 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputation of Unknown Missingness in Sparse Electronic Health Records
Feb 24, 2026Machine learning holds great promise for advancing the field of medicine, with electronic health records (EHRs) serving as a primary data source. However, EHRs are often sparse and contain missing data due to various challenges and limitations in data collection and sharing between healthcare providers. Existing techniques for imputing missing values predominantly focus on known unknowns, such as missing or unavailable values of lab test results; most do not explicitly address situations where it is difficult to distinguish what is missing. For instance, a missing diagnosis code in an EHR could signify either that the patient has not been diagnosed with the condition or that a diagnosis was made, but not shared by a provider. Such situations fall into the paradigm of unknown unknowns. To address this challenge, we develop a general purpose algorithm for denoising data to recover unknown missing values in binary EHRs. We design a transformer-based denoising neural network where the output is thresholded adaptively to recover values in cases where we predict data are missing. Our results demonstrate improved accuracy in denoising medical codes within a real EHR dataset compared to existing imputation approaches and leads to increased performance on downstream tasks using the denoised data. In particular, when applying our method to a real world application, predicting hospital readmission from EHRs, our method achieves statistically significant improvement over all existing baselines.
Fast and Effective On-policy Distillation from Reasoning Prefixes
Feb 16, 2026On-policy distillation (OPD), which samples trajectories from the student model and supervises them with a teacher at the token level, avoids relying solely on verifiable terminal rewards and can yield better generalization than off-policy distillation. However, OPD requires expensive on-the-fly sampling of the student policy during training, which substantially increases training cost, especially for long responses. Our initial analysis shows that, during OPD, training signals are often concentrated in the prefix of each output, and that even a short teacher-generated prefix can significantly help the student produce the correct answer. Motivated by these observations, we propose a simple yet effective modification of OPD: we apply the distillation objective only to prefixes of student-generated outputs and terminate each sampling early during distillation. Experiments on a suite of AI-for-Math and out-of-domain benchmarks show that on-policy prefix distillation matches the performance of full OPD while reducing training FLOP by 2x-47x.
ESTAR: Early-Stopping Token-Aware Reasoning For Efficient Inference
Feb 10, 2026Large reasoning models (LRMs) achieve state-of-the-art performance by generating long chains-of-thought, but often waste computation on redundant reasoning after the correct answer has already been reached. We introduce Early-Stopping for Token-Aware Reasoning (ESTAR), which detects and reduces such reasoning redundancy to improve efficiency without sacrificing accuracy. Our method combines (i) a trajectory-based classifier that identifies when reasoning can be safely stopped, (ii) supervised fine-tuning to teach LRMs to propose self-generated <stop> signals, and (iii) <stop>-aware reinforcement learning that truncates rollouts at self-generated stop points with compute-aware rewards. Experiments on four reasoning datasets show that ESTAR reduces reasoning length by about 3.7x (from 4,799 to 1,290) while preserving accuracy (74.9% vs. 74.2%), with strong cross-domain generalization. These results highlight early stopping as a simple yet powerful mechanism for improving reasoning efficiency in LRMs.
POET: Protocol Optimization via Eligibility Tuning
Jan 30, 2026Eligibility criteria (EC) are essential for clinical trial design, yet drafting them remains a time-intensive and cognitively demanding task for clinicians. Existing automated approaches often fall at two extremes either requiring highly structured inputs, such as predefined entities to generate specific criteria, or relying on end-to-end systems that produce full eligibility criteria from minimal input such as trial descriptions limiting their practical utility. In this work, we propose a guided generation framework that introduces interpretable semantic axes, such as Demographics, Laboratory Parameters, and Behavioral Factors, to steer EC generation. These axes, derived using large language models, offer a middle ground between specificity and usability, enabling clinicians to guide generation without specifying exact entities. In addition, we present a reusable rubric-based evaluation framework that assesses generated criteria along clinically meaningful dimensions. Our results show that our guided generation approach consistently outperforms unguided generation in both automatic, rubric-based and clinician evaluations, offering a practical and interpretable solution for AI-assisted trial design.
Health-SCORE: Towards Scalable Rubrics for Improving Health-LLMs
Jan 26, 2026Rubrics are essential for evaluating open-ended LLM responses, especially in safety-critical domains such as healthcare. However, creating high-quality and domain-specific rubrics typically requires significant human expertise time and development cost, making rubric-based evaluation and training difficult to scale. In this work, we introduce Health-SCORE, a generalizable and scalable rubric-based training and evaluation framework that substantially reduces rubric development costs without sacrificing performance. We show that Health-SCORE provides two practical benefits beyond standalone evaluation: it can be used as a structured reward signal to guide reinforcement learning with safety-aware supervision, and it can be incorporated directly into prompts to improve response quality through in-context learning. Across open-ended healthcare tasks, Health-SCORE achieves evaluation quality comparable to human-created rubrics while significantly lowering development effort, making rubric-based evaluation and training more scalable.
Surpassing GPT-4 Medical Coding with a Two-Stage Approach
Nov 22, 2023



Recent advances in large language models (LLMs) show potential for clinical applications, such as clinical decision support and trial recommendations. However, the GPT-4 LLM predicts an excessive number of ICD codes for medical coding tasks, leading to high recall but low precision. To tackle this challenge, we introduce LLM-codex, a two-stage approach to predict ICD codes that first generates evidence proposals using an LLM and then employs an LSTM-based verification stage. The LSTM learns from both the LLM's high recall and human expert's high precision, using a custom loss function. Our model is the only approach that simultaneously achieves state-of-the-art results in medical coding accuracy, accuracy on rare codes, and sentence-level evidence identification to support coding decisions without training on human-annotated evidence according to experiments on the MIMIC dataset.
Feature Selection for classification of hyperspectral data by minimizing a tight bound on the VC dimension
Sep 27, 2015
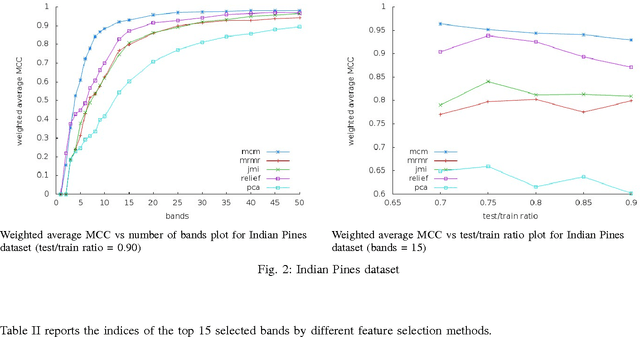

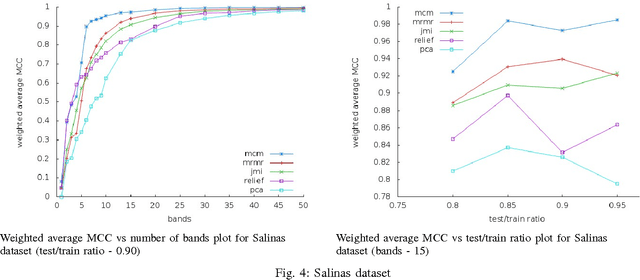
Hyperspectral data consists of large number of features which require sophisticated analysis to be extracted. A popular approach to reduce computational cost, facilitate information representation and accelerate knowledge discovery is to eliminate bands that do not improve the classification and analysis methods being applied. In particular, algorithms that perform band elimination should be designed to take advantage of the specifics of the classification method being used. This paper employs a recently proposed filter-feature-selection algorithm based on minimizing a tight bound on the VC dimension. We have successfully applied this algorithm to determine a reasonable subset of bands without any user-defined stopping criteria on widely used hyperspectral images and demonstrate that this method outperforms state-of-the-art methods in terms of both sparsity of feature set as well as accuracy of classification.\end{abstract}
Learning a Fuzzy Hyperplane Fat Margin Classifier with Minimum VC dimension
Jan 11, 2015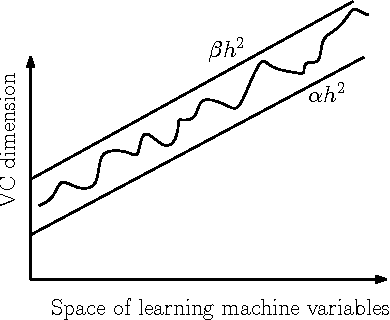

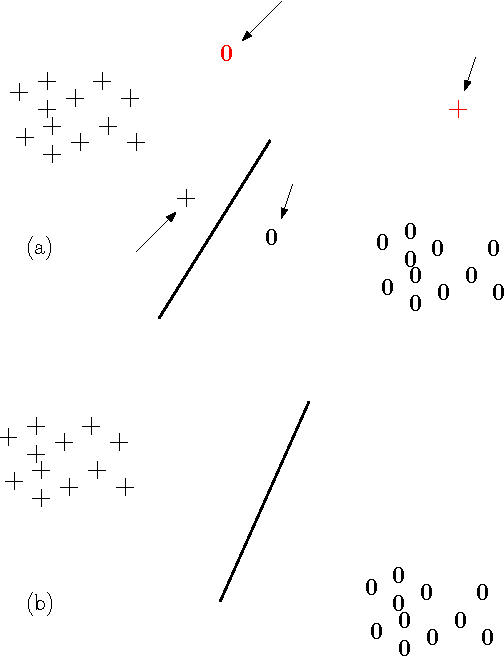

The Vapnik-Chervonenkis (VC) dimension measures the complexity of a learning machine, and a low VC dimension leads to good generalization. The recently proposed Minimal Complexity Machine (MCM) learns a hyperplane classifier by minimizing an exact bound on the VC dimension. This paper extends the MCM classifier to the fuzzy domain. The use of a fuzzy membership is known to reduce the effect of outliers, and to reduce the effect of noise on learning. Experimental results show, that on a number of benchmark datasets, the the fuzzy MCM classifier outperforms SVMs and the conventional MCM in terms of generalization, and that the fuzzy MCM uses fewer support vectors. On several benchmark datasets, the fuzzy MCM classifier yields excellent test set accuracies while using one-tenth the number of support vectors used by SVMs.