Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Taxonomy of Recurrent Learning Rules
Paper and Code
Jul 23, 2022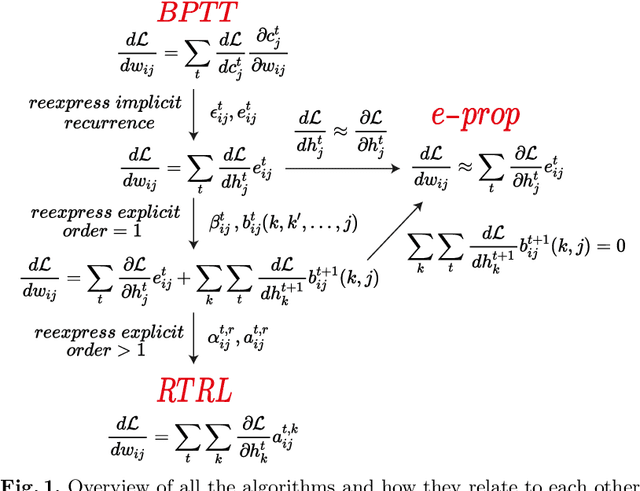
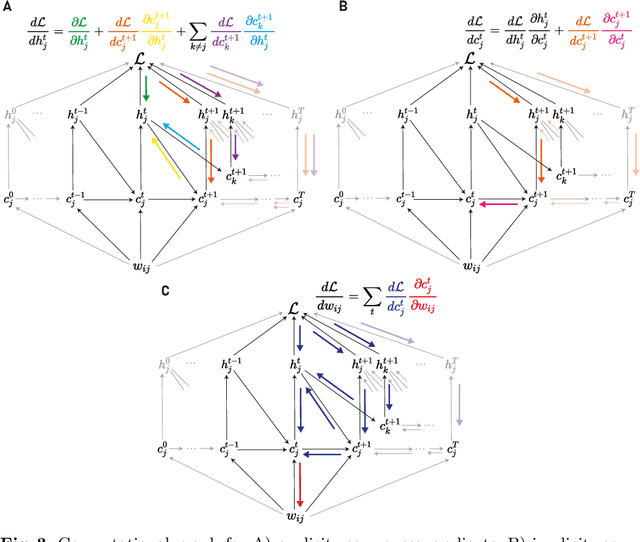
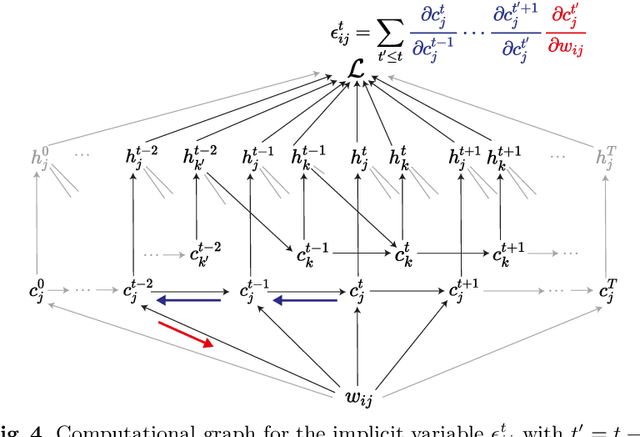
Backpropagation through time (BPTT) is the de facto standard for training recurrent neural networks (RNNs), but it is non-causal and non-local. Real-time recurrent learning is a causal alternative, but it is highly inefficient. Recently, e-prop was proposed as a causal, local, and efficient practical alternative to these algorithms, providing an approximation of the exact gradient by radically pruning the recurrent dependencies carried over time. Here, we derive RTRL from BPTT using a detailed notation bringing intuition and clarification to how they are connected. Furthermore, we frame e-prop within in the picture, formalising what it approximates. Finally, we derive a family of algorithms of which e-prop is a special case.
View paper on