 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection Tutorial with Python Examples
Jun 11, 2021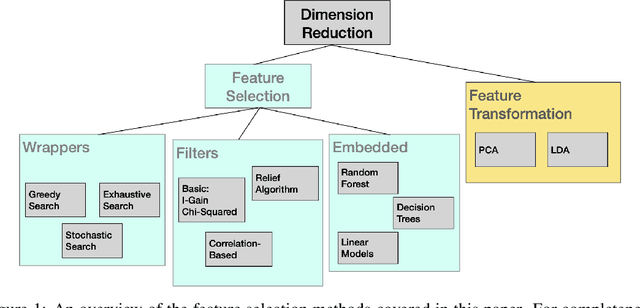
In Machine Learning, feature selection entails selecting a subset of the available features in a dataset to use for model development. There are many motivations for feature selection, it may result in better models, it may provide insight into the data and it may deliver economies in data gathering or data processing. For these reasons feature selection has received a lot of attention in data analytics research. In this paper we provide an overview of the main methods and present practical examples with Python implementations. While the main focus is on supervised feature selection techniques, we also cover some feature transformation methods.
Wider Vision: Enriching Convolutional Neural Networks via Alignment to External Knowledge Bases
Feb 22, 2021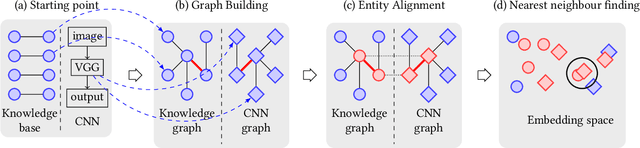
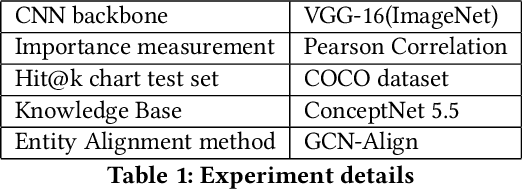
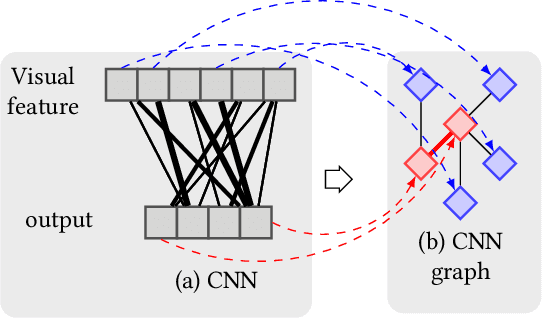
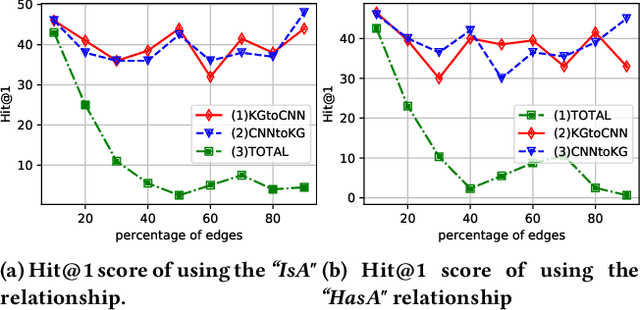
Deep learning models suffer from opaqueness. For Convolutional Neural Networks (CNNs), current research strategies for explaining models focus on the target classes within the associated training dataset. As a result, the understanding of hidden feature map activations is limited by the discriminative knowledge gleaned during training. The aim of our work is to explain and expand CNNs models via the mirroring or alignment of CNN to an external knowledge base. This will allow us to give a semantic context or label for each visual feature. We can match CNN feature activations to nodes in our external knowledge base. This supports knowledge-based interpretation of the features associated with model decisions. To demonstrate our approach, we build two separate graphs. We use an entity alignment method to align the feature nodes in a CNN with the nodes in a ConceptNet based knowledge graph. We then measure the proximity of CNN graph nodes to semantically meaningful knowledge base nodes. Our results show that in the aligned embedding space, nodes from the knowledge graph are close to the CNN feature nodes that have similar meanings, indicating that nodes from an external knowledge base can act as explanatory semantic references for features in the model. We analyse a variety of graph building methods in order to improve the results from our embedding space. We further demonstrate that by using hierarchical relationships from our external knowledge base, we can locate new unseen classes outside the CNN training set in our embeddings space, based on visual feature activations. This suggests that we can adapt our approach to identify unseen classes based on CNN feature activations. Our demonstrated approach of aligning a CNN with an external knowledge base paves the way to reason about and beyond the trained model, with future adaptations to explainable models and zero-shot learning.
Algorithmic Bias and Regularisation in Machine Learning
May 18, 2020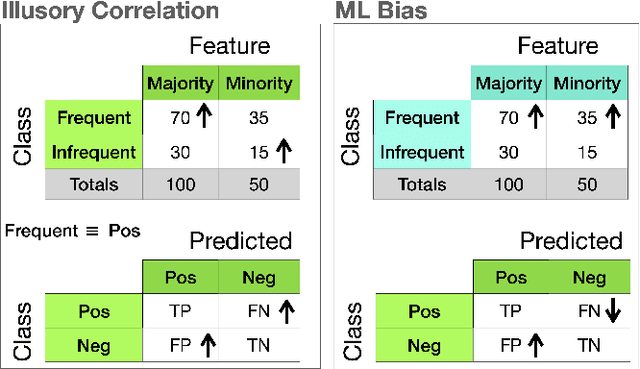
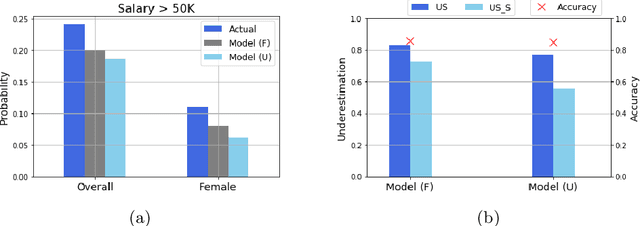
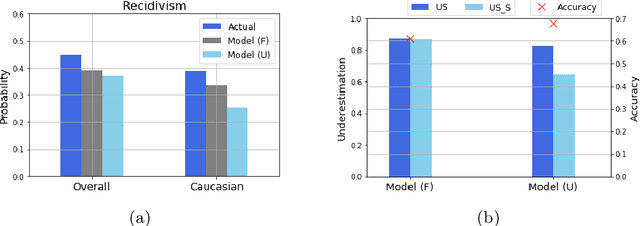
Often, what is termed algorithmic bias in machine learning will be due to historic bias in the training data. But sometimes the bias may be introduced (or at least exacerbated) by the algorithm itself. The ways in which algorithms can actually accentuate bias has not received a lot of attention with researchers focusing directly on methods to eliminate bias - no matter the source. In this paper we report on initial research to understand the factors that contribute to bias in classification algorithms. We believe this is important because underestimation bias is inextricably tied to regularization, i.e. measures to address overfitting can accentuate bias.
k-Nearest Neighbour Classifiers: 2nd Edition (with Python examples)
Apr 29, 2020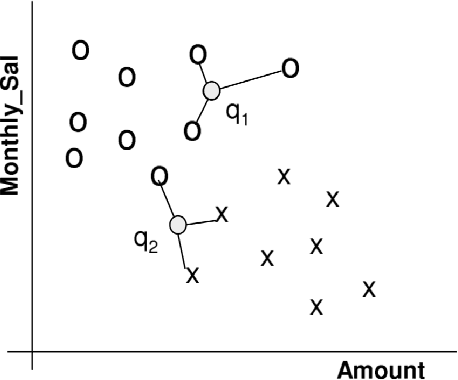
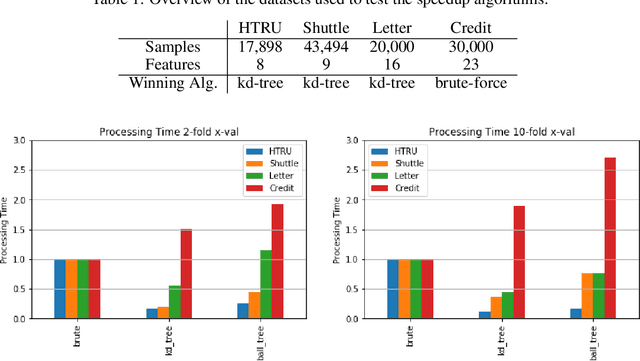
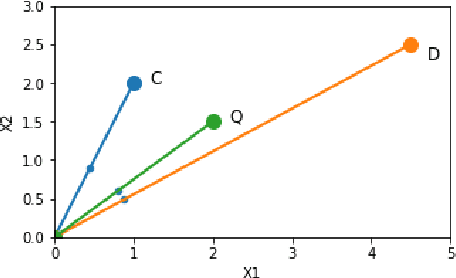
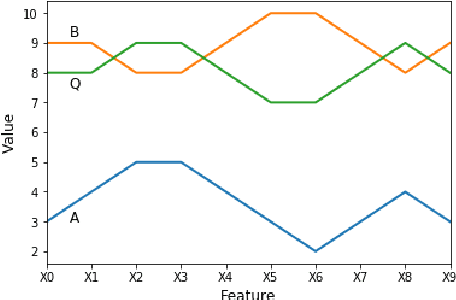
Perhaps the most straightforward classifier in the arsenal or machine learning techniques is the Nearest Neighbour Classifier -- classification is achieved by identifying the nearest neighbours to a query example and using those neighbours to determine the class of the query. This approach to classification is of particular importance because issues of poor run-time performance is not such a problem these days with the computational power that is available. This paper presents an overview of techniques for Nearest Neighbour classification focusing on; mechanisms for assessing similarity (distance), computational issues in identifying nearest neighbours and mechanisms for reducing the dimension of the data. This paper is the second edition of a paper previously published as a technical report. Sections on similarity measures for time-series, retrieval speed-up and intrinsic dimensionality have been added. An Appendix is included providing access to Python code for the key methods.