) of IBP and PIBP are not applicable to the scenario analyzed by (Xu and Raginsky, 2017) because the latter makes the additional assumption that the parameters of the trained model have been selected to minimize the empirical loss function. Aided by this insight, we formulate a new IBO that accounts for this property of the parameters of the trained model, and derive and optimize a variational bound on this IBO.
Machine Learning using the Variational Predictive Information Bottleneck with a Validation Set
Dec 11, 2019Zellner (1988) modeled statistical inference in terms of information processing and postulated the Information Conservation Principle (ICP) between the input and output of the information processing block, showing that this yielded Bayesian inference as the optimum information processing rule. Recently, Alemi (2019) reviewed Zellner's work in the context of machine learning and showed that the ICP could be seen as a special case of a more general optimum information processing criterion, namely the Predictive Information Bottleneck Objective. However, Alemi modeled the model training step in machine learning as using training and test data sets only, and did not account for the use of a validation data set during training. The present note is an attempt to extend Alemi's information processing formulation of machine learning, and the predictive information bottleneck objective for model training, to the widely-used scenario where training utilizes not only a training but also a validation data set.
PPD: Permutation Phase Defense Against Adversarial Examples in Deep Learning
Dec 25, 2018
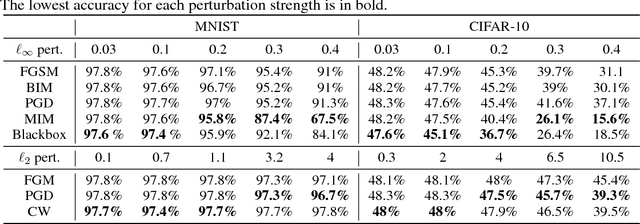

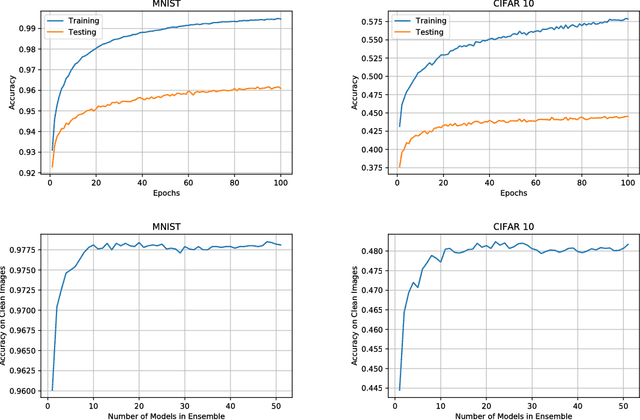
Deep neural networks have demonstrated cutting edge performance on various tasks including classification. However, it is well known that adversarially designed imperceptible perturbation of the input can mislead advanced classifiers. In this paper, Permutation Phase Defense (PPD), is proposed as a novel method to resist adversarial attacks. PPD combines random permutation of the image with phase component of its Fourier transform. The basic idea behind this approach is to turn adversarial defense problems analogously into symmetric cryptography, which relies solely on safekeeping of the keys for security. In PPD, safe keeping of the selected permutation ensures effectiveness against adversarial attacks. Testing PPD on MNIST and CIFAR-10 datasets yielded state-of-the-art robustness against the most powerful adversarial attacks currently available.