Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic Bias and Regularisation in Machine Learning
Paper and Code
May 18, 2020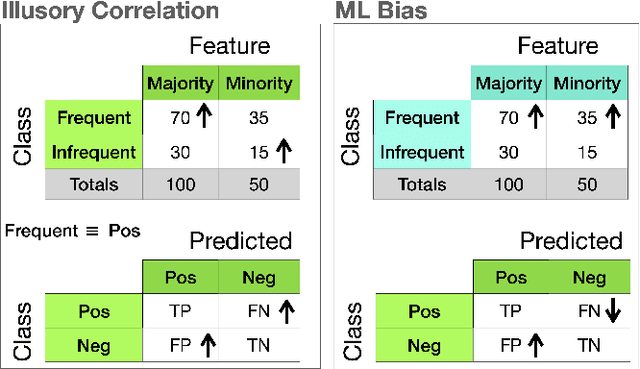
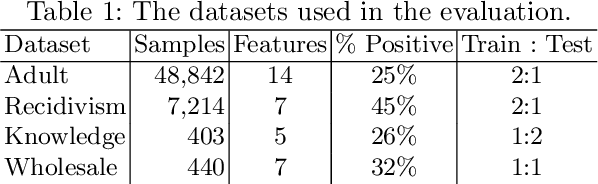
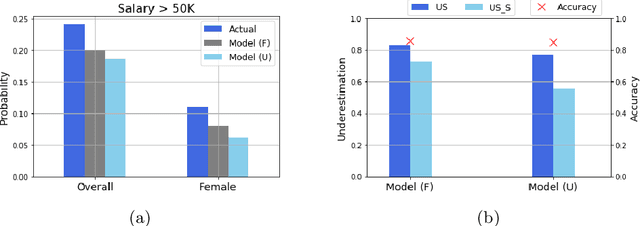
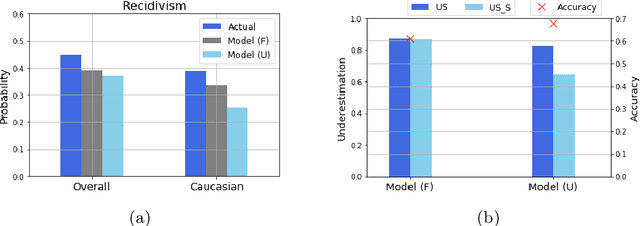
Often, what is termed algorithmic bias in machine learning will be due to historic bias in the training data. But sometimes the bias may be introduced (or at least exacerbated) by the algorithm itself. The ways in which algorithms can actually accentuate bias has not received a lot of attention with researchers focusing directly on methods to eliminate bias - no matter the source. In this paper we report on initial research to understand the factors that contribute to bias in classification algorithms. We believe this is important because underestimation bias is inextricably tied to regularization, i.e. measures to address overfitting can accentuate bias.
* 10 pages, 5 figures, 3 tables
View paper on