 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating ROCKET and Catch22 features for calf behaviour classification from accelerometer data using Machine Learning models
Apr 30, 2024



Monitoring calf behaviour continuously would be beneficial to identify routine practices (e.g., weaning, dehorning, etc.) that impact calf welfare in dairy farms. In that regard, accelerometer data collected from neck collars can be used along with Machine Learning models to classify calf behaviour automatically. Hand-crafted features are commonly used in Machine Learning models, while ROCKET and Catch22 features are specifically designed for time-series classification problems in related fields. This study aims to compare the performance of ROCKET and Catch22 features to Hand-Crafted features. 30 Irish Holstein Friesian and Jersey pre-weaned calves were monitored using accelerometer sensors allowing for 27.4 hours of annotated behaviors. Additional time-series were computed from the raw X, Y and Z-axis and split into 3-second time windows. ROCKET, Catch22 and Hand-Crafted features were calculated for each time window, and the dataset was then split into the train, validation and test sets. Each set of features was used to train three Machine Learning models (Random Forest, eXtreme Gradient Boosting, and RidgeClassifierCV) to classify six behaviours indicative of pre-weaned calf welfare (drinking milk, grooming, lying, running, walking and other). Models were tuned with the validation set, and the performance of each feature-model combination was evaluated with the test set. The best performance across the three models was obtained with ROCKET [average balanced accuracy +/- standard deviation] (0.70 +/- 0.07), followed by Catch22 (0.69 +/- 0.05), surpassing Hand-Crafted (0.65 +/- 0.034). The best balanced accuracy (0.77) was obtained with ROCKET and RidgeClassifierCV, followed by Catch22 and Random Forest (0.73). Thus, tailoring these approaches for specific behaviours and contexts will be crucial in advancing precision livestock farming and enhancing animal welfare on a larger scale.
Correlation Based Feature Subset Selection for Multivariate Time-Series Data
Nov 26, 2021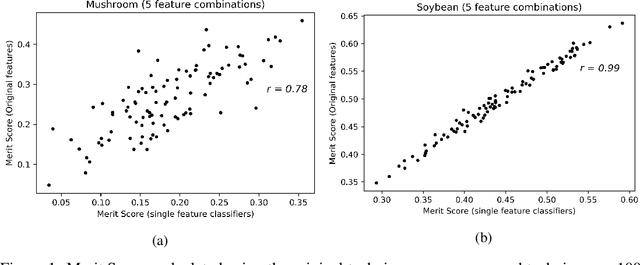
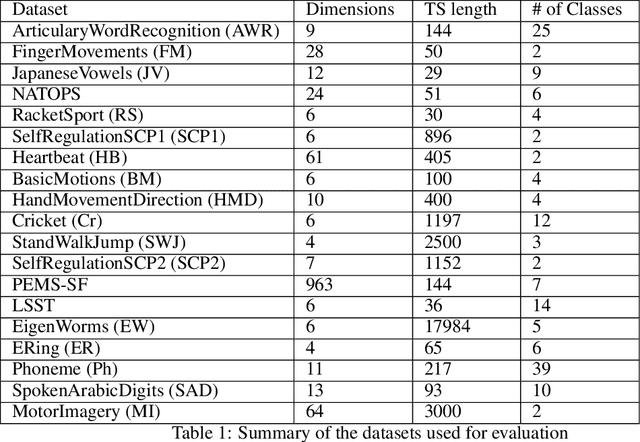
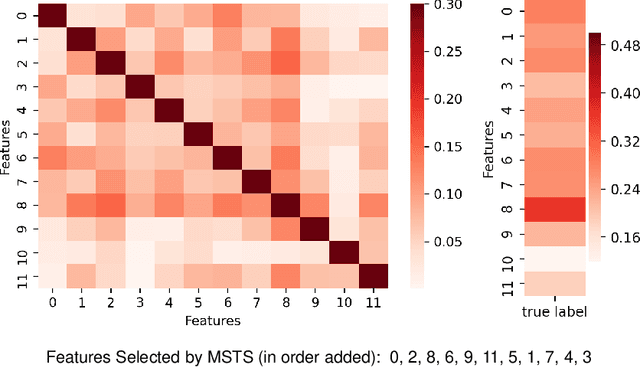
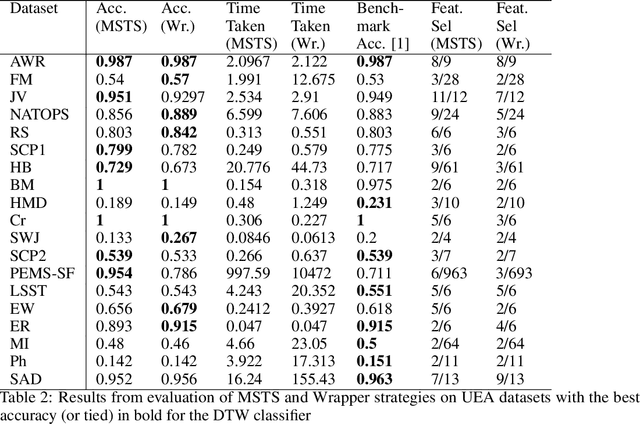
Correlations in streams of multivariate time series data means that typically, only a small subset of the features are required for a given data mining task. In this paper, we propose a technique which we call Merit Score for Time-Series data (MSTS) that does feature subset selection based on the correlation patterns of single feature classifier outputs. We assign a Merit Score to the feature subsets which is used as the basis for selecting 'good' feature subsets. The proposed technique is evaluated on datasets from the UEA multivariate time series archive and is compared against a Wrapper approach for feature subset selection. MSTS is shown to be effective for feature subset selection and is in particular effective as a data reduction technique. MSTS is shown here to be computationally more efficient than the Wrapper strategy in selecting a suitable feature subset, being more than 100 times faster for some larger datasets while also maintaining a good classification accuracy.
Feature Selection Tutorial with Python Examples
Jun 11, 2021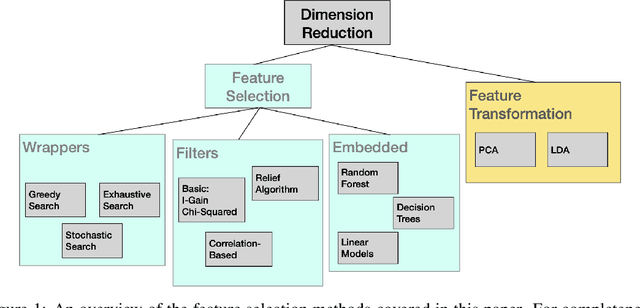
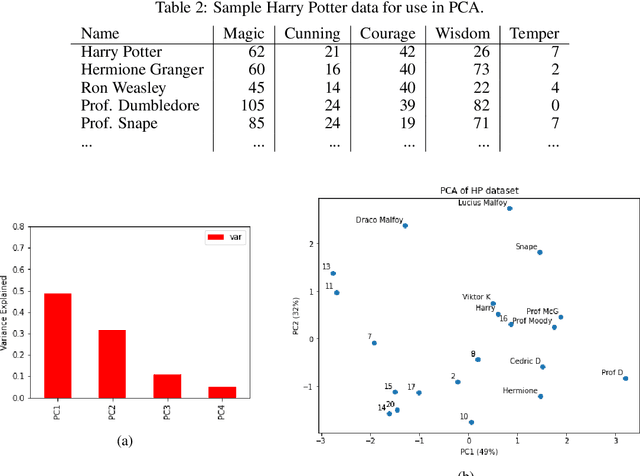
In Machine Learning, feature selection entails selecting a subset of the available features in a dataset to use for model development. There are many motivations for feature selection, it may result in better models, it may provide insight into the data and it may deliver economies in data gathering or data processing. For these reasons feature selection has received a lot of attention in data analytics research. In this paper we provide an overview of the main methods and present practical examples with Python implementations. While the main focus is on supervised feature selection techniques, we also cover some feature transformation methods.
A Feature Selection Method for Multi-Dimension Time-Series Data
Apr 22, 2021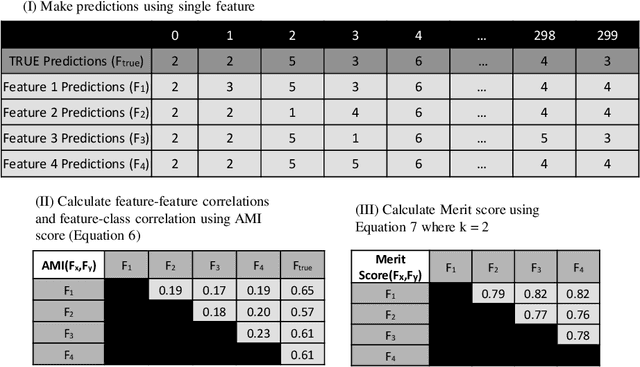
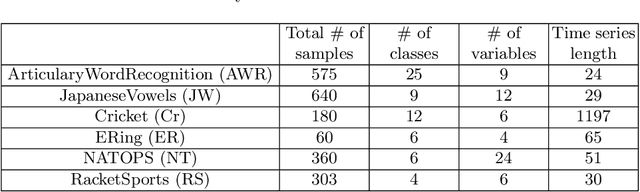
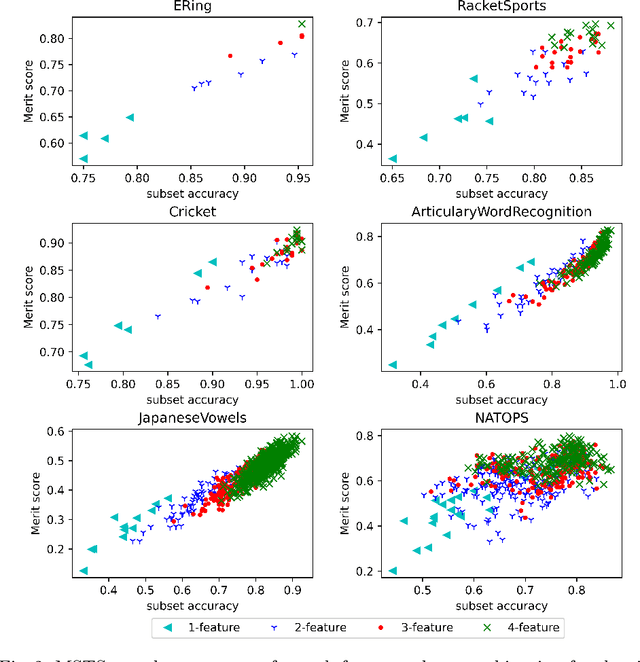
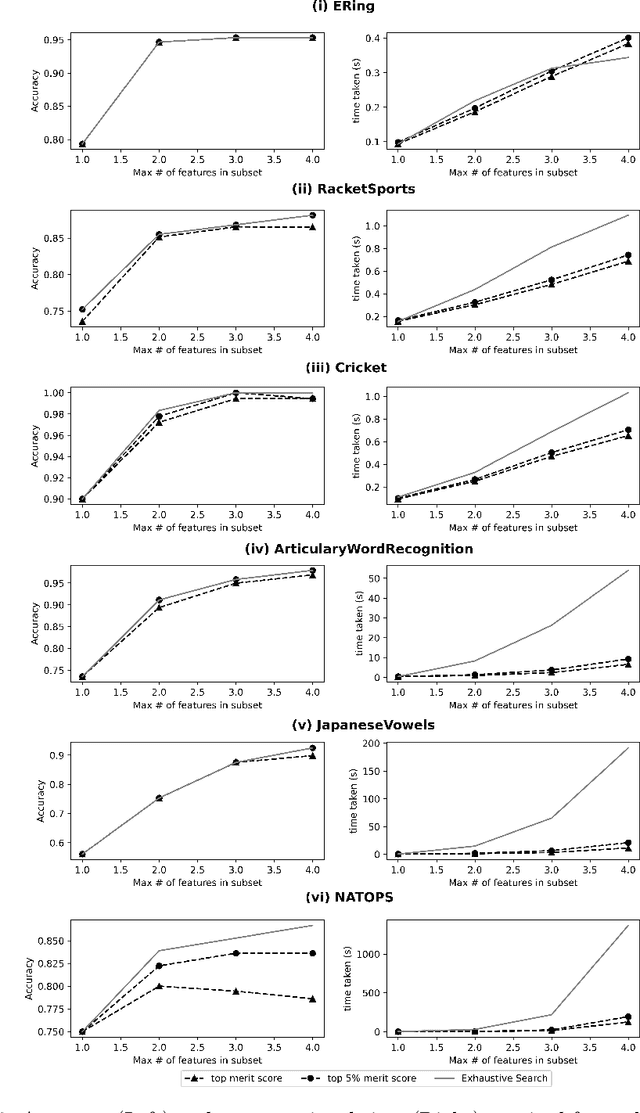
Time-series data in application areas such as motion capture and activity recognition is often multi-dimension. In these application areas data typically comes from wearable sensors or is extracted from video. There is a lot of redundancy in these data streams and good classification accuracy will often be achievable with a small number of features (dimensions). In this paper we present a method for feature subset selection on multidimensional time-series data based on mutual information. This method calculates a merit score (MSTS) based on correlation patterns of the outputs of classifiers trained on single features and the `best' subset is selected accordingly. MSTS was found to be significantly more efficient in terms of computational cost while also managing to maintain a good overall accuracy when compared to Wrapper-based feature selection, a feature selection strategy that is popular elsewhere in Machine Learning. We describe the motivations behind this feature selection strategy and evaluate its effectiveness on six time series datasets.
* 12 pages, 3 figures
An Evaluation of Classification Methods for 3D Printing Time-Series Data
Oct 02, 2020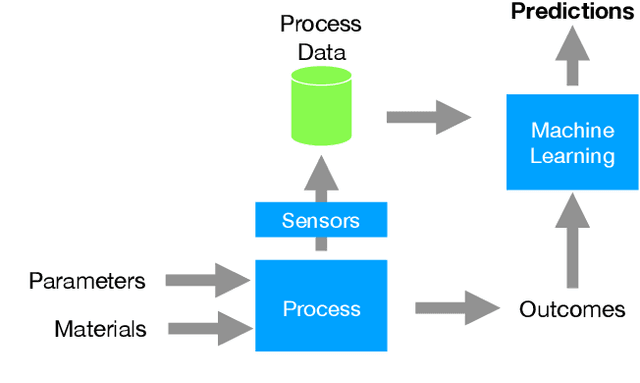
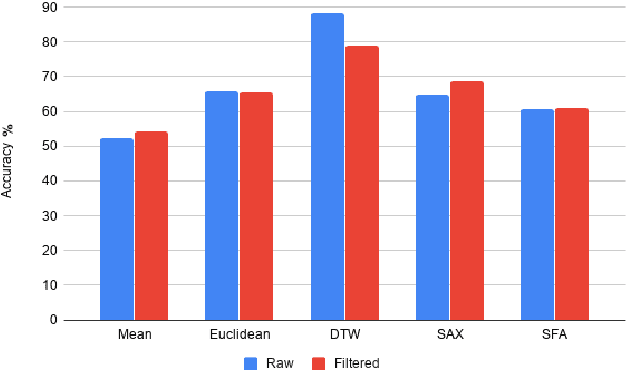
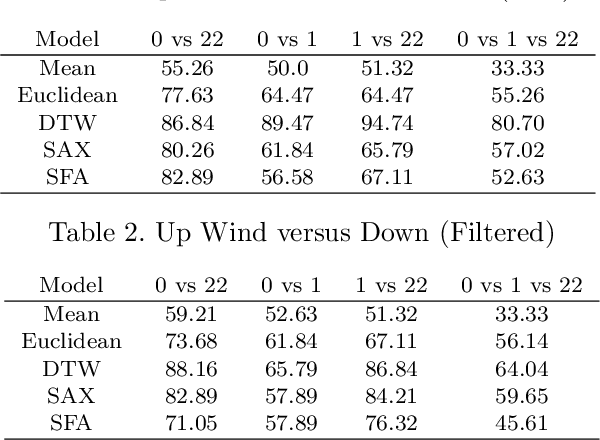
Additive Manufacturing presents a great application area for Machine Learning because of the vast volume of data generated and the potential to mine this data to control outcomes. In this paper we present preliminary work on classifying infrared time-series data representing melt-pool temperature in a metal 3D printing process. Our ultimate objective is to use this data to predict process outcomes (e.g. hardness, porosity, surface roughness). In the work presented here we simply show that there is a signal in this data that can be used for the classification of different components and stages of the AM process. In line with other Machine Learning research on time-series classification we use k-Nearest Neighbour classifiers. The results we present suggests that Dynamic Time Warping is an effective distance measure compared with alternatives for 3D printing data of this type.
Algorithmic Bias and Regularisation in Machine Learning
May 18, 2020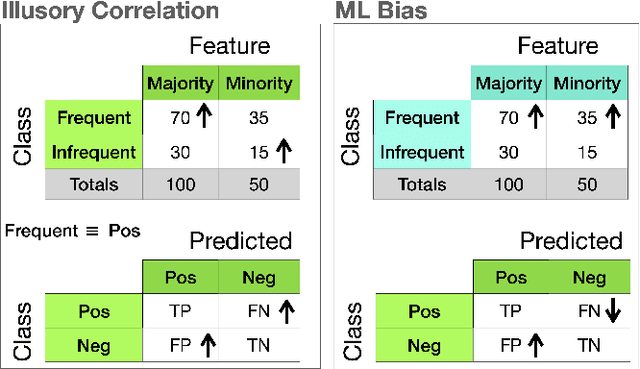
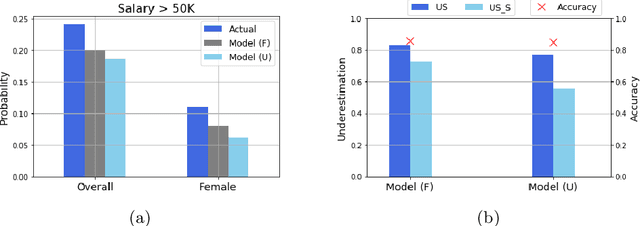
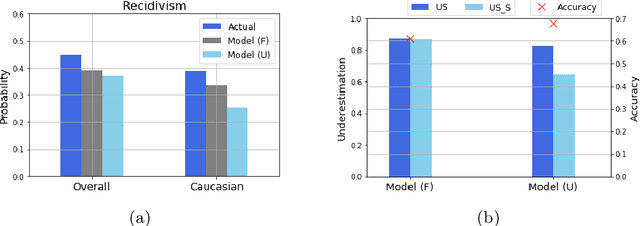
Often, what is termed algorithmic bias in machine learning will be due to historic bias in the training data. But sometimes the bias may be introduced (or at least exacerbated) by the algorithm itself. The ways in which algorithms can actually accentuate bias has not received a lot of attention with researchers focusing directly on methods to eliminate bias - no matter the source. In this paper we report on initial research to understand the factors that contribute to bias in classification algorithms. We believe this is important because underestimation bias is inextricably tied to regularization, i.e. measures to address overfitting can accentuate bias.
k-Nearest Neighbour Classifiers: 2nd Edition (with Python examples)
Apr 29, 2020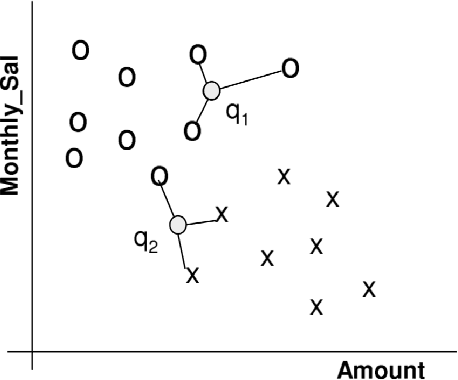
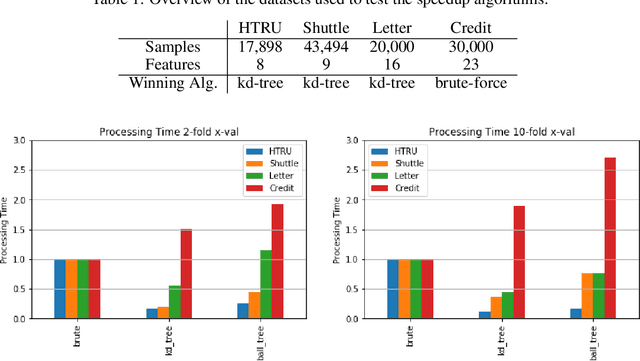
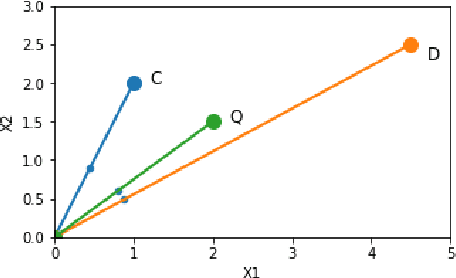
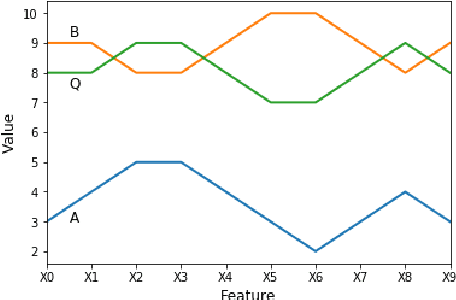
Perhaps the most straightforward classifier in the arsenal or machine learning techniques is the Nearest Neighbour Classifier -- classification is achieved by identifying the nearest neighbours to a query example and using those neighbours to determine the class of the query. This approach to classification is of particular importance because issues of poor run-time performance is not such a problem these days with the computational power that is available. This paper presents an overview of techniques for Nearest Neighbour classification focusing on; mechanisms for assessing similarity (distance), computational issues in identifying nearest neighbours and mechanisms for reducing the dimension of the data. This paper is the second edition of a paper previously published as a technical report. Sections on similarity measures for time-series, retrieval speed-up and intrinsic dimensionality have been added. An Appendix is included providing access to Python code for the key methods.