 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Biologically Plausible Learning Rule for Deep Learning in the Brain
Nov 05, 2018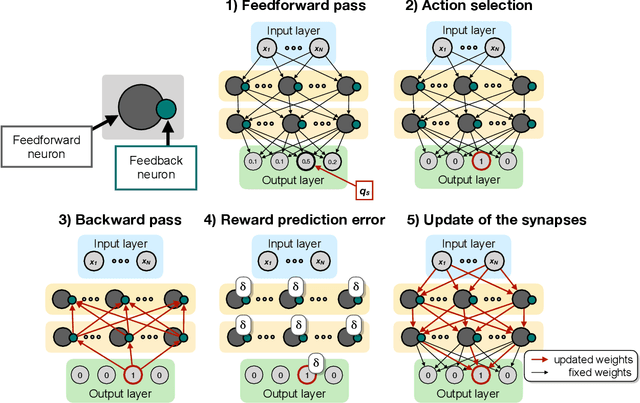
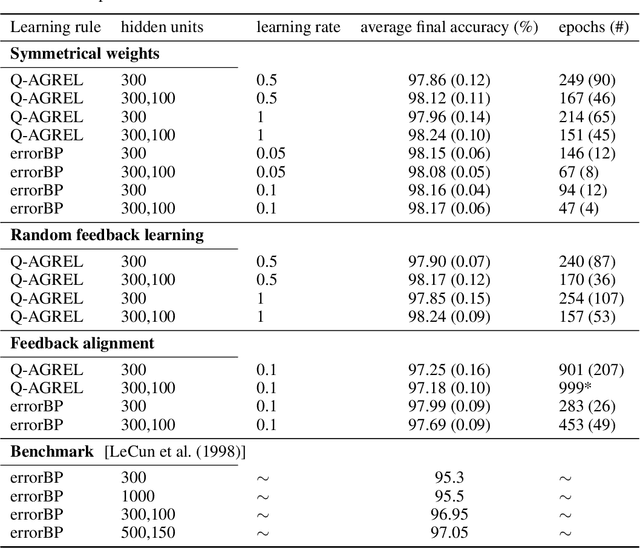
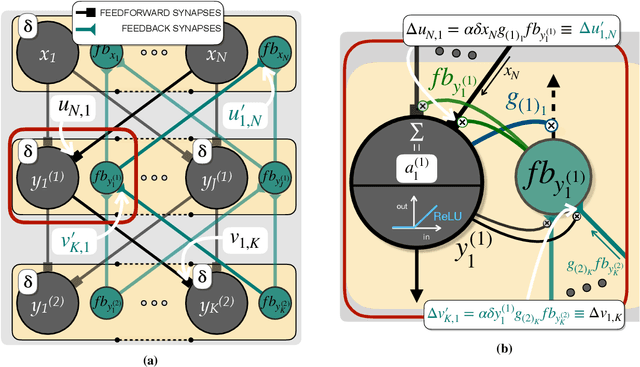
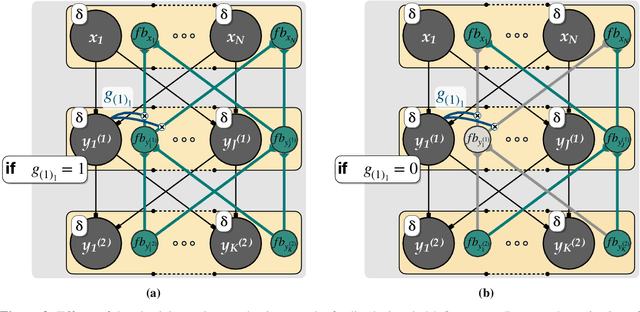
Researchers have proposed that deep learning, which is providing important progress in a wide range of high complexity tasks, might inspire new insights into learning in the brain. However, the methods used for deep learning by artificial neural networks are biologically unrealistic and would need to be replaced by biologically realistic counterparts. Previous biologically plausible reinforcement learning rules, like AGREL and AuGMEnT, showed promising results but focused on shallow networks with three layers. Will these learning rules also generalize to networks with more layers and can they handle tasks of higher complexity? Here, we demonstrate that these learning schemes indeed generalize to deep networks, if we include an attention network that propagates information about the selected action to lower network levels. The resulting learning rule, called Q-AGREL, is equivalent to a particular form of error-backpropagation that trains one output unit at any one time. To demonstrate the utility of the learning scheme for larger problems, we trained networks with two hidden layers on the MNIST dataset, a standard and interesting Machine Learning task. Our results demonstrate that the capability of Q-AGREL is comparable to that of error backpropagation, although the learning rate is 1.5-2 times slower because the network has to learn by trial-and-error and updates the action value of only one output unit at a time. Our results provide new insights into how deep learning can be implemented in the brain.