 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive Safe: Cognitive-Behavioral Mining for Intelligent Transportation Cyber-Physical System
Aug 24, 2020
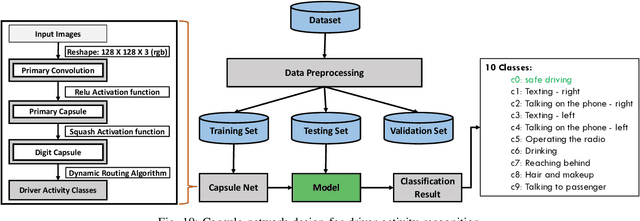
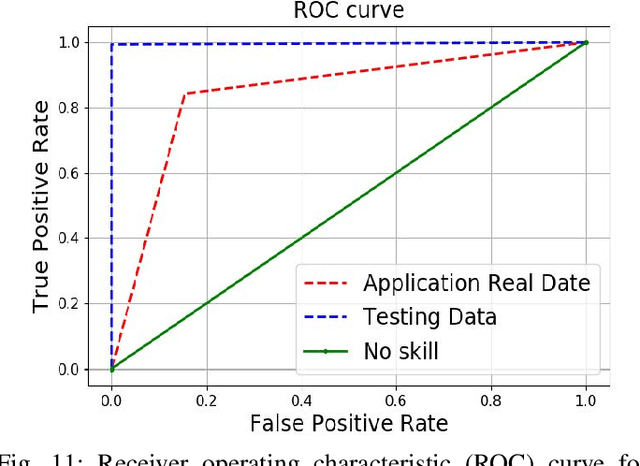
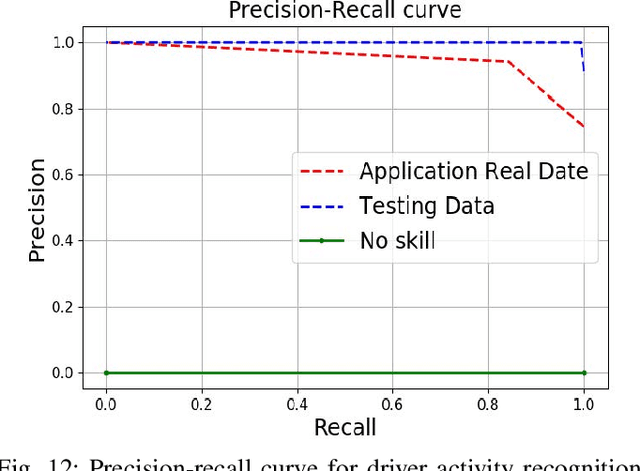
This paper presents a cognitive behavioral-based driver mood repairment platform in intelligent transportation cyber-physical systems (IT-CPS) for road safety. In particular, we propose a driving safety platform for distracted drivers, namely \emph{drive safe}, in IT-CPS. The proposed platform recognizes the distracting activities of the drivers as well as their emotions for mood repair. Further, we develop a prototype of the proposed drive safe platform to establish proof-of-concept (PoC) for the road safety in IT-CPS. In the developed driving safety platform, we employ five AI and statistical-based models to infer a vehicle driver's cognitive-behavioral mining to ensure safe driving during the drive. Especially, capsule network (CN), maximum likelihood (ML), convolutional neural network (CNN), Apriori algorithm, and Bayesian network (BN) are deployed for driver activity recognition, environmental feature extraction, mood recognition, sequential pattern mining, and content recommendation for affective mood repairment of the driver, respectively. Besides, we develop a communication module to interact with the systems in IT-CPS asynchronously. Thus, the developed drive safe PoC can guide the vehicle drivers when they are distracted from driving due to the cognitive-behavioral factors. Finally, we have performed a qualitative evaluation to measure the usability and effectiveness of the developed drive safe platform. We observe that the P-value is 0.0041 (i.e., < 0.05) in the ANOVA test. Moreover, the confidence interval analysis also shows significant gains in prevalence value which is around 0.93 for a 95% confidence level. The aforementioned statistical results indicate high reliability in terms of driver's safety and mental state.
Data Freshness and Energy-Efficient UAV Navigation Optimization: A Deep Reinforcement Learning Approach
Feb 21, 2020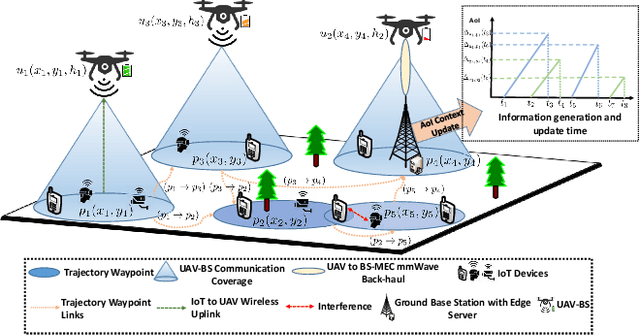
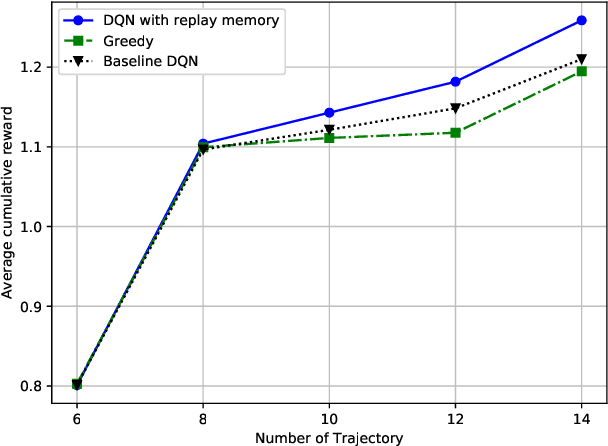
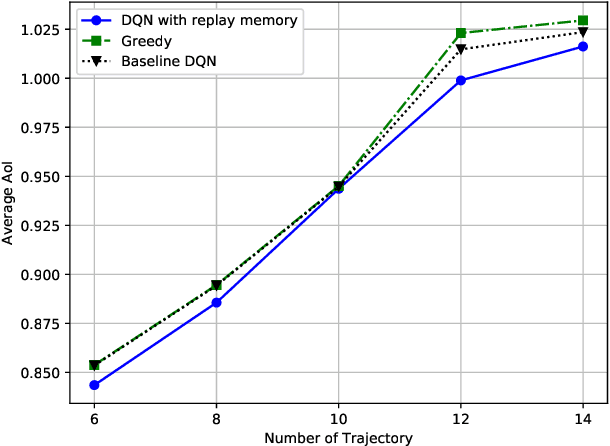
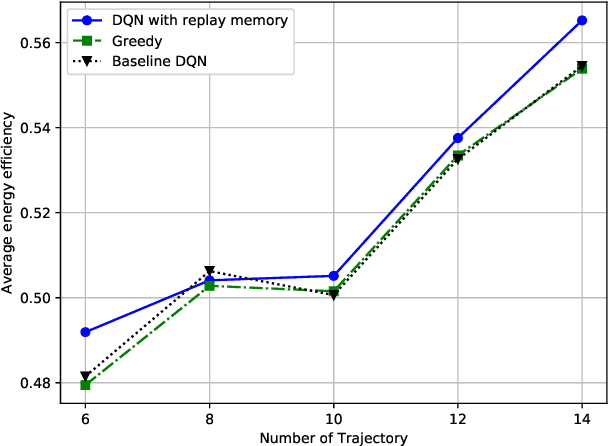
In this paper, we design a navigation policy for multiple unmanned aerial vehicles (UAVs) where mobile base stations (BSs) are deployed to improve the data freshness and connectivity to the Internet of Things (IoT) devices. First, we formulate an energy-efficient trajectory optimization problem in which the objective is to maximize the energy efficiency by optimizing the UAV-BS trajectory policy. We also incorporate different contextual information such as energy and age of information (AoI) constraints to ensure the data freshness at the ground BS. Second, we propose an agile deep reinforcement learning with experience replay model to solve the formulated problem concerning the contextual constraints for the UAV-BS navigation. Moreover, the proposed approach is well-suited for solving the problem, since the state space of the problem is extremely large and finding the best trajectory policy with useful contextual features is too complex for the UAV-BSs. By applying the proposed trained model, an effective real-time trajectory policy for the UAV-BSs captures the observable network states over time. Finally, the simulation results illustrate the proposed approach is 3.6% and 3.13% more energy efficient than those of the greedy and baseline deep Q Network (DQN) approaches.
Risk-Aware Energy Scheduling for Edge Computing with Microgrid: A Multi-Agent Deep Reinforcement Learning Approach
Feb 21, 2020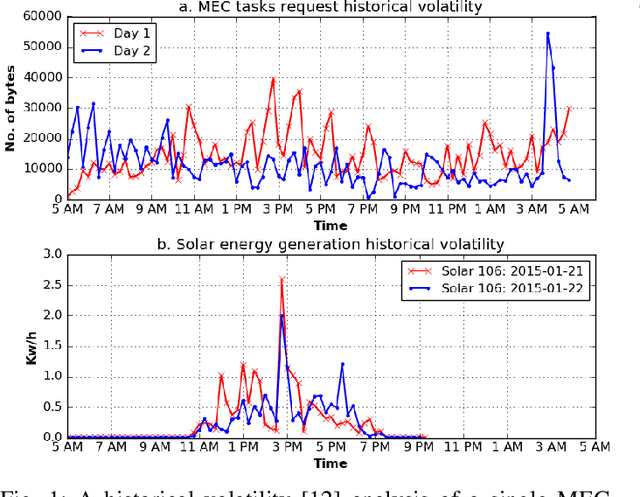
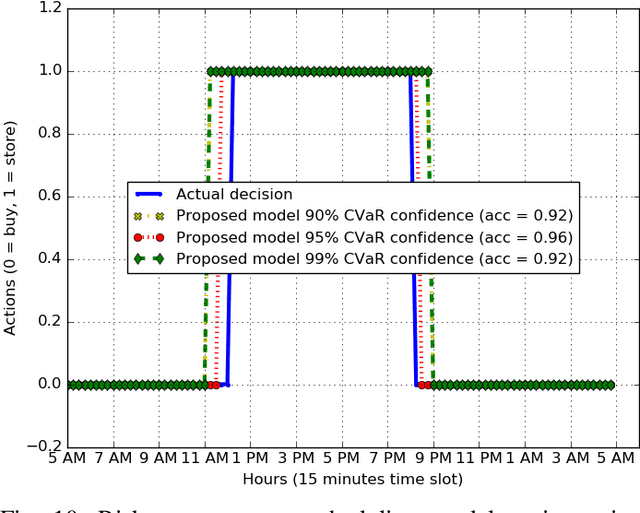
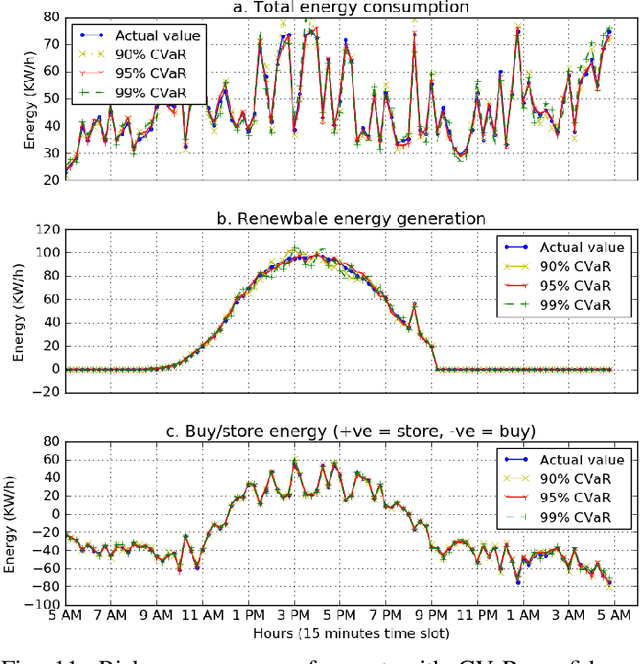
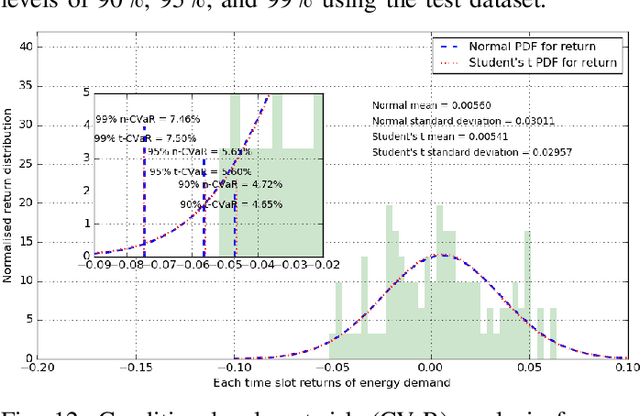
In recent years, multi-access edge computing (MEC) is a key enabler for handling the massive expansion of Internet of Things (IoT) applications and services. However, energy consumption of a MEC network depends on volatile tasks that induces risk for energy demand estimations. As an energy supplier, a microgrid can facilitate seamless energy supply. However, the risk associated with energy supply is also increased due to unpredictable energy generation from renewable and non-renewable sources. Especially, the risk of energy shortfall is involved with uncertainties in both energy consumption and generation. In this paper, we study a risk-aware energy scheduling problem for a microgrid-powered MEC network. First, we formulate an optimization problem considering the conditional value-at-risk (CVaR) measurement for both energy consumption and generation, where the objective is to minimize the loss of energy shortfall of the MEC networks and we show this problem is an NP-hard problem. Second, we analyze our formulated problem using a multi-agent stochastic game that ensures the joint policy Nash equilibrium, and show the convergence of the proposed model. Third, we derive the solution by applying a multi-agent deep reinforcement learning (MADRL)-based asynchronous advantage actor-critic (A3C) algorithm with shared neural networks. This method mitigates the curse of dimensionality of the state space and chooses the best policy among the agents for the proposed problem. Finally, the experimental results establish a significant performance gain by considering CVaR for high accuracy energy scheduling of the proposed model than both the single and random agent models.