 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation Based Feature Subset Selection for Multivariate Time-Series Data
Paper and Code
Nov 26, 2021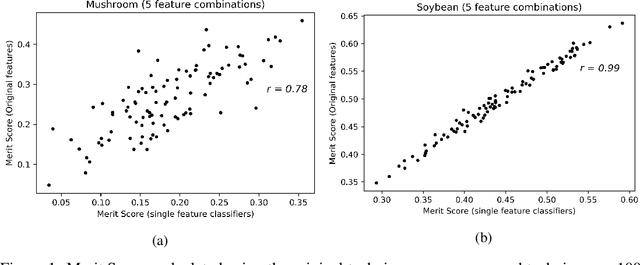
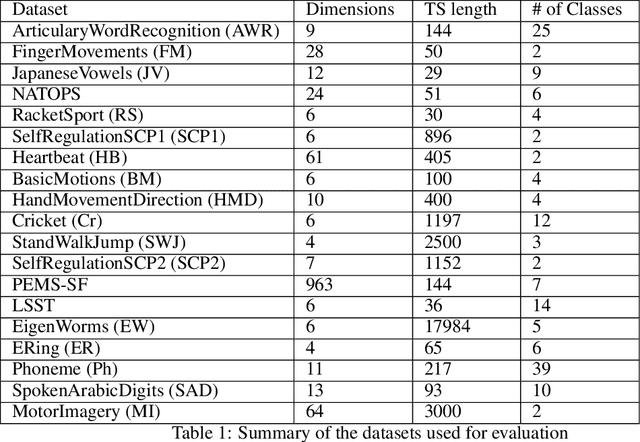
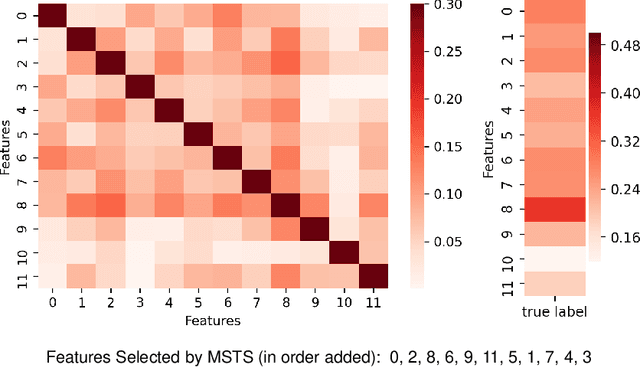
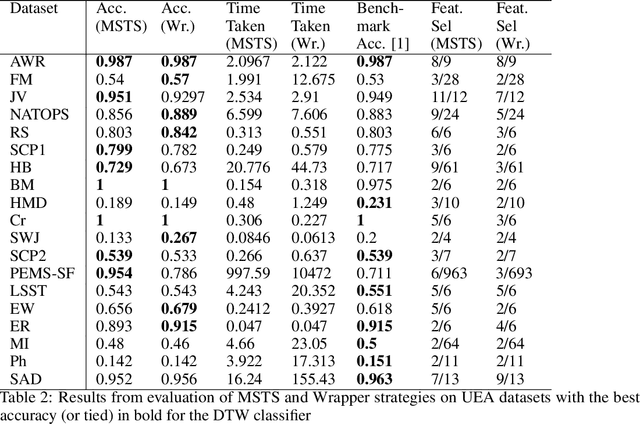
Correlations in streams of multivariate time series data means that typically, only a small subset of the features are required for a given data mining task. In this paper, we propose a technique which we call Merit Score for Time-Series data (MSTS) that does feature subset selection based on the correlation patterns of single feature classifier outputs. We assign a Merit Score to the feature subsets which is used as the basis for selecting 'good' feature subsets. The proposed technique is evaluated on datasets from the UEA multivariate time series archive and is compared against a Wrapper approach for feature subset selection. MSTS is shown to be effective for feature subset selection and is in particular effective as a data reduction technique. MSTS is shown here to be computationally more efficient than the Wrapper strategy in selecting a suitable feature subset, being more than 100 times faster for some larger datasets while also maintaining a good classification accuracy.