 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Microprocessor Performance Bug Detection
Nov 19, 2020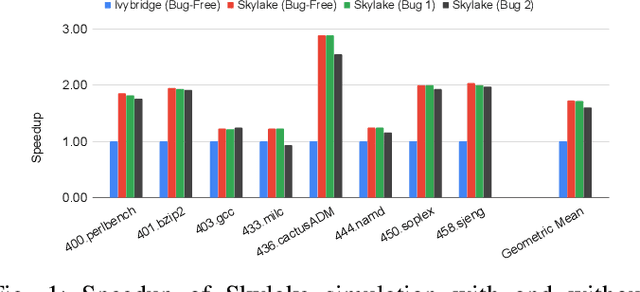
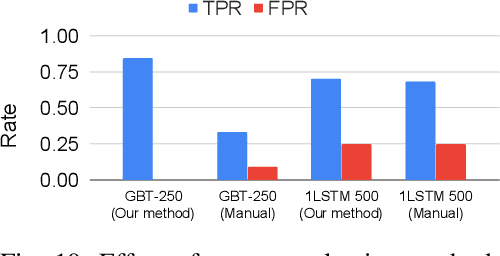
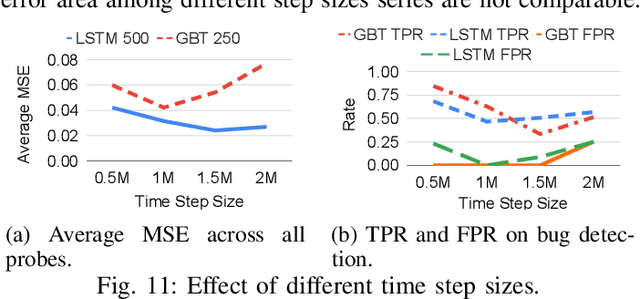
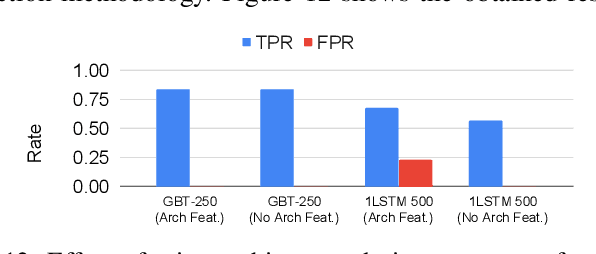
Processor design validation and debug is a difficult and complex task, which consumes the lion's share of the design process. Design bugs that affect processor performance rather than its functionality are especially difficult to catch, particularly in new microarchitectures. This is because, unlike functional bugs, the correct processor performance of new microarchitectures on complex, long-running benchmarks is typically not deterministically known. Thus, when performance benchmarking new microarchitectures, performance teams may assume that the design is correct when the performance of the new microarchitecture exceeds that of the previous generation, despite significant performance regressions existing in the design. In this work, we present a two-stage, machine learning-based methodology that is able to detect the existence of performance bugs in microprocessors. Our results show that our best technique detects 91.5% of microprocessor core performance bugs whose average IPC impact across the studied applications is greater than 1% versus a bug-free design with zero false positives. When evaluated on memory system bugs, our technique achieves 100% detection with zero false positives. Moreover, the detection is automatic, requiring very little performance engineer time.
Multi-view constrained clustering with an incomplete mapping between views
Oct 09, 2012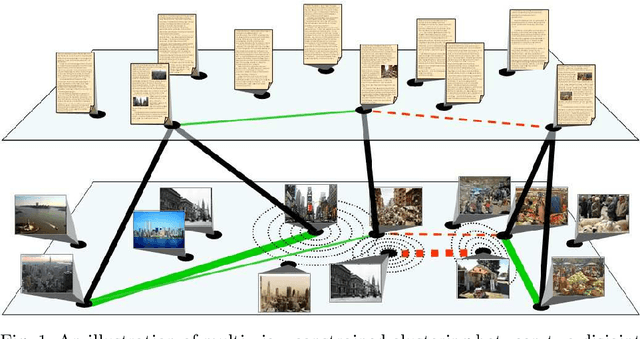
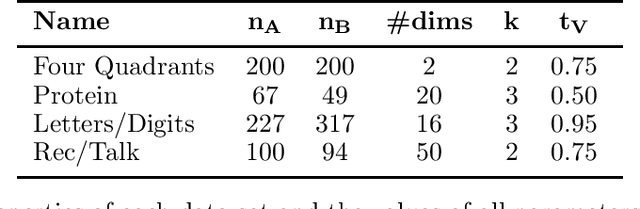
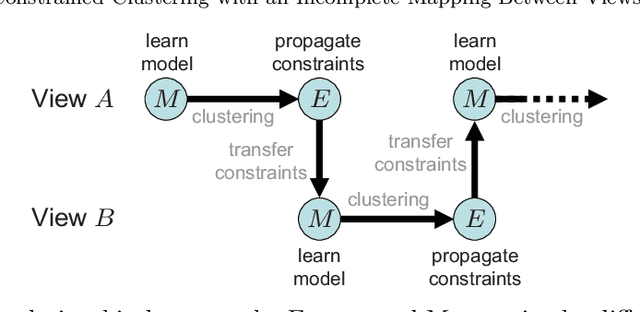

Multi-view learning algorithms typically assume a complete bipartite mapping between the different views in order to exchange information during the learning process. However, many applications provide only a partial mapping between the views, creating a challenge for current methods. To address this problem, we propose a multi-view algorithm based on constrained clustering that can operate with an incomplete mapping. Given a set of pairwise constraints in each view, our approach propagates these constraints using a local similarity measure to those instances that can be mapped to the other views, allowing the propagated constraints to be transferred across views via the partial mapping. It uses co-EM to iteratively estimate the propagation within each view based on the current clustering model, transfer the constraints across views, and then update the clustering model. By alternating the learning process between views, this approach produces a unified clustering model that is consistent with all views. We show that this approach significantly improves clustering performance over several other methods for transferring constraints and allows multi-view clustering to be reliably applied when given a limited mapping between the views. Our evaluation reveals that the propagated constraints have high precision with respect to the true clusters in the data, explaining their benefit to clustering performance in both single- and multi-view learning scenarios.