 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation Based Feature Subset Selection for Multivariate Time-Series Data
Nov 26, 2021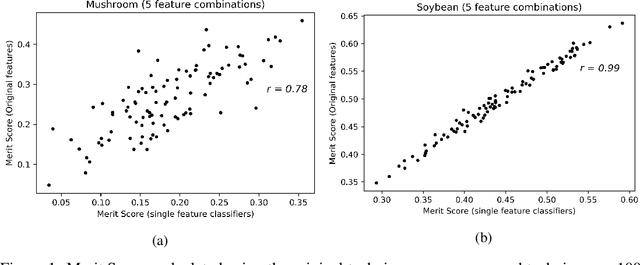
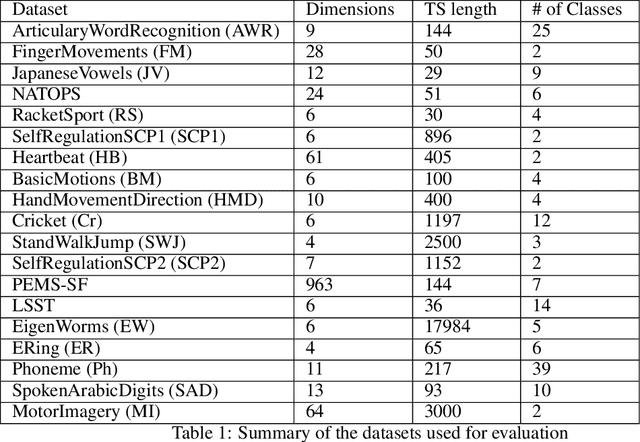
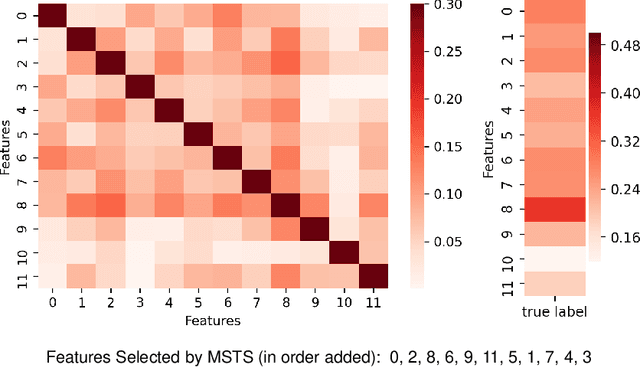
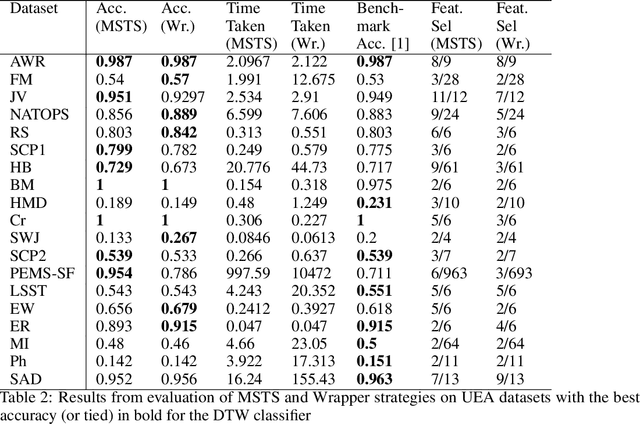
Correlations in streams of multivariate time series data means that typically, only a small subset of the features are required for a given data mining task. In this paper, we propose a technique which we call Merit Score for Time-Series data (MSTS) that does feature subset selection based on the correlation patterns of single feature classifier outputs. We assign a Merit Score to the feature subsets which is used as the basis for selecting 'good' feature subsets. The proposed technique is evaluated on datasets from the UEA multivariate time series archive and is compared against a Wrapper approach for feature subset selection. MSTS is shown to be effective for feature subset selection and is in particular effective as a data reduction technique. MSTS is shown here to be computationally more efficient than the Wrapper strategy in selecting a suitable feature subset, being more than 100 times faster for some larger datasets while also maintaining a good classification accuracy.
Feature Selection Tutorial with Python Examples
Jun 11, 2021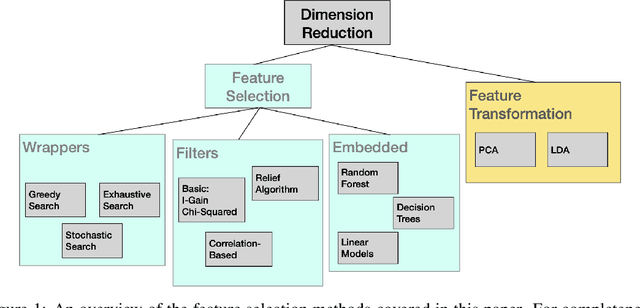
In Machine Learning, feature selection entails selecting a subset of the available features in a dataset to use for model development. There are many motivations for feature selection, it may result in better models, it may provide insight into the data and it may deliver economies in data gathering or data processing. For these reasons feature selection has received a lot of attention in data analytics research. In this paper we provide an overview of the main methods and present practical examples with Python implementations. While the main focus is on supervised feature selection techniques, we also cover some feature transformation methods.
A Feature Selection Method for Multi-Dimension Time-Series Data
Apr 22, 2021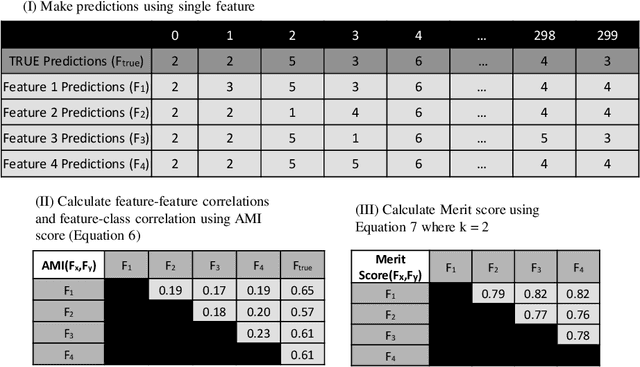
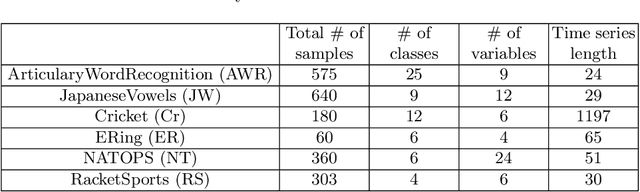
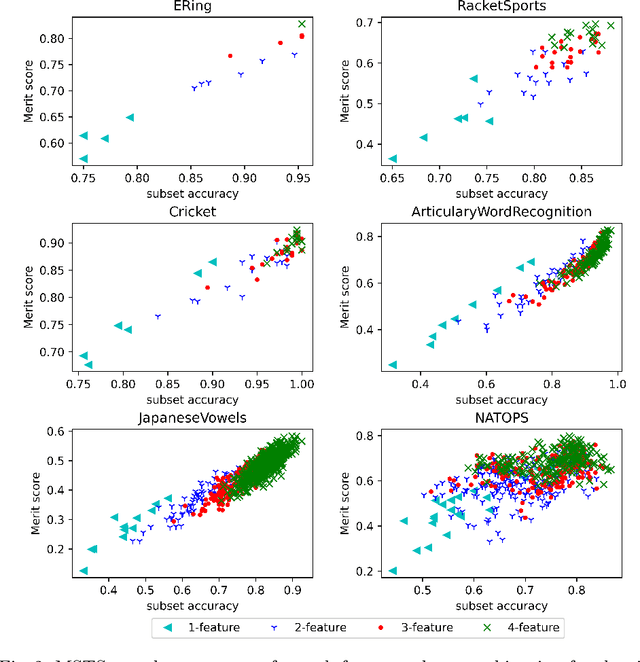
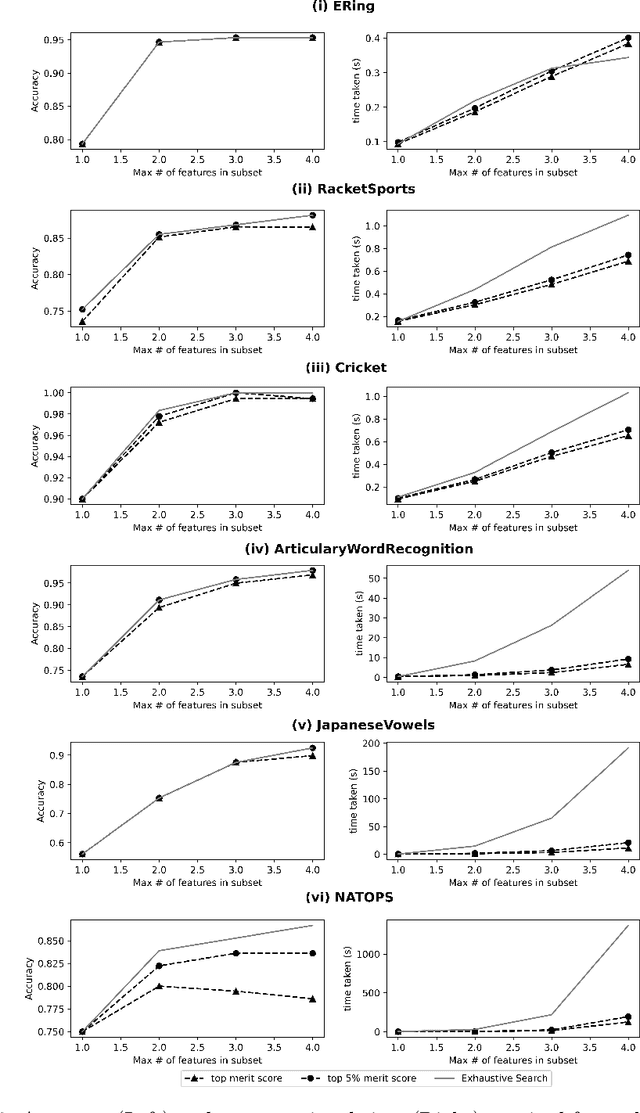
Time-series data in application areas such as motion capture and activity recognition is often multi-dimension. In these application areas data typically comes from wearable sensors or is extracted from video. There is a lot of redundancy in these data streams and good classification accuracy will often be achievable with a small number of features (dimensions). In this paper we present a method for feature subset selection on multidimensional time-series data based on mutual information. This method calculates a merit score (MSTS) based on correlation patterns of the outputs of classifiers trained on single features and the `best' subset is selected accordingly. MSTS was found to be significantly more efficient in terms of computational cost while also managing to maintain a good overall accuracy when compared to Wrapper-based feature selection, a feature selection strategy that is popular elsewhere in Machine Learning. We describe the motivations behind this feature selection strategy and evaluate its effectiveness on six time series datasets.
* 12 pages, 3 figures