 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Relationship Reasoning using Gated Spatio-Temporal Energy Graph
Mar 27, 2019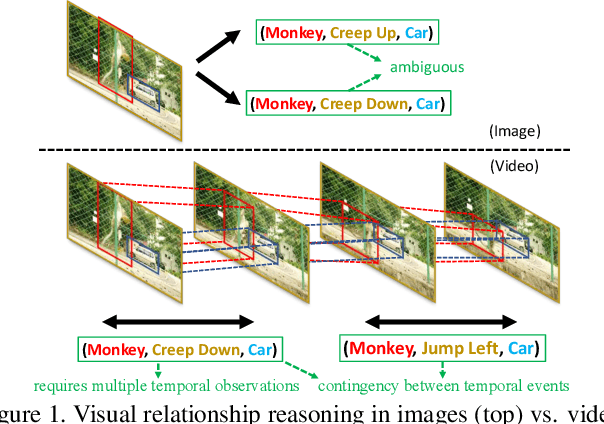
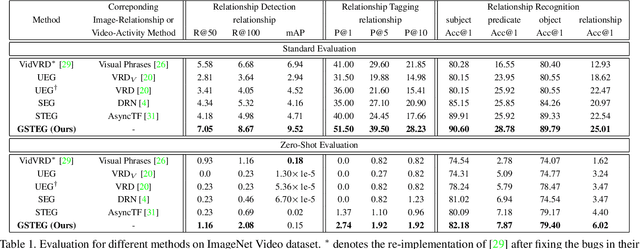
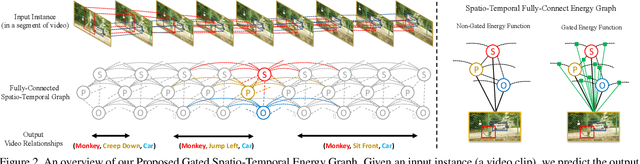
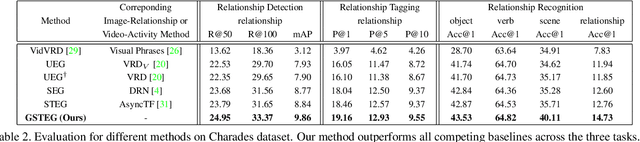
Visual relationship reasoning is a crucial yet challenging task for understanding rich interactions across visual concepts. For example, a relationship 'man, open, door' involves a complex relation 'open' between concrete entities 'man, door'. While much of the existing work has studied this problem in the context of still images, understanding visual relationships in videos has received limited attention. Due to their temporal nature, videos enable us to model and reason about a more comprehensive set of visual relationships, such as those requiring multiple (temporal) observations (e.g., 'man, lift up, box' vs. 'man, put down, box'), as well as relationships that are often correlated through time (e.g., 'woman, pay, money' followed by 'woman, buy, coffee'). In this paper, we construct a Conditional Random Field on a fully-connected spatio-temporal graph that exploits the statistical dependency between relational entities spatially and temporally. We introduce a novel gated energy function parametrization that learns adaptive relations conditioned on visual observations. Our model optimization is computationally efficient, and its space computation complexity is significantly amortized through our proposed parameterization. Experimental results on benchmark video datasets (ImageNet Video and Charades) demonstrate state-of-the-art performance across three standard relationship reasoning tasks: Detection, Tagging, and Recognition.
DOCK: Detecting Objects by transferring Common-sense Knowledge
Jul 31, 2018
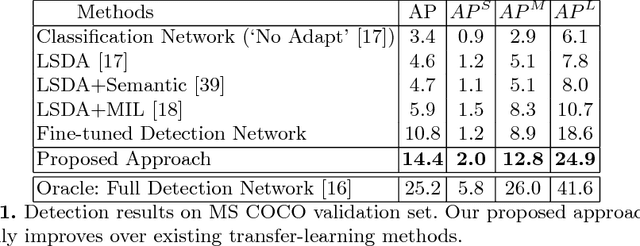


We present a scalable approach for Detecting Objects by transferring Common-sense Knowledge (DOCK) from source to target categories. In our setting, the training data for the source categories have bounding box annotations, while those for the target categories only have image-level annotations. Current state-of-the-art approaches focus on image-level visual or semantic similarity to adapt a detector trained on the source categories to the new target categories. In contrast, our key idea is to (i) use similarity not at the image-level, but rather at the region-level, and (ii) leverage richer common-sense (based on attribute, spatial, etc.) to guide the algorithm towards learning the correct detections. We acquire such common-sense cues automatically from readily-available knowledge bases without any extra human effort. On the challenging MS COCO dataset, we find that common-sense knowledge can substantially improve detection performance over existing transfer-learning baselines.
Asynchronous Temporal Fields for Action Recognition
Jul 24, 2017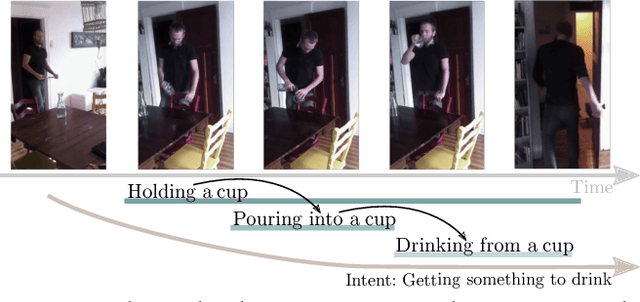

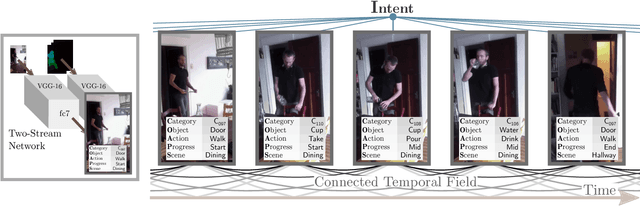
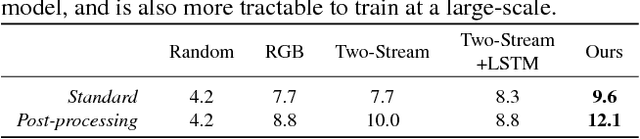
Actions are more than just movements and trajectories: we cook to eat and we hold a cup to drink from it. A thorough understanding of videos requires going beyond appearance modeling and necessitates reasoning about the sequence of activities, as well as the higher-level constructs such as intentions. But how do we model and reason about these? We propose a fully-connected temporal CRF model for reasoning over various aspects of activities that includes objects, actions, and intentions, where the potentials are predicted by a deep network. End-to-end training of such structured models is a challenging endeavor: For inference and learning we need to construct mini-batches consisting of whole videos, leading to mini-batches with only a few videos. This causes high-correlation between data points leading to breakdown of the backprop algorithm. To address this challenge, we present an asynchronous variational inference method that allows efficient end-to-end training. Our method achieves a classification mAP of 22.4% on the Charades benchmark, outperforming the state-of-the-art (17.2% mAP), and offers equal gains on the task of temporal localization.
You Only Look Once: Unified, Real-Time Object Detection
May 09, 2016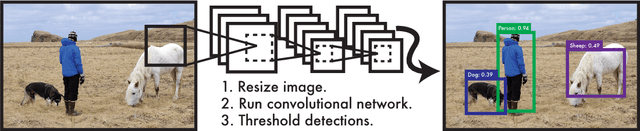
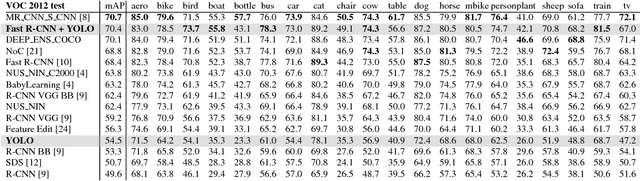
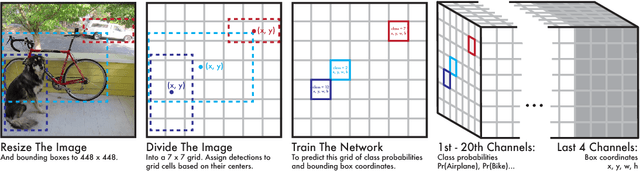
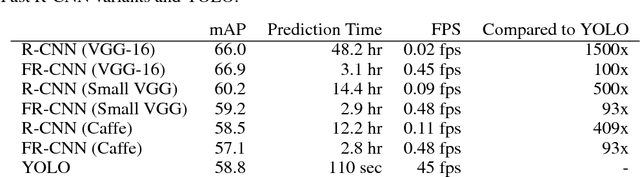
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is far less likely to predict false detections where nothing exists. Finally, YOLO learns very general representations of objects. It outperforms all other detection methods, including DPM and R-CNN, by a wide margin when generalizing from natural images to artwork on both the Picasso Dataset and the People-Art Dataset.