 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEND-M2F: Masked-attention mask transformers for speaker diarization
Jan 23, 2024



In this paper, we make the explicit connection between image segmentation methods and end-to-end diarization methods. From these insights, we propose a novel, fully end-to-end diarization model, EEND-M2F, based on the Mask2Former architecture. Speaker representations are computed in parallel using a stack of transformer decoders, in which irrelevant frames are explicitly masked from the cross attention using predictions from previous layers. EEND-M2F is lightweight, efficient, and truly end-to-end, as it does not require any additional diarization, speaker verification, or segmentation models to run, nor does it require running any clustering algorithms. Our model achieves state-of-the-art performance on several public datasets, such as AMI, AliMeeting and RAMC. Most notably our DER of 16.07% on DIHARD-III is the first major improvement upon the challenge winning system.
Robust End-to-End Diarization with Domain Adaptive Training and Multi-Task Learning
Dec 12, 2023

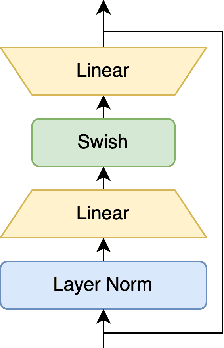

Due to the scarcity of publicly available diarization data, the model performance can be improved by training a single model with data from different domains. In this work, we propose to incorporate domain information to train a single end-to-end diarization model for multiple domains. First, we employ domain adaptive training with parameter-efficient adapters for on-the-fly model reconfiguration. Second, we introduce an auxiliary domain classification task to make the diarization model more domain-aware. For seen domains, the combination of our proposed methods reduces the absolute DER from 17.66% to 16.59% when compared with the baseline. During inference, adapters from ground-truth domains are not available for unseen domains. We demonstrate our model exhibits a stronger generalizability to unseen domains when adapters are removed. For two unseen domains, this improves the DER performance from 39.91% to 23.09% and 25.32% to 18.76% over the baseline, respectively.
Transformer Attractors for Robust and Efficient End-to-End Neural Diarization
Dec 11, 2023End-to-end neural diarization with encoder-decoder based attractors (EEND-EDA) is a method to perform diarization in a single neural network. EDA handles the diarization of a flexible number of speakers by using an LSTM-based encoder-decoder that generates a set of speaker-wise attractors in an autoregressive manner. In this paper, we propose to replace EDA with a transformer-based attractor calculation (TA) module. TA is composed of a Combiner block and a Transformer decoder. The main function of the combiner block is to generate conversational dependent (CD) embeddings by incorporating learned conversational information into a global set of embeddings. These CD embeddings will then serve as the input for the transformer decoder. Results on public datasets show that EEND-TA achieves 2.68% absolute DER improvement over EEND-EDA. EEND-TA inference is 1.28 times faster than that of EEND-EDA.
Improving End-to-End Neural Diarization Using Conversational Summary Representations
Jun 24, 2023Speaker diarization is a task concerned with partitioning an audio recording by speaker identity. End-to-end neural diarization with encoder-decoder based attractor calculation (EEND-EDA) aims to solve this problem by directly outputting diarization results for a flexible number of speakers. Currently, the EDA module responsible for generating speaker-wise attractors is conditioned on zero vectors providing no relevant information to the network. In this work, we extend EEND-EDA by replacing the input zero vectors to the decoder with learned conversational summary representations. The updated EDA module sequentially generates speaker-wise attractors based on utterance-level information. We propose three methods to initialize the summary vector and conduct an investigation into varying input recording lengths. On a range of publicly available test sets, our model achieves an absolute DER performance improvement of 1.90 % when compared to the baseline.
Investigating Deep Neural Structures and their Interpretability in the Domain of Voice Conversion
Feb 22, 2021
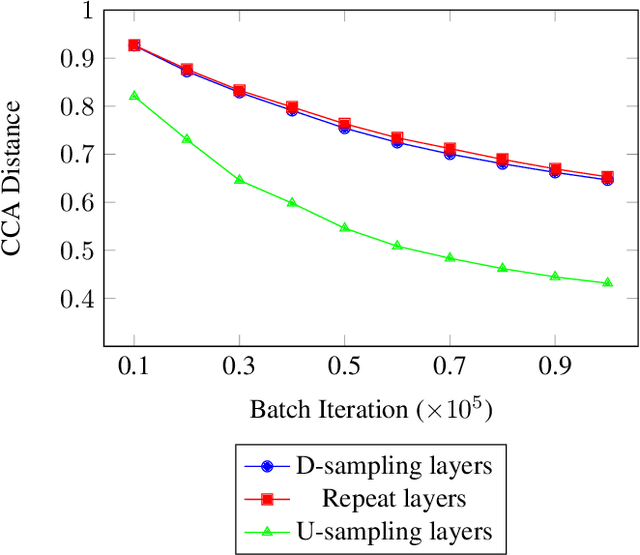


Generative Adversarial Networks (GANs) are machine learning networks based around creating synthetic data. Voice Conversion (VC) is a subset of voice translation that involves translating the paralinguistic features of a source speaker to a target speaker while preserving the linguistic information. The aim of non-parallel conditional GANs for VC is to translate an acoustic speech feature sequence from one domain to another without the use of paired data. In the study reported here, we investigated the interpretability of state-of-the-art implementations of non-parallel GANs in the domain of VC. We show that the learned representations in the repeating layers of a particular GAN architecture remain close to their original random initialised parameters, demonstrating that it is the number of repeating layers that is more responsible for the quality of the output. We also analysed the learned representations of a model trained on one particular dataset when used during transfer learning on another dataset. This showed extremely high levels of similarity across the entire network. Together, these results provide new insight into how the learned representations of deep generative networks change during learning and the importance in the number of layers.