 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikingGamma: Surrogate-Gradient Free and Temporally Precise Online Training of Spiking Neural Networks with Smoothed Delays
Feb 02, 2026Neuromorphic hardware implementations of Spiking Neural Networks (SNNs) promise energy-efficient, low-latency AI through sparse, event-driven computation. Yet, training SNNs under fine temporal discretization remains a major challenge, hindering both low-latency responsiveness and the mapping of software-trained SNNs to efficient hardware. In current approaches, spiking neurons are modeled as self-recurrent units, embedded into recurrent networks to maintain state over time, and trained with BPTT or RTRL variants based on surrogate gradients. These methods scale poorly with temporal resolution, while online approximations often exhibit instability for long sequences and tend to fail at capturing temporal patterns precisely. To address these limitations, we develop spiking neurons with internal recursive memory structures that we combine with sigma-delta spike-coding. We show that this SpikingGamma model supports direct error backpropagation without surrogate gradients, can learn fine temporal patterns with minimal spiking in an online manner, and scale feedforward SNNs to complex tasks and benchmarks with competitive accuracy, all while being insensitive to the temporal resolution of the model. Our approach offers both an alternative to current recurrent SNNs trained with surrogate gradients, and a direct route for mapping SNNs to neuromorphic hardware.
Average-Over-Time Spiking Neural Networks for Uncertainty Estimation in Regression
Nov 29, 2024Uncertainty estimation is a standard tool to quantify the reliability of modern deep learning models, and crucial for many real-world applications. However, efficient uncertainty estimation methods for spiking neural networks, particularly for regression models, have been lacking. Here, we introduce two methods that adapt the Average-Over-Time Spiking Neural Network (AOT-SNN) framework to regression tasks, enhancing uncertainty estimation in event-driven models. The first method uses the heteroscedastic Gaussian approach, where SNNs predict both the mean and variance at each time step, thereby generating a conditional probability distribution of the target variable. The second method leverages the Regression-as-Classification (RAC) approach, reformulating regression as a classification problem to facilitate uncertainty estimation. We evaluate our approaches on both a toy dataset and several benchmark datasets, demonstrating that the proposed AOT-SNN models achieve performance comparable to or better than state-of-the-art deep neural network methods, particularly in uncertainty estimation. Our findings highlight the potential of SNNs for uncertainty estimation in regression tasks, providing an efficient and biologically inspired alternative for applications requiring both accuracy and energy efficiency.
DPSNN: Spiking Neural Network for Low-Latency Streaming Speech Enhancement
Aug 14, 2024Speech enhancement (SE) improves communication in noisy environments, affecting areas such as automatic speech recognition, hearing aids, and telecommunications. With these domains typically being power-constrained and event-based while requiring low latency, neuromorphic algorithms in the form of spiking neural networks (SNNs) have great potential. Yet, current effective SNN solutions require a contextual sampling window imposing substantial latency, typically around 32ms, too long for many applications. Inspired by Dual-Path Spiking Neural Networks (DPSNNs) in classical neural networks, we develop a two-phase time-domain streaming SNN framework -- the Dual-Path Spiking Neural Network (DPSNN). In the DPSNN, the first phase uses Spiking Convolutional Neural Networks (SCNNs) to capture global contextual information, while the second phase uses Spiking Recurrent Neural Networks (SRNNs) to focus on frequency-related features. In addition, the regularizer suppresses activation to further enhance energy efficiency of our DPSNNs. Evaluating on the VCTK and Intel DNS Datasets, we demonstrate that our approach achieves the very low latency (approximately 5ms) required for applications like hearing aids, while demonstrating excellent signal-to-noise ratio (SNR), perceptual quality, and energy efficiency.
A Taxonomy of Recurrent Learning Rules
Jul 23, 2022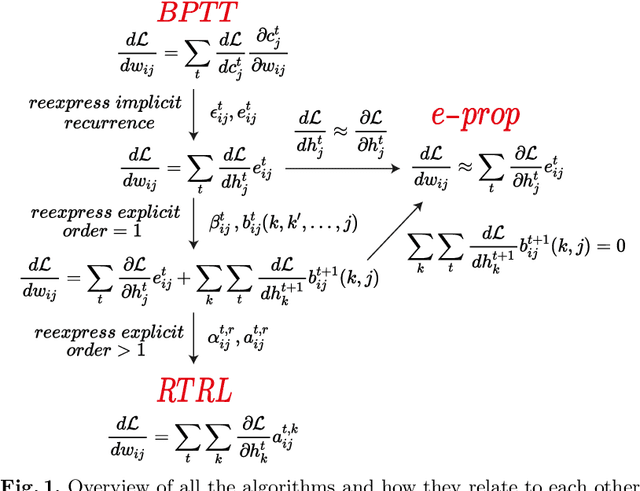
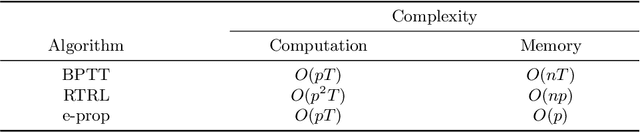
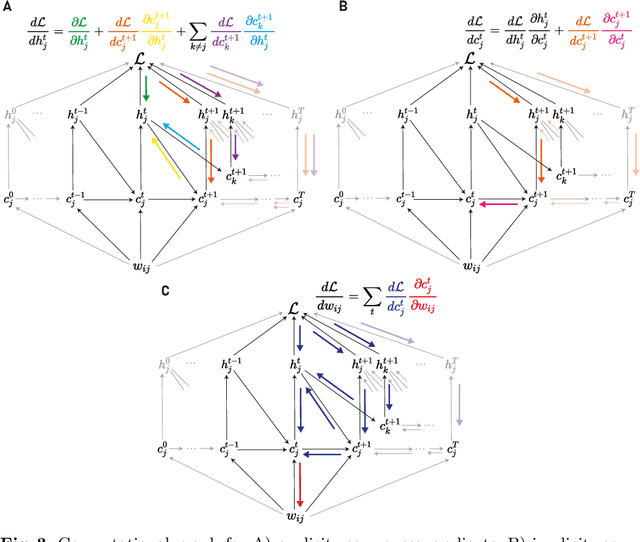
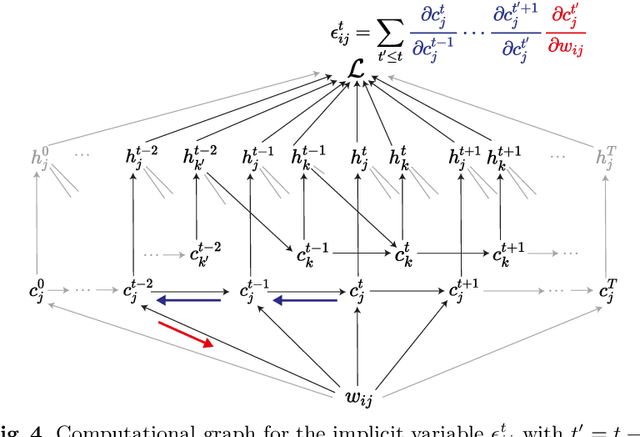
Backpropagation through time (BPTT) is the de facto standard for training recurrent neural networks (RNNs), but it is non-causal and non-local. Real-time recurrent learning is a causal alternative, but it is highly inefficient. Recently, e-prop was proposed as a causal, local, and efficient practical alternative to these algorithms, providing an approximation of the exact gradient by radically pruning the recurrent dependencies carried over time. Here, we derive RTRL from BPTT using a detailed notation bringing intuition and clarification to how they are connected. Furthermore, we frame e-prop within in the picture, formalising what it approximates. Finally, we derive a family of algorithms of which e-prop is a special case.
A Biologically Plausible Learning Rule for Deep Learning in the Brain
Nov 05, 2018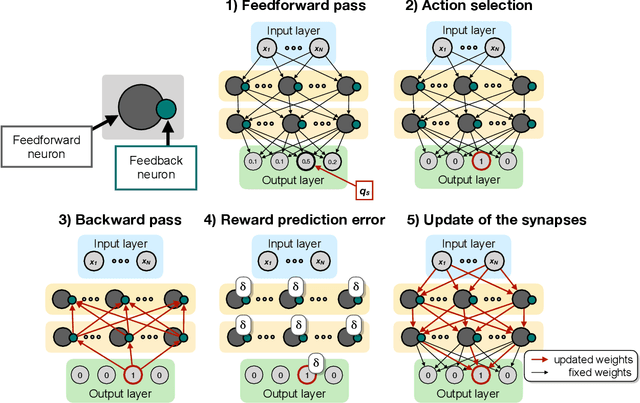
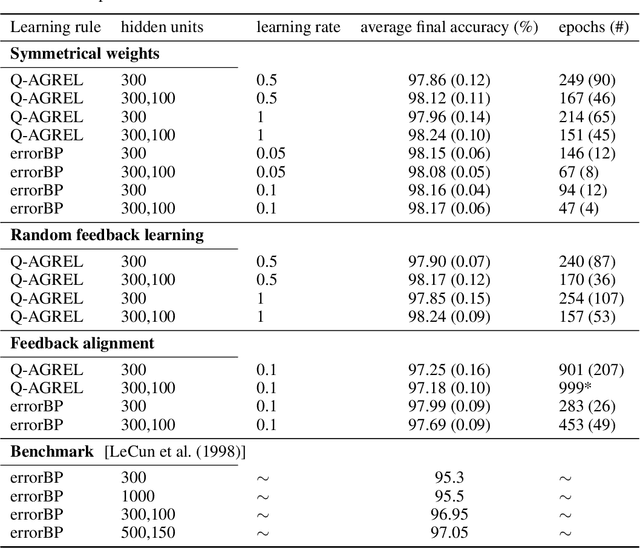
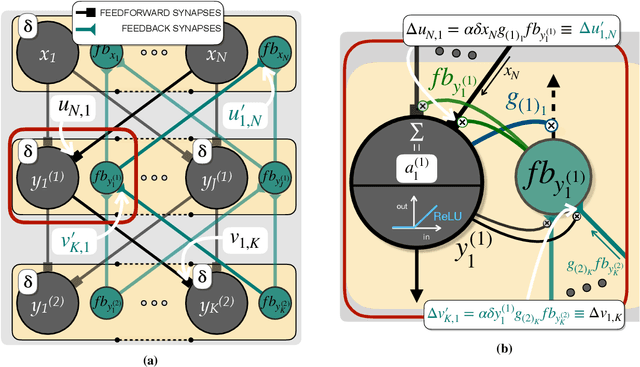
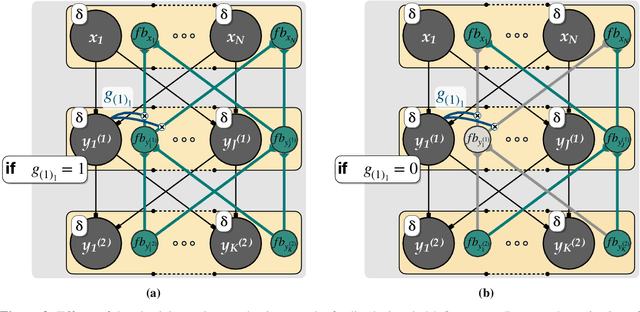
Researchers have proposed that deep learning, which is providing important progress in a wide range of high complexity tasks, might inspire new insights into learning in the brain. However, the methods used for deep learning by artificial neural networks are biologically unrealistic and would need to be replaced by biologically realistic counterparts. Previous biologically plausible reinforcement learning rules, like AGREL and AuGMEnT, showed promising results but focused on shallow networks with three layers. Will these learning rules also generalize to networks with more layers and can they handle tasks of higher complexity? Here, we demonstrate that these learning schemes indeed generalize to deep networks, if we include an attention network that propagates information about the selected action to lower network levels. The resulting learning rule, called Q-AGREL, is equivalent to a particular form of error-backpropagation that trains one output unit at any one time. To demonstrate the utility of the learning scheme for larger problems, we trained networks with two hidden layers on the MNIST dataset, a standard and interesting Machine Learning task. Our results demonstrate that the capability of Q-AGREL is comparable to that of error backpropagation, although the learning rate is 1.5-2 times slower because the network has to learn by trial-and-error and updates the action value of only one output unit at a time. Our results provide new insights into how deep learning can be implemented in the brain.