 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Information Bottleneck Objectives and their Applications to Machine Learning
Paper and Code
Dec 20, 2019

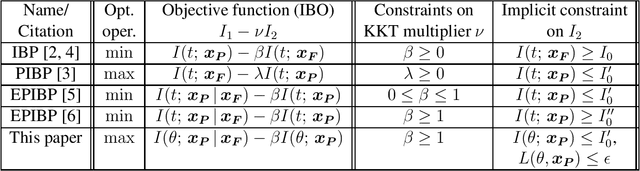
We view the Information Bottleneck Principle (IBP: Tishby et al., 1999; Schwartz-Ziv and Tishby, 2017) and Predictive Information Bottleneck Principle (PIBP: Still et al., 2007; Alemi, 2019) as special cases of a family of general information bottleneck objectives (IBOs). Each IBO corresponds to a particular constrained optimization problem where the constraints apply to: (a) the mutual information between the training data and the learned model parameters or extracted representation of the data, and (b) the mutual information between the learned model parameters or extracted representation of the data and the test data (if any). The heuristics behind the IBP and PIBP are shown to yield different constraints in the corresponding constrained optimization problem formulations. We show how other heuristics lead to a new IBO, different from both the IBP and PIBP, and use the techniques from (Alemi, 2019) to derive and optimize a variational upper bound on the new IBO. We then apply the theory of general IBOs to resolve the seeming contradiction between, on the one hand, the recommendations of IBP and PIBP to maximize the mutual information between the model parameters and test data, and on the other, recent information-theoretic results (see Xu and Raginsky, 2017) suggesting that this mutual information should be minimized. The key insight is that the heuristics (and thus the constraints in the constrained optimization problems) of IBP and PIBP are not applicable to the scenario analyzed by (Xu and Raginsky, 2017) because the latter makes the additional assumption that the parameters of the trained model have been selected to minimize the empirical loss function. Aided by this insight, we formulate a new IBO that accounts for this property of the parameters of the trained model, and derive and optimize a variational bound on this IBO.